



2. 北京大学遥感与地理信息系统研究所, 北京 100871
2. Institute of Remote Sensing and GIS, Peking University, Beijing 100871, China
机载LiDAR技术作为一种全新的测绘技术,具有快速获取大范围、高密度、高精度的地面信息的优势,已在城市规划、地形制图、自然灾害监测方面得到广泛应用[1-2]。点云分类是激光点云数据后处理的一个重要环节,也是目前摄影测量与遥感领域的重要研究方向之一[3]。在实际的点云分类应用中,受点云的噪声、离散性、密度的不均匀性以及地物形态的多样性等因素的影响,自动化、高精度的点云分类依然面临着巨大挑战。
目前的点云分类方法主要有以下几种解决思路。①将LiDAR点云内插生成高程或者强度影像,然后从图像中提取一些基本的统计特征参数并采用基于像素或者对象的分类方法进行地物分类[4-7]。这种方式虽然能取得较好的效果,但是内插会带来计算误差,而且将三维点云转为二维栅格数据来处理有信息损失。②直接根据点云的三维空间信息选择合适的空间邻域结构,邻域的选择形式包括K近邻、球体邻域、圆柱体邻域或立方体邻域,然后提取反映地物类型差异的几何特征参数,并借助相关的机器学习算法进行分类[8-10]。这种方法的难点在于邻域的确定受空间邻域尺度的影响。对于最佳空间邻域尺度的确定,大多学者是通过反复的尝试或者凭借经验获得,可指导性不强,也有学者尝试采用多尺度的方式解决,但是不加筛选的添加邻域尺度将导致特征维数的急剧增大,给数据处理带来巨大负担。③将点云分类转为多次的目标探测与分离,通过设定一系列的目标识别规则逐步减少分类数量,从而实现点云分类[10-11]。这种方法的不足之处在于误差存在传递与累积,导致分类结果具有很大的不确定性,而且过程比较繁杂,尤其是地物类型比较多的情况。④基于高度纹理的分类方法,该方法先将点云的高程信息内插生成高度影像,然后提取高度纹理特征(如变异系数、二阶矩、熵等)并应用遥感影像分类算法进行分类[10-11]。该方法要求预先设定的地物类别的高度特征存在明显差异,而且对分类地物的先验知识具有较高要求,单独依靠纹理信息进行分类精度不高,需要强度以及几何特征信息的辅助。⑤对全波形机载点云的全波形信息进行分解,然后提取波形特征参数(如回波率、后向散射系数、振幅、波宽等)以及高程特征进行分类[1, 13-15]。该方法对数据源的要求较高,目前通过波形信息来量化地物的空间形态差异还存在很多难点,尤其是植被或者建筑物都具有多回波特征,波形的差异不明显,一般需要结合其他特征参数才能取得比较好的效果[16]。
尽管学者们提出了多种多样的特征参数用于点云分类的研究,但是缺乏对特征参数的选择过程。如果直接将所有的特征参数用于构建分类器,一方面样本数据的特征维度较高导致计算开销大、运算时间长,另一方面无关特征的加入会使得分类器精度下降,而且对不同特征作用于地物分类效果的重要性程度分析不够,导致特征参数与目标地物之间的耦合关系缺乏深刻认识。
本文在前人研究的基础上,提出一种基于随机森林的点云数据降维与分类方法。该方法不需要点云内插,直接以点云数据为核心:首先,通过分析城区目标地物的高度特征、几何特征、回波特征以及强度特征的差异并提取分类特征参数;其次,对于其中依赖于邻域结构的特征参数,本文引入多尺度分析的概念,构建多尺度特征以克服空间邻域尺度选择难的问题;然后,基于随机森林算法进行特征选择和点云分类;最后,从特征选择效果、分类精度以及特征变量的重要性3个方面进行模型效果评价。
1 数据描述研究区域位于芬兰中部城市Jyväskylä(62°14.5′N,25°44.5′E),数据来源于TerraSolid官方网站提供的训练数据(http://www.terrasolid.com/training/training_data.php)。LiDAR数据的获取时间为2011年,借助无人机搭载的激光扫描仪系统在城市上方飞行获得,其中包含7条航带的数据,点云密度平均为17 points/m2。本文选取质量较好且覆盖城市主要设施的点云作为试验数据,其坐标系已由WGS-84椭球投影变换至UTM坐标系,覆盖范围大约为2100×400 m2,包括14 784 484个激光点数据(图 1),原始点云的基本属性包括三维坐标、激光强度、扫描角、回波总数及回波次数等信息。结合点云数据的特点以及区域内地物类型的几何形态差异,本文将研究区内的地物类型分为地面、建筑物与其他3种。

|
| 图 1 试验区获取的LiDAR点云数据 Fig. 1 LiDAR data obtained from the study area |
2 研究方法
本文的试验流程如下:首先对LiDAR点云进行去噪声处理;然后选取训练样本提取多尺度特征参数,构建分类特征集;再采用RFFS算法进行特征选择,并将特征选择得到的结果用于随机森林模型的构建;最后应用于测试集对分类和精度进行评价。
2.1 点云数据去噪由于激光脉冲的折射或者多路径效应,原始点云存在许多噪声点数据,这部分噪声信息可以通过目视加以剔除;另外点云中也存在少量的高程粗差点,通过设置合适的搜索半径阈值R(如0.5 m),然后逐个计算当前搜索点的高程与该点所在半径R内的邻域点的高程平均值的差值,并按照差值不超过3σ原则将粗差点识别出来,最后加以删除。
2.2 特征提取 2.2.1 归一化高度特征基于布料模拟算法[17]对去噪点云构建栅格化的DTM模型,由于试验区域的地形存在较大的起伏,兼顾计算机的运算能力,本文设置布料模拟算法输出的DTM栅格大小为0.8 m,迭代次数为500,布料的硬度系数为2,且进行坡度后处理。点云中的某一点到该点投影所在的DTM栅格内的高程值之差就是该点的归一化高度(normalized height, NH),如图 2所示。该特征在区分地面点和非地面点方面具有很好的效果,如建筑物离地面的高度通常较高且比较有规律,而其他地物的高度特征则比较复杂。

|
| 图 2 归一化高度示意图 Fig. 2 Schematic diagram of normalized height |
2.2.2 高程统计特征
该特征主要表达的是不同地物的高程属性分布特点。假设整个三维点云构成的点集为
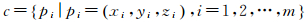
当前计算点为
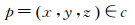
则以该点为中心半径为R的邻域点集可表示为
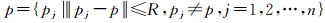
从当前点和邻域点共同构成的点集中通过统计分析提取高程统计量,本文使用的高程统计量包括极差、标准差、峰度和偏度。
(1) 高程极差Hr。高程极差的数学形式为
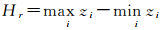 (1)
(1)
(2) 高程标准差HSTD。高程标准差的数学形式为
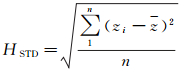 (2)
(2)
(3) 高程峰度Hskw。高程峰度的数学形式为
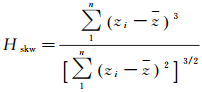 (3)
(3)
(4) 高程偏度Hkur。高程偏度的数学形式为
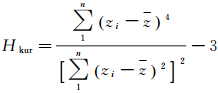 (4)
(4)
式(1)—(4)中,zi是第i个邻域点的高程;z表示当前点和邻域点共同构成的点集的平均高程。
2.2.3 表面相关特征表面相关特征主要体现不同地物在平面上的起伏差异,包括平面粗糙度(N)、平面极差(Sr)、平面标准差(SSTD)、平面法向量与竖直方向的夹角(Sn)。如图 3所示,对当前点和邻域点共同构成的点集用一个平面进行拟合,使得所有点到该平面的距离的平方和最小,计算当前点到该平面的距离即为粗糙度,所有点到该平面的距离的最大差值即为平面极差,所有点到该平面的距离的标准差为平面标准差。通常植被的粗糙度最大,地面次之,建筑物最小;另外地面和建筑物屋顶的平面标准差较小,而植被的平面标准差较大;建筑物屋顶的法向量与竖直方向的夹角比较小且固定,而地面点的变化较大,植被点的变化则非常大。

|
| 图 3 表面相关特征示意图 Fig. 3 Schematic diagram of surface metric feature |
2.2.4 空间分布特征
空间分布特征主要描述当前点在邻域点内服从一维、二维、三维空间分布的程度。首先对当前点和邻域点共同组成的点集的三维坐标进行主成分变换,得到对应于当前点的3个主成分系数μ1、μ2、μ3(μ1≤μ2≤μ3),进一步对这3个主成分系数进行归一化
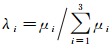 (5)
(5)
式中,λ1、λ2、λ3就对应于当前点在邻域点集内服从一维、二维、三维空间分布的程度。如果λ1→1,则说明当前搜索点与邻域点在空间上呈线状分布特征,如图 4(a)所示;如果λ1与λ2的值可比拟且λ1+λ2→1,则说明当前搜索点与邻域点在空间上呈面状分布特征,如图 4(b)所示;如果λ1与λ2、λ3的值均可比拟,则说明当前搜索点与邻域点在空间上呈体状分布特征,如图 4(c)所示。

|
| 图 4 3种不同的空间分布特征示意图 Fig. 4 Schematic diagram of three different spatial distribution feature |
2.2.5 回波特征
LiDAR的回波信息包括两个方面:回波次数和第几次回波。回波次数特征有单次回波(Ns)及多次回波(Nm);第几次回波特征有首次回波(Nf)、中间回波(Ni)及末次回波(Nl)。地面在无遮挡条件下通常只有一次反射回波,如果受树木的遮挡作用,则由于树木间隙的存在导致部分激光点的末次回波从地面反射回来,因此表现出多次回波的末次回波点一般对应地面点的特征;建筑物一般由钢筋混凝土等坚固材料组成,激光点打在上面不容易发生穿透,因此通常只具有单次回波,但是在建筑物边缘会发生多次反射;植被点由于间隙的存在导致激光点会发生多次反射,第1次回波出现在冠层表面,中间回波出现在树枝以及树叶上,而最后一次回波则一般透过间隙打在地面上(图 5)。依据这个特点,本文提取了地面点回波指数(EGI)、建筑物回波指数(EBI)、植被点回波指数(EVI)。假设当前点和邻域点构成的点集的点数为Nall,则对应回波指数的数学形式为[18]
 (6)
(6)
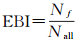 (7)
(7)
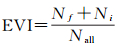 (8)
(8)

|
| 图 5 不同地物类型的回波反射特征 Fig. 5 Schematic diagram of echo reflection feature of different ground object |
2.2.6 强度特征
由于不同的地物类型对特定的激光波长的反射、吸收能力存在差异,因此激光强度信息在地物分类中也具有广泛应用。本文计算当前点和邻域点共同组成的点集内的激光强度的平均值AI作为当前点的平均强度值,并将其作为地物分类的一个特征参数。
2.3 多尺度特征构建本文提取的特征参数除了归一化高度特征不需要考虑邻域结构外,其他均需要。而本文使用的邻域结构是球体邻域,因此受空间邻域尺度的影响。在某个搜索半径R下得到的当前点与邻域点的关系只描述了邻域尺度为R时的空间特征规律,通过不断调整搜索半径R的大小,并分别计算不同邻域尺度下的各个特征参数值,从而得到一系列的多尺度特征参数。结合研究区域内的地物对象大小、异质性特征、空间聚集状况以及激光点的间距大小等因素,初步设定的空间邻域尺度有9个,分别为0.4 m、0.5 m、0.6 m、0.7 m、0.8 m、0.9 m、1.0 m、1.2 m、1.5 m。
2.4 随机森林算法 2.4.1 随机森林算法原理随机森林(random forest, RF)是一种集成学习算法,它可以用于求解多类分类问题。该算法采用Bagging抽样技术,能有效地减少过拟合的风险,而且可以在训练的过程中对变量的重要性进行评估,具有很好的抗噪声、泛化能力[19],其基本组成是分类回归树。该算法进行分类的具体步骤为
(1) 首先基于Bagging抽样技术从训练样本中有放回的随机抽取N个样本数据、有放回的随机抽取M个特征变量构建新的自助样本集,并由此产生T棵分类回归树,而每次未被抽到的样本则组成了T个袋外样本(out-of-bag, OOB)。
(2) 每棵分类回归树的根节点存储对应的自助样本数据,从根节点开始按照最小不纯度原则选择某个特征变量,分裂生成子节点。本文使用的不纯度指标为基尼系数G,计算方法为
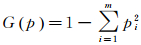 (9)
(9)
式中,m是类别数;pi是第i个类别的样本比例。接着对该特征变量选取合适的分裂点使得分裂前后节点的基尼系数下降量达到最大。假设当前选择的特征变量为f,分裂点为k,则该特征变量分裂前后的基尼系数下降量为
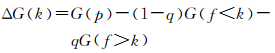 (10)
(10)
式中,G(f < k)表示节点p的f值小于k的样本的基尼系数;q表示节点p的f值小于k的样本所占比例;而G(f>k)表示对节点p的f值大于k的样本的基尼系数。
(3) 每棵树最大限度的递归的选择节点和分裂节点,不做任何裁剪,直至达到最大的分解深度。试验过程中为了加快建树的时间并减少过拟合风险,对每个节点是否分裂添加额外的样本数限制条件,即当某个节点的样本数大于限制阈值nthreshold时,才可以继续分裂。
(4) 将生成的T棵分类回归树组成森林,在测试阶段,每棵分类回归树都对测试样例进行一次投票,最后将得票数最多的类别属性赋给测试样例,从而实现随机森林分类。
参考文献[19]的研究成果并结合训练样本数量较大的特点,本文设置N值为样本总数的90%,M值为特征总个数的平方根,T值为100,分裂节点的样本数nthreshold为10。
2.4.2 基于随机森林的变量重要性度量假设经过Bagging随机抽样后得到了自助样本集S1、S2、…、Sn,对每个自助样本集构建分类回归树Ti(i=1, 2, …, n),然后对袋外数据Bi(i=1, 2, …, n)进行预测,计算对应的分类准确率pi(i=1, 2, …, n)。对于某个特征变量f,在每个袋外数据中对该特征变量的值添加随机噪声得到新的袋外数据B′i,并用Ti再次对B′i预测,计算添加扰动后的分类正确率p′i。特征变量的重要性可通过计算n次模拟后的平均精度下降量来表示[20-21]
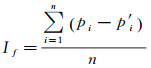 (11)
(11)
如果精度下降量越大,则该特征变量的重要性程度也就越高,为确保结果的稳定性,本文计算平均精度下降量时,控制模拟次数为10次。
2.4.3 基于随机森林的特征选择特征选择的目的是从特征集中识别出关键特征,删除无关特征或者冗余特征信息,从而达到降低特征空间的维数以提高模型的训练速度和学习效果[21-22]。基于随机森林的特征选择(feature selection based on random forest, RFFS)算法,首先利用随机森林算法的特征变量重要性度量对特征集进行排序,然后采用序列后向搜索算法迭代的从当前特征集中删除最不重要(重要性得分最低)的特征,并依次计算每轮迭代过程中的分类准确率,最后选择分类准确率最高的特征子集作为特征选择结果。为了确保训练的模型可靠且稳定,本文采用了K折交叉验证的训练技巧,即每次迭代时将自助样本集随机划分成K份,然后选择其中的K-1份作为训练数据构建随机森林分类器,剩下的1份则作为验证数据用于评估分类效果。在K次交叉验证的过程中,选择验证数据上分类准确率最高的一次所得的变量重要性排序作为删除特征的依据,而该轮迭代的分类准确率则是K次交叉验证的平均分类准确率[21]。由于初始的特征变量数较多,兼顾计算机的处理效率与试验结果的可靠性,本文设置K值为5。
2.5 优化计算的方法由于机载LiDAR点云数据量一般非常大,因而确定点云中某个激光点的邻域点过程是一个非常耗时的空间查询过程,尤其是在多尺度几何特征参数的计算方面。为了提高空间查询的效率,本文采用八叉树结构[23]进行点云数据的存储与空间查询优化。八叉树将三维空间递归的划分为许多规则的体素结构,并对每个体素建立八叉树索引,在邻域搜索时通过定位当前点所在的体素并预估可能与当前点有交集的体素从而减少空间查询范围来提高查询效率。本文为了减少随机森林分类器的训练或者预测时间,在训练或分类之前先对训练与测试样本进行抽稀(空间均匀采样)处理,再利用抽稀后的训练样本构建随机森林模型并对抽稀后的测试样本进行分类,对抽稀后的测试样本分类完成后,去噪点云的类别按照空间最近邻原则由空间距离最近的测试样本点的类别决定,由此实现去噪点云的分类。将测试样本点的类别按照空间最近邻原则赋给去噪点云时,涉及最近邻查询,本文采用KD(K-dimension)树[24-25]来提高最近邻点的搜索效率。
2.6 分类精度评价混淆矩阵是一种常用的分类精度评价方式,其每列数值代表实际类别的点云在各个类别下的数量,每行则代表了模型预测的点云在各个类别下的数量。本文也采用混淆矩阵对点云分类精度进行评定,具体的分类精度评价指标包括:总体精度(OA)以及Kappa系数,对应指标的计算方法为
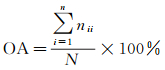 (12)
(12)
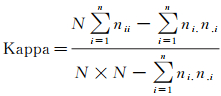 (13)
(13)
式中,N是点云总数;nii代表对角线上的总点数;ni.则表示第i行的总点数;n.i则代表第i列的总点数。
3 结果与分析 3.1 基于随机森林的特征选择图 6表达的是特征子集大小与总体分类精度指标之间的变化关系,试验过程中设置分类回归树的数量T为100,每次随机抽取90%的样本作为自助样本,随机抽取的特征数M为总特征数的平方根,交叉验证的K值为5,初始的特征集大小为127,最小的特征集大小为5。试验表明,随着特征子集中重要性程度较低的特征的剔除,分类器的预测能力整体上逐渐增加,这是由于去除了不相关和冗余的特征使得分类器性能得到提高的缘故。当特征子集大小达到一定数量(本例是26)时,分类器的预测能力达到最大97.0%,继续剔除特征变量则会使得一部分关键特征被当作无用特征剔除使得分类器性能下降导致预测精度降低。

|
| 图 6 特征集大小与分类精度变化关系 Fig. 6 The relationship between overall accuracy and feature set size |
3.2 点云分类结果
经过RFFS特征选择过程得到最优特征子集后,为了加快分类速度,对去噪点云进行抽稀处理(即空间均匀采样,抽样率大约为1%),再将这部分抽稀点云作为核心点数据并从中选择训练样本点和测试样本点。本文最后选取的训练样本点个数为54 395、测试样本点个数为70 976。基于Python语言对训练样本点构建随机森林分类器,并基于该分类器对测试样本进行分类。随后,按照空间最邻近插值原理对去噪点云进行分类,结果如图 7(a)所示。为了说明本文方法的有效性,本文对未经过特征选择而直接使用全部特征构建随机森林分类器也进行试验,除特征变量不同外其他参数设置不变,其结果如图 7(b)所示。另外本文与现有主流的机器学习算法之一:支持向量机(SVM)模型进行比较,试验过程中使用统一的训练样本和测试样本,由于线性SVM模型支持大容量样本的模型训练,因此本文采用线性SVM模型。模型参数是通过反复尝试使得总体精度达到最优来确定的,关键的参数包括penalty值为12,惩罚系数C=1.0,迭代次数为200,其他参数取默认值。同样对特征选择前、后分别进行试验,对应的结果如图 7(c)、(d)所示。总体上看,本文的分类方法对于地面、其他类的分类效果非常好,但是对于建筑物的分类效果较差,尤其是在坡地和建筑物边缘地带(如图 7(a)中的1#和2#);相对于未经过特征选择的分类策略而言,地面点的错分现象更少,而且椒盐现象更轻一些(如图 7(a)、(b)中的3#、4#和5#),而相比于SVM模型而言,这种优势更为明显(如图 7(a)、(b)、(d)中的1#、6#和7#)。

|
| 图 7 不同分类策略下的分类结果 Fig. 7 The classification result of different classification strategies |
3.3 精度评价与效率对比
为定量评价本文提出的方法的分类效果,通过交互式的方式对点云数据进行分类,并将其作为参考数据(图 8),与上述4种分类策略下的分类结果进行比较,得到的误差统计结果如表 1所示。由表 1可见,基于随机森林算法的分类结果特点是:经过特征选择后,目标类别点的漏分率均得到降低,除了建筑物点的错分率有所轻微增加外,其他两类的错分率也都得到降低。另外,建筑物点的漏分率相比于其他类别要高很多,主要原因在于分类器误把一部分建筑物点当做地面点而发生混淆。而基于SVM算法的分类结果特点是:经过特征选择后,地面点的错分率和建筑物点的错分率得到降低,但其他类点的错分率略微增加;另外,其他类点的漏分率得到降低的同时建筑物点的漏分率却在增加,而地面点保持不变。值得注意的是,基于SVM得到的建筑物点的漏分率和错分率要大大高于基于随机森林算法的结果。

|
| 图 8 参考点云分类结果 Fig. 8 The reference classification data |
| (%) | |||||||||||
| 目标 | RF+FS分类 | RF分类 | SVM+FS分类 | SVM分类 | |||||||
| 漏分率 | 错分率 | 漏分率 | 错分率 | 漏分率 | 错分率 | 漏分率 | 错分率 | ||||
| 地面 | 0.8 | 1.8 | 1.1 | 5.0 | 1.8 | 0.9 | 1.8 | 1.5 | |||
| 建筑物 | 22.9 | 9.6 | 28.7 | 9.2 | 28.9 | 16.7 | 27.8 | 18.1 | |||
| 其他 | 2.3 | 6.0 | 2.5 | 6.3 | 4.3 | 9.5 | 5.1 | 8.7 | |||
| 注:RF+FS分类表示经过特征选择后的随机森林算法分类;RF分类表示未经过特征选择直接使用随机森林算法进行分类;SVM+FS分类表示经过特征选择后的SVM算法分类;SVM分类表示未经过特征选择直接使用SVM算法分类。 | |||||||||||
进一步对这4种分类策略下的结果进行精度与效率评比,试验过程使用的是轻便型笔记本电脑(型号:华硕A501;CPU:Intel Core i5-5200U,主频2.19 GHz;内存12 GB),结果如表 2所示。从表 2的结果来看,经过特征选择后的随机森林算法的总体精度相比于未经过特征选择的分类精度提高1.4%,Kappa系数提高0.022;相比于经过特征选择的SVM分类方法而言总体精度提高2.1%,Kappa系数提高0.35;相比于未经过特征选择的SVM分类算法而言,总体精度提高2.3%,Kappa系数提高0.037。这就说明经过特征选择后分类精度确实能得到提升,但是提升幅度较小,并且基于集成的学习算法的学习能力比SVM更强,但是由于本文使用的最优特征子集是通过RFFS算法得到的,该特征子集的优势是使得随机森林算法的分类精度达到最大,但是该特征子集并不一定适用于SVM模型,因此运用到SVM模型后没有明显的精度提升。另外,从运行效率方面来看,经过特征选择后,不管是随机森林算法还是SVM算法,其模型训练时间以及模型测试时间均得到大幅度降低,能满足某些实时性要求高的应用需要。
| 参数 | RF+FS 分类 |
RF 分类 |
SVM+FS 分类 |
SVM 分类 |
| OA/(%) | 94.3 | 92.9 | 92.2 | 92.0 |
| Kappa | 0.922 | 0.900 | 0.887 | 0.885 |
| 模型训练时间/s | 10.70 | 27.46 | 8.45 | 52.37 |
| 模型测试时间/s | 1.07 | 1.82 | 0.04 | 0.16 |
| 注:RF+FS分类表示经过特征选择后的随机森林算法分类;RF分类表示未经过特征选择直接使用随机森林算法进行分类;SVM+FS分类表示经过特征选择后的SVM算法分类;SVM分类表示未经过特征选择直接使用SVM算法分类。 | ||||
3.4 特征重要性比较
图 9是通过袋外样本计算得到的特征重要性结果(各个特征的得分值经过标准化处理,最重要的特征得分设为100)。由图 9可知,归一化的高度NH的重要性程度最高,这是因为归一化高度则能有效地将地面点和非地面点进行分离,并且建筑物点的归一化高度特征相对其他类点来说更明显。另外,回波指数在分类过程中也起到了关键作用,这是因为地面不存在间隙,因此单次回波(或首次回波)占据主要的比例,其比例也就最高,其次是建筑物,最低的则是植被,因为植被具有缝隙容易发生多次透射,而建筑物只在边缘处发生透射,导致回波特征有较大差异。另外激光强度AI、法向量与竖直方向的夹角Sn以及空间分布特征λ2对点云分类也发挥了重要作用。相比较而言,高程统计量在本次试验中的分类作用则不明显,主要是复杂的地形条件下点云的高程特征差异性并未得到突显。

|
| 图 9 特征重要性得分结果 Fig. 9 Feature importance score results |
进一步考察空间邻域尺度的利用情况,通过对各个邻域尺度下的特征数量进行统计,其结果如表 3所示。容易看出,随着邻域尺度的增大,有效得到利用的特征数量也在增加,这表明在较大的尺度下这3种地物类型的特征差异得到突出;另外,在较大的邻域尺度下,高程统计量、空间分布特征和建筑物回波指数才开始出现作用;激光强度特征、法向量夹角和地面点回波指数则在所有的空间邻域尺度下均发挥作用。
| 邻域尺度/m | 特征列表 | 特征个数 |
| 0.7 | AI、Sn、EGI | 3 |
| 0.8 | AI、Sn、EGI | 3 |
| 0.9 | AI、Sn、EGI | 3 |
| 1.0 | AI、Sn、EGI | 3 |
| 1.2 | AI、Sn、SSTD、EBI、EGI | 5 |
| 1.5 | AI、Hkrt、HSTD、λ2、Sn、SSTD、EBI、EGI | 8 |
4 讨论与结论
本文以机载LiDAR数据为研究对象,通过分析点云数据的特点提取了高度统计量、归一化高度、表面相关特征、空间分布特征、回波特征和激光强度特征6大类特征参数,并在此基础上构建多尺度特征参数,采用随机森林分类算法进行数据降维,得到最优特征子集后再对点云进行分类。试验过程中得到了以下几点结论:
(1) 多尺度特征参数的构建不仅有效克服了邻域结构设计时最佳空间尺度的选择难问题,并且为点云分类增加了更多的特征参数,但是并非所有多尺度特征参数都对分类变量起到重要作用,其中有许多特征参数之间存在相关性和冗余,因此在进行点云分类前需要对特征变量进行降维。这一方面可以减少模型的训练时间,另一方面可以提高分类器的预测能力。RFFS特征选择算法不仅能快速剔除相关和冗余特征,且该算法以分类精度最大化为目标,能有效地寻找到分类预测能力最优的特征子集。本文基于该方法将原始特征集大小由127下降为26,不仅使得模型训练和预测的时间大大缩短,并且使得最终的分类精度提高1.4%。
(2) 本文的分类方法在地形条件复杂区域和地物边缘处会产生较大的错分误差。总体上来看,本文的分类方法对地面点和其他类点的识别能力很强,对建筑物点的识别能力稍弱。随机森林模型建立过程中由于采用Bagging抽样技术,使得模型对异常值和噪声有较好的容忍度,并且不容易出现过拟合。与传统的SVM分类算法进行比较发现,基于随机森林算法的分类总体精度和Kappa系数均要优于SVM,体现了集成学习算法的优势。
(3) 本文的特征重要性分析结果表明,归一化高度在城市地区的点云分类中起到了核心作用,另外回波指数、激光强度、表面特征和空间分布特征对点云分类也起到了重要作用,高程统计量特征发挥的作用则较小。结合空间尺度的利用率来看,随着邻域尺度的增大,特征的利用率也在逐渐提高,并且激光强度特征和地面点回波指数在各个尺度均发挥作用。
城市地物类型除了空间形态和回波特征等差异外,还有光谱信息、纹理信息等方面的差异,如果能将光谱特征和纹理特征引入到分类中,点云的分类精度有可能得到进一步提高,并为精细的地物类型分类提供支持。随着无人机LiDAR技术的发展,集成光学或高光谱传感器的无人机系统将逐步普及,未来将探索融合无人机影像与LiDAR的点云分类方法。
| [1] |
范士俊, 张爱武, 胡少兴, 等.
基于随机森林的机载激光全波形点云数据分类方法[J]. 中国激光, 2013, 40(9): 0914001.
FAN Shijun, ZHANG Aiwu, HU Shaoxing, et al. A Method of Classification for Airborne Full Waveform LiDAR Data Based on Random Forest[J]. Chinese Journal of Lasers, 2013, 40(9): 0914001. |
| [2] | YAN W Y, SHAKER A, EL-ASHMAWY N. Urban Land Cover Classification Using Airborne LiDAR Data:A Review[J]. Remote Sensing of Environment, 2015, 158(3): 295–310. |
| [3] |
徐宏根, 王建超, 郑雄伟, 等.
面向对象的植被与建筑物重叠区域的点云分类方法[J]. 国土资源遥感, 2012, 24(2): 23–27.
XU Honggen, WANG Jianchao, ZHENG Xiongwei, et al. Object-based Point Clouds Classification of the Vegetation and Building Overlapped Area[J]. Remote Sensing for Land & Resources, 2012, 24(2): 23–27. |
| [4] |
李峰, 崔希民, 刘小阳, 等.
机载LiDAR点云提取城市道路网的半自动方法[J]. 测绘科学, 2015, 40(2): 88–92.
LI Feng, CUI Ximin, LIU Xiaoyang, et al. A Semi-automatic Algorithm of Extracting Urban Road Networks from Airborne LiDAR Point Clouds[J]. Science of Surveying and Mapping, 2015, 40(2): 88–92. |
| [5] | ANTONARAKIS A S, RICHARDS K S, BRASINGTON J. Object-based Land Cover Classification Using Airborne LiDAR[J]. Remote Sensing of Environment, 2008, 112(6): 2988–2998. DOI:10.1016/j.rse.2008.02.004 |
| [6] | IM J, JENSEN J R, HODGSON M E. Object-based Land Cover Classification Using High-posting-density LiDAR Data[J]. GIScience & Remote Sensing, 2008, 45(2): 209–228. |
| [7] | ZHOU Weiqi. An Object-based Approach for Urban Land Cover Classification:Integrating LiDAR Height and Intensity Data[J]. IEEE Geoscience and Remote Sensing Letters, 2013, 10(4): 928–931. DOI:10.1109/LGRS.2013.2251453 |
| [8] |
郭波, 黄先锋, 张帆, 等.
顾及空间上下文关系的JointBoost点云分类及特征降维[J]. 测绘学报, 2013, 42(5): 715–721.
GUO Bo, HUANG Xianfeng, ZHANG Fan, et al. Points Cloud Classification Using JointBoost Combined with Contextual Information for Feature Reduction[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(5): 715–721. |
| [9] |
岳冲, 刘昌军, 王晓芳.
基于多尺度维度特征和SVM的高陡边坡点云数据分类算法研究[J]. 武汉大学学报(信息科学版), 2016, 41(7): 882–888.
YUE Chong, LIU Changjun, WANG Xiaofang. Classification Algorithm for Laser Point Clouds of High-steep Slopes Based on Multi-scale Dimensionality Features and SVM[J]. Geomatics and Information Science of Wuhan University, 2016, 41(7): 882–888. |
| [10] | BRODU N, LAGUE D. 3D Terrestrial LiDAR Data Classification of Complex Natural Scenes Using a Multi-scale Dimensionality Criterion:Applications in Geomorphology[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2012, 68(1): 121–134. |
| [11] | ZHAO Jiaping, YOU Suya. Road Network Extraction from Airborne LiDAR Data Using Scene Context[C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence, RI, USA: IEEE, 2012: 9-16. |
| [12] |
乔纪纲, 刘小平, 张亦汉.
基于LiDAR高度纹理和神经网络的地物分类[J]. 遥感学报, 2011, 15(3): 539–553.
QIAO Jigang, LIU Xiaoping, ZHANG Yihan. Land Cover Classification Using LiDAR Height Texture and ANNs[J]. Journal of Remote Sensing, 2011, 15(3): 539–553. |
| [13] | NIEMEYER J, WEGNER J D, MALLET C, et al. Conditional Random Fields for Urban Scene Classification with Full Waveform LiDAR Data[C]//Proceedings of 2011 ISPRS Conference on Photogrammetric Image Analysis. Munich, Germany: Springer, 2011: 233-244. |
| [14] | AZADBAKHT M, FRASER C S, KHOSHELHAM K. Improved Urban Scene Classification Using Full-waveform LiDAR[J]. Photogrammetric Engineering & Remote Sensing, 2016, 82(12): 973–980. |
| [15] | CHU H J, WANG C K, KONG S J, et al. Integration of Full-waveform LiDAR and Hyperspectral Data to Enhance Tea and Areca Classification[J]. GIScience & Remote Sensing, 2016, 53(4): 542–559. |
| [16] | MALLET C, BRETAR F. Full-waveform Topographic LiDAR:State-of-the-art[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2009, 64(1): 1–16. DOI:10.1016/j.isprsjprs.2008.09.007 |
| [17] | ZHANG Wuming, QI Jianbo, WAN Peng, et al. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation[J]. Remote Sensing, 2016, 8(6): 501. DOI:10.3390/rs8060501 |
| [18] | KIM H B, SOHN G. 3D Classification of Power-line Scene from Airborne Laser Scanning Data Using Random Forests[J]. International Archives of Photogrammetry and Remote Sensing, 2010, 38(3A): 126–132. |
| [19] | BREIMAN L. Random Forests[J]. Machine Learning, 2001, 45(1): 5–32. DOI:10.1023/A:1010933404324 |
| [20] |
孙杰, 赖祖龙.
利用随机森林的城区机载LiDAR数据特征选择与分类[J]. 武汉大学学报(信息科学版), 2014, 39(11): 1310–1313.
SUN Jie, LAI Zulong. Airborne LiDAR Feature Selection for Urban Classification Using Random Forests[J]. Geomatics and Information Science of Wuhan University, 2014, 39(11): 1310–1313. |
| [21] |
姚登举, 杨静, 詹晓娟.
基于随机森林的特征选择算法[J]. 吉林大学学报(工学版), 2014, 44(1): 137–141.
YAO Dengju, YANG Jing, ZHAN Xiaojuan. Feature Selection Algorithm Based on Random Forest[J]. Journal of Jilin University (Engineering and Technology Edition), 2014, 44(1): 137–141. |
| [22] | THANGAVEL K, PETHALAKSHMI A. Dimensionality Reduction Based on Rough Set Theory:A Review[J]. Applied Soft Computing, 2009, 9(1): 1–12. DOI:10.1016/j.asoc.2008.05.006 |
| [23] | VO A V, TRUONG-HONG L, LAEFER D F, et al. Octree-based Region Growing for Point Cloud Segmentation[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 104(1): 88–100. |
| [24] | ZHANG Kun, QIAO Shiquan, GAO Kai. A New Point Cloud Reconstruction Algorithm Based-on Geometrical Features[C]//Proceedings of the 7th International Conference on Modelling, Identification and Control. Sousse, Tunisia: IEEE, 2015: 1-6. |
| [25] | BENTLEY J L. Multidimensional Binary Search Trees Used for Associative Searching[J]. Communications of the ACM, 1975, 18(9): 509–517. DOI:10.1145/361002.361007 |