



OSM(open street map)作为大型的公开地图数据库,是地理信息情报(特别是境外地理信息数据)收集的重要数据源。在对该来源数据进行处理和建立多尺度模型时需要对其进行一定程度的制图综合。在大比例尺交通要素制图综合中,立交桥的分类是典型化的重要依据,并且能够为导航和位置服务、拥堵分析等提供重要信息。然而由于立交桥结构复杂,变化多样,往往属于同一类型的立交桥其辅路的形态也不完全相同,且和人行道相互交错,对分类模型的构建造成不小挑战。如何让计算机能够对复杂多变的交叉路口进行准确地分类一直是研究的难点。
当前针对立交桥的识别方法主要有:文献[1]提出一种利用道路节点密度对立交桥进行非结构化的定位方法,然而该方法仅限于定位,无法对立交桥所属类型进行判断;文献[2]提出一种基于结构模式识别的立交桥判别方法,该方法利用有向属性关系图来描述道路交叉口结构,建立典型结构模板库,然后通过关系图匹配识别典型交叉口;文献[3]提出了一种改进的结构模式识别方法,该方法利用道路拓扑特征分类对立交桥进行描述,建立典型量化表达式模板库,通过对比量化表达式识别立交桥类型;文献[4]对以往的结构描述方式进行了丰富,采用长度、面积、紧凑度、平行度、对称度和语义属性6个参数组成立交桥的特征空间,利用支持向量机(support vector machine,SVM)结合样本进行训练,并将训练好的模型用于主路和辅路的识别,不过该方法并未对立交桥进行分类,而只是识别了主路和辅路。
以上的方法均属于基于人工设计特征的识别方法,将矢量的立交桥点、线结构通过空间计算,映射到一个特征描述空间中,然后进行识别和分类。这类方法十分依赖于特征项的设计(例如长度、对称度、弯曲度等),这种浅层特征只对典型化的立交桥数据能够比较有效地识别,如图 1(a)所示。然而,现实中所处理的立交桥数据往往并不是以理想状态呈现的,存在大量干扰,因此很难用浅层次的模型进行类型描述,从而在传统手段下无法进行有效的分类判断。在来自OSM开放城市数据中,立交桥本身属性信息不全,且往往伴随着各种辅路、交叉路、人行道等(如图 1(b)所示),严重影响基于人工特征描述模型的判断。

|
| 图 1 模型与现实数据对比 Fig. 1 Comparison between model and real data |
人对于立交桥的认知是基于视觉的模糊判断过程,能自动过滤掉无关信息,从整体和局部中提取深层次模糊性特征,从而辨别出大量干扰下的立交桥类型。模拟人类的视觉感知过程是机器视觉(computer vision,CV)领域研究的热点问题之一。在机器视觉领域,卷积神经网络(convolutional neural network,CNN)已经逐渐取代以往的模式识别方法,并成功应用于手写字识别、人脸识别和遥感影像分类等领域,取得了令人瞩目的成就[5-8]。受到这些成功案例的启发,本文将卷积神经网络引入到立交桥的识别中,以解决在大比例尺复杂情况下立交桥的识别问题。
基本思路为:首先,利用矢量特征进行定位,通过自动抓取图像以及人工标注得到训练样本;然后,利用样本对卷积神经网络进行训练,学习立交桥的深层次模糊性特征,从而得到立交桥分类的CNN模型;最后通过CNN模型对新抓取的立交桥对象进行分类,并将分类的结果反馈到相应的矢量数据中去。
1 卷积神经网络的概念及应用策略 1.1 卷积神经网络在图像分类领域的应用传统的图像物体检测和分类的关键在于特征表达,而特征设计需要具有较高专业素养的专家手工完成,这种方式投入精力大、时间成本高,虽然应用广泛,但并不是一个可拓展的途径[9]。
基于神经网络的图像识别不需要人工进行特征设计,直接由计算机通过读取栅格图像进行训练,收敛得到各层神经元对应的参数值,这些参数即反映了区分图像类型的深层次特征。然而构建深度神经网络模型的难点在于其训练过程,深度越深模型的参数规模越大越不容易收敛。近年来深度神经网络在机器视觉领域得以有效的应用,归功于卷积神经网络的提出[10-12]。CNN继承了传统误差反向传播(back-propagation,BP)神经网络的优点,采取权值共享的方式,加入了卷积层和池化层,减少了权重参数的个数,不仅很好地控制了整个网络的规模,而且对图像在位移、缩放和扭曲等形变的识别上具备很强的鲁棒性[13-15]。
众多学者针对图像分类提出了大量的卷积神经网络模型,例如文献[16]针对手写数字识别提出的LeNet模型,被广泛应用于银行手写数字的识别系统;文献[17]将CNN进行了深度的拓展提出了AlexNet模型(如图 2所示)。该模型在“大规模视觉识别挑战赛”(ImageNet Large Scale Visual Recognition Challenge,ILSVR)中获得了第一,并将错误率降低了十个百分点,从此奠定了卷积神经网络在计算机视觉中的地位。

|
| 图 2 AlexNet卷积神经网络模型结构图 Fig. 2 Structure of AlexNet |
1.2 基于CNN的栅矢结合立交桥识别策略
一直以来立交桥识别问题都是围绕矢量数据,通过建立各种几何、拓扑、图论等精确模型来寻求解决方案。在大比例尺数据中,立交桥局部结构复杂多变且存在辅路和人行道干扰,视觉上只能找到模糊的区别,很难用规整的语言去形容,更别谈设计模板来提取特征了。要想解决对视觉感受依赖较强的综合问题,引入机器视觉的方法无疑是一个值得研究的思路。
因此本文提出基于CNN的栅矢结合立交桥识别方法,在立交桥的识别中,分别发挥矢量计算和栅格图像识别的优势。传统矢量数据计算的优势在于,模型精确可控、执行简单、处理速度快,善于处理结构化、可线性描述的问题[18-20]。基于栅格图像的机器视觉算法的优势在于,通过大量样本数据的训练,能够提取不同类别的深层次特征进行分类学习。由于CNN中深层次特征由神经网络各个神经元参数在样本数据训练下得到,在大量神经元结构相互影响下,使其具有类似人类判断过程中的模糊性和抗干扰性。简而言之,在立交桥结构识别过程中,将对视觉依赖性较强的分类环节交给基于卷积神经网络的机器学习模型,学习深层次的模糊性分类特征,结合矢量结构特征的快速定位,实现图上立交桥的识别和分类。
具体流程如图 3所示。首先,通过矢量计算,定位到待分类的交叉路口得到采样图像;其次,经人工分类的样本作为训练集和测试集,对卷积神经网络进行训练,得到分类模型;然后,在处理实际数据中,利用矢量计算初步定位的粗筛作用,得到待识别数据;最后,待识别数据通过训练好的CNN分类模型进行分类,得到分类结果,并最终将分类结果反馈到OSM矢量数据中。

|
| 图 3 采用卷积神经网络的立交桥识别流程图 Fig. 3 The interchange classification process by using CNN |
2 立交桥初步定位以及样本获取
人的视觉感受范围是模糊的,而CNN处理的是固定输入维数的数据,即固定大小的图像。其能够感受的范围是与训练时所采用的样本数据大小相一致。因此利用计算机视觉进行模型训练之前,需要给定一个计算机的视觉范围,即告诉计算机“往哪看”。在基于卷积神经网络的人脸识别的过程中,由于预先不知道人脸在图像中的位置,采取的是以一定的步长将整个图像划分成众多的矩形图块,然后逐行从图块中识别出人脸。对于空间跨度大的地图数据而言,通过这样全局扫描式的方法识别一幅地图中的元素显然会严重影响识别的效率。
因此本文提出利用矢量计算对视觉区域进行初步定位,同时设计合理的视觉感受范围和感受尺度,从而提高样本获取的效率和质量,提升识别判断过程的效率。
2.1 视觉区域定位本文认为道路交叉路口都是潜在的立交桥目标。因此,在进行训练样本收集,以及最后立交桥识别前,利用矢量数据的空间计算,得到道路交叉结点密集的位置,达到对立交桥进行初步筛选和定位的目的。具体步骤如下:
步骤1:获取所有道路的交叉结点数据。
步骤2:对交叉点进行缓冲区聚类,初步识别存在一定规模(交叉点数大于某一阈值)的交叉结点群。
步骤3:计算点群中心点,作为采样栅格区域矩形的中心位置,如图 4所示。

|
| 图 4 自动确定采样中心点示例 Fig. 4 Automate locate sample center point |
2.2 采样参数的确定
CNN的学习过程与人视觉神经对物体的感知过程的原理是类似的。因此,想要通过样本训练获得正确的分类模型,就必须使采集的样本符合人对立交桥的一般性认知规律,即采样的栅格样本在视觉上具有很好的可辨认性。为了得到完整、清晰的立交桥样本,除了确定采样矩形的位置,还需要确定采样范围、样本尺寸和符号大小这3个参数。
2.2.1 采样数据范围的确定采样范围可以理解为计算机的视觉感受范围,即图 4中虚线矩形框的大小。采样范围关系到样本数据的质量,若采样区域过大,则易过多地将非立交桥元素包含到样本图像中,对模型的训练精度产生干扰,如图 5(a)所示。若采样区域过小,则容易造成“盲人摸象”,导致以偏概全,以至于成为影响模型训练精度的噪声数据。如图 5(d)、(e)所示,由于该采样区域过小,立交桥的形态不完整,无法满足在视觉上进行分类的判断条件。

|
| 图 5 不同采样范围样本示例 Fig. 5 Samples of different scopes |
现实中的立交桥,其跨度在一定范围内变化。本文对立交桥汇入点间的距离进行了统计,得出除部分特大型立交桥外,立交桥结构的跨度一般在300 m到600 m之间。为了保证样本中立交桥结构的完整性,本文取立交桥跨度规模区间的上限值作为采样区域的范围值,即将采样区域对应的实地范围设定为600×600 m2。
2.2.2 样本图像尺寸的确定在采样范围确定的情况下,样本图像尺寸影响样本内容表达以及样本数据量。若样本尺寸太小,则“马赛克”现象严重,无法清晰表达采样范围内立交桥的形态特征;样本尺寸太大,则对应的神经网络模型也就越大,占用的计算资源也就越多,影响学习效率。本文综合比对了多种图像尺寸下的立交桥形态,参考常见图像分类中的采样策略,将立交桥样本采样尺寸设定为250×250像素,jpg格式图片。如图 6所示,为各种采样尺寸下图形显示效果对比。

|
| 图 6 不同采样尺寸样本示例 Fig. 6 Samples of different sizes |
2.2.3 采样符号大小的确定
计算机在自动采样过程中,需要预先设定好线状矢量道路的符号大小,即符号宽度,以得到可辨认的立交桥形态,如图 7所示。

|
| 图 7 不同道路像素宽度的样本示例 Fig. 7 Samples of different road widths |
不同分辨率和符号宽度下得到的样本,其显示的道路像素宽度也不同。若道路像素宽度太大,则会出现道路符号重叠,影响立交桥形态的表达;若像素宽度太小,则道路网形态过于精细,不利于卷积过程对特征的提取。因此本文选择图 7(c)对应的符号宽度参数3像素,即3个像素点宽度,作为本文立交桥采样的标准。各采样样本相关参数如表 1所示。
| 参数名称 | 参数值 |
| 采样尺寸(size) | 250×250(像素) |
| 符号宽度(symbol width) | 3(像素) |
| 采样范围(sample range) | 600×600 m2 |
根据以上采样范围、样本尺寸和符号大小这3个参数,可以确定采样栅格图形的一般形态。以上3个参数一经设定,则无需再进行修改,通用于整个立交桥数据的采样以及识别过程。
2.3 样本数据筛选和增量操作 2.3.1 训练样本数据筛选本文选取了北京、上海、广州3个城市的OSM交通数据作为训练样本的采样源,如图 8所示。为进一步减少数据量,对图像进行二值化处理。在自动生成了大量样本图像后,需要对样本数据进行人工筛选和标记。标记的样本数据分为训练集和测试集,用于训练立交桥识别和分类的卷积神经网络。

|
| 图 8 基于OSM数据的样本数据部分采样和二值化示意图 Fig. 8 Sampling form the OSM data and binaryzation process |
CNN的深度学习过程类似于人类视觉感受和学习过程,通过训练能够对样本的分类特征进行模糊感知。样本在筛选时,只需要保证选用的样本数据能够反映其类型,满足人对立交桥的一般认知即可。
2.3.2 样本数据增量对于神经网络的训练而言,样本数量越多,训练得到的模型越精确。因此扩大样本的规模是提高训练精度的一个重要方面。除了通过加大采集量得到更多样本这一手段外,还可以利用样本自身特点产生新的样本,也就是根据研究对象的特点设计各种数据增强方法(data augmentation)。
由于立交桥具有方向不变性,立交桥方位的变化不影响立交桥的分类。因此,本文利用这一特性对立交桥样本数据进行旋转和镜像操作,以扩大样本规模。如图 9所示,通过该处理过程样本数量增加了7倍,有效地扩大了样本规模,提升了样本覆盖度。

|
| 图 9 样本数据增强操作示意图 Fig. 9 Data augmentation process |
3 采用AlexNet对立交桥样本进行分类模型训练
模型的好坏并不绝对,往往要结合具体问题以及样本数据的特点进行选择。当前对于样本数据应该选用哪种深度神经网络模型没有一套明确的评价标准。考虑到立交桥的结构相较于手写数字更为复杂,本文选择用于大规模图像分类的AlexNet网络模型作为训练模型,并在Caffe(convolutional architecture for fast feature embedding)提供的框架下进行训练。Caffe发布于2014年,是一个清晰、高效的开源深度学习框架,核心语言是C++,它支持命令行、Python和Matlab接口,支持GPU运行。
3.1 卷积神经网络的计算过程 3.1.1 卷积计算卷积神经网络的输入层为二维图像的所有像素值。卷积神经网络的核心思想是利用多层卷层(convolution layer)对图像逐层提取更高层次的特征,期间特征不断地以特征图(feature map)的形式作为输入传递到下一个卷积层。假设第l层的第j个特征图为Xjl(输入层可视为原始特征图X11),Xjl的卷积操作计算公式如下
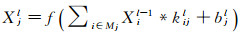 (1)
(1)
式中,kijl为卷积层的权重参数;bjl为偏置变量参数;f(*)为激活函数,其作用是对特征值进行映射。f(*)类型包含多种,例如AlexNet中常用的“ReLU”激活函数,表示f(x)=max(x, 0)。
3.1.2 池化计算为减少参数规模,每个卷积层后对应一个抽样层(subsampling layer),也称为池化层。池化的作用是对特征图进行尺寸上的缩小操作。假设池化后的特征图为Xjl+1,池化操作计算公式如下
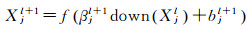 (2)
(2)
式中,βjl+1为池化层的权重参数;bjl+1为偏置变量参数;down(*)为规模为池化操作类型;f(*)为激活函数。down(*)类型包含多种,例如,当池化层规模设定为2×2,池化操作类型为“MAX”型时,表示2×2范围内的像素值用其最大的值代替。对于一个卷积神经网络模型而言,f(*)和down(*)的类型在模型开始训练之前就已经设定好,需要训练的对象是各层的卷积权重kijl和偏置bjl,以及池化权重βjl+1和偏置bjl+1。
3.1.3 损失值计算经过一系列的卷积、池化以及映射操作后,到达CNN的损失层(loss layer)。损失层是CNN的终点,接受两个输入数据,一个为CNN的预测值;另一个为该样本的真实标签。在损失层中经过运算,输出卷积神经网络的损失值(loss)。loss是评价模型收敛效果的重要指标,用来衡量模型分类估计值与真实值之间误差值,越趋近于0则表示模型对于当前测试数据的分类效果越好。
AlexNet采用Softmax计算损失值。Softmax广泛应用于各种机器学习算法中,其作用是把所有输出项的值都压缩到0到1区间内。假设有K个分类标签,Softmax计算如下
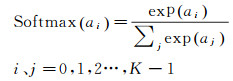 (3)
(3)
式中,ai表示CNN对于第i个分类标签的预测值,Softmax的结果相当于输入图像被分到每个标签的概率分布。假设图像正确分类为第x个标签,则loss的计算如下
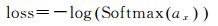 (4)
(4)
从公式可以看出,得到正确分类的概率越高,loss的值就越小。loss值作为误差反向传播(back-propagation)的起点,通过链式求导将值传递回池化层和卷积层,作为kijl、bjl、βjl+1和bjl+1等参数更新的依据。
训练的过程可简要概括为:在训练迭代过程中对各样本进行卷积、池化以及映射等操作得到模型对样本分类的预测值;计算得到损失值loss,通过误差反向传播算法计算参数修正梯度值;对以上4个参数的值不断地进行迭代修正,以趋近全局最优解参数。具体涉及公式本文不再赘述,详情请参考文献[9—11]。
3.2 训练立交桥分类卷积神经网络为了训练用于立交桥分类的卷积神经网络模型,本文选取了常见3类典型的交叉路口作为试验对象,分别为:十字型路口、喇叭型交叉路口和苜蓿型交叉路口,样本示例如图 10所示。该3类样本出现的频率较高,容易在短时间内收集大量样本用于试验测试。用于训练的数据样本总量为8721个,按2:1的比例分为训练集和测试集。

|
| 图 10 4类交叉路口样本示例 Fig. 10 Samples of 4 different interchanges |
Caffe提供了在其框架下定义的AlexNet模型文件,以及修改控制训练过程的参数文件。通过修改参数文件,可以对训练的基础学习率(base learning-rate)、权重衰减系数(weight decay)、最大迭代次数(max iteration)等参数进行调整。基础学习率如果太大,容易跨过极值点,如果设置太小,又容易陷入局部最优;权重衰减系数用来防止训练过拟合,一般设置为经验值0.000 5;最大迭代次数由样本数据量和模型的复杂程度决定。
根据本文样本数据的特点,对以上参数进行了调试,最终将学习率设置为0.001,权重衰减系数设置为0.000 5,迭代次数设置为1000。模型在训练中的收敛过程和最终得到的loss和准确值accuracy,如图 11所示。accuracy是指模型在分类正确时给出的概率值,越趋近于1表示分类的可信度越高。在本文参数设置下,模型对于测试集的最终分类loss值为0.220 7,accuracy值为0.919 4,并且从图 11可以看出,在训练过程中整个AlexNet模型得到了较好的收敛。

|
| 图 11 模型训练过程中loss和accuracy变化曲线 Fig. 11 Curves of loss and accuracy |
值得注意的是,模型训练accuracy值为测试集样本的分类正确率,该指标反映出模型的训练效果,并不能完全代表其在实际应用中的分类效果。为进一步验证本文模型的有效性,根据1.2节提出的分类流程,本文在试验与分析中收集了另一城市的交通数据对该模型进行分类测试。
4 试验与分析试验数据为OSM提供的大比例尺重庆市交通要素数据。通过交叉路口初步定位,本文获得了1846个待识别的交叉路口,如图 12所示。

|
| 图 12 试验数据及待分类定位点 Fig. 12 Experimental data and potential interchange points |
如图 13所示,待分类立交桥在卷积神经网络计算下依次得到各个层级的特征图,并最终由激活函数计算得到分类的概率值。从图 13中可以看到,当图像输入到CNN中时,特定的像素结构与特定的卷积核相乘得到较高的响应值(图中Conv*为各卷积层计算后得到的特征图,红色代表较高响应,蓝色代表较低响应)。待识别图像和训练图像中的某一类特征对应上后才会被保留,反之会被忽略,以避免干扰项的影响。CNN中的卷积核不需要预先的人工设计,而是通过大量样本的训练不断调整卷积核参数。其参数不断调整直至稳定的过程也就是CNN的收敛过程。该过程使其具备从不同形态和干扰中区分各类型立交桥的能力。

|
| 图 13 采用CNN进行深层次特征提取并得到预测结果 Fig. 13 Deep features and prediction result given by CNN |
分类的局部效果如图 14所示,黄色点表示分类为苜蓿型(Clover)立交桥,红色点表示分类为喇叭型(Trumpet)立交桥,蓝色点表示分类为十字型(Cross)路口。采用CNN分类输出的结果是待识别对象被归为各类型的分类概率值(p)。p越接近1则表示该位置路口被分为该类型的可信度越高。本文将分类结果采纳的最低置信度设置为0.7,满足p>0.7的分类结果则认为模型将其分类为对应类型路口。从分类的局部放大效果图可以看出,分类结果与其真实类型吻合度较高。

|
| 图 14 利用立交桥卷积神经网络分类模型对OSM数据进行识别 Fig. 14 Result of interchange classification of OSM data |
试验中部分典型复杂交叉路口的分类效果如图 15所示,图中展示了模型给出的各项分类对应概率值。由分类的结果可以看出,待识别立交桥均以较高的概率划分到了正确的分类中。

|
| 图 15 部分复杂路口的分类效果 Fig. 15 Result of complex interchange classification |
将本文方法与基于人工特征的立交桥分类方法进行对比。采用传统的人工特征描述方法得到的结果如表 2所示,编号1—6分别对应图 15中的6个立交桥测试区域。表 2中各项指标参照文献[3]的道路拓扑类型描述方法进行计算,量化表达式的5个参数分别代表:判断区域内悬挂道路数、桥接道路数、轮廓道路数、网眼内部道路数和孤立路段数。从计算的结果来看,量化表达式在各种干扰下与理论值偏差较大,无法匹配到正确的立交桥类型,在OSM数据中基本无法应用。
| 编号 | 量化表达式 | 理论量化表达式 | 匹配情况 |
| 1 | (22, 2, 10, 45.0) | Clover(4, 0, 4, 4, 0) | 不匹配 |
| 2 | (17, 1, 8, 23, 0) | Clover(4, 0, 4, 4, 0) | 不匹配 |
| 3 | (10, 1, 4, 16, 0) | Clover(4, 0, 4, 4, 0) | 不匹配 |
| 4 | (9, 0, 8, 12, 0) | Trumpet(3, 0, 2, 0, 0) | 不匹配 |
| 5 | (12, 2, 6, 7, 0) | Trumpet(3, 0, 2, 0, 0) | 不匹配 |
| 6 | (8, 0, 11, 4, 0) | Trumpet(3, 0, 2, 0, 0) | 不匹配 |
进一步对试验结果进行统计分析,如表 3所示。表中查全率(recall)由模型正确分类数除以人工判别数量得出,能够反映该模型对于特定类型的识别效果;查准率(precision)由模型正确分类数除以模型分类总数量得出,能够反映该模型对于非特定类型路口的区分效果。F1测度值是查全率和查准率的调和均值,即在认为两者具有同等重要作用的前提下,将二者结合为一个指标。
 (5)
(5)
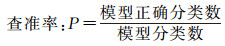 (6)
(6)
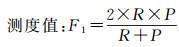 (7)
(7)
| 交叉路口类型 | 人工判别数 | 模型分类数 | 模型正确分类数 | 查全率R /(%) | 查准率P /(%) | 测度值F1 |
| 喇叭型(Trumpet) | 265 | 324 | 257 | 96.98 | 79.32 | 0.872 4 |
| 苜蓿型(Clover) | 74 | 91 | 63 | 85.14 | 69.23 | 0.763 6 |
| 十字型(Cross) | 591 | 546 | 538 | 91.03 | 98.53 | 0.946 3 |
从分类试验效果图以及相关统计可以得出:
(1) 该模型的分类效果比较好,能够有效地对一些复杂的路口和立交桥结构进行正确定位和分类。如图 15所示,从复杂路口的分类效果展示中可以看出,对于存在大量干扰的复杂喇叭型和苜蓿型交叉路口,该模型能够准确判断出对应的立交桥类型,并给出了较高的分类概率值。
(2) 查全率值较高,说明卷积神经网络对于立交桥样本进行了很好的学习,能够从复杂形态结构中抽取出高层次的模糊特征,从而对存在形变和干扰的立交桥能够准确分类。
(3) 从试验的整个流程可以看出,基于卷积神经网络的立交桥识别的另一优势在于,不需要很强的专家知识的指导,人为对于模型的干预较少,减轻了研究模型的成本,缩短了模型研究的周期。
但仍存在部分错误分类的情况,对查准率造成了不利影响,如图 16所示。从错误分类的路口示例可以看出,该部分路口不属于以上任何一种类型,由于模型需要对所有路口输出一个分类结果,因此容易错误地将待分类对象归类到本文的3种类型中。因此对于提高模型的查准率,可以通过进一步丰富已有的样本库、建立其他类型立交桥样本库以及扩充“非典型交叉路口”样本库的方式进行改善,从而进一步提高模型实际应用能力。

|
| 图 16 错分类交叉路口示例 Fig. 16 Samples of the errors in interchange classification |
5 结论
本文将当前机器视觉领域的研究热点模型卷积神经网络引入到道路交叉路口的分类中,通过矢量数据与栅格图像相结合的方式,将对视觉依赖性较强的分类环节交给CNN模型,学习深层次的模糊性分类特征,结合矢量结构特征的快速定位,实现了对于OSM数据的立交桥识别和分类。本文的分类策略具备了一定的模糊感知能力,能够对存在干扰的喇叭型和苜蓿型立交桥进行准确的识别,并且由于分类模块依赖的是CNN模型的训练,不涉及复杂的人工特征设计,降低了模型研究的成本投入。
对于分类效果的进一步提升,需要继续丰富样本库类型、扩大样本库规模以及提升样本库质量;同时结合CV领域的最新研究成果,寻找适应性更强的图像分类模型。在后续研究中,可探索CNN在制图综合中的更多应用,以解决传统特征描述手段难以解决的制图综合问题。
| [1] | MACKANESS W A, MACKECHNIE G A. Automating the Detection and Simplification of Junctions in Road Networks[J]. GeoInformatica, 1999, 3(2): 185–200. DOI:10.1023/A:1009807927991 |
| [2] |
徐柱, 蒙艳姿, 李志林, 等.
基于有向属性关系图的典型道路交叉口结构识别方法[J]. 测绘学报, 2011, 40(1): 125–131.
XU Zhu, MENG Yanzi, LI Zhilin, et al. Recognition of Structures of Typical Road Junctions Based on Directed Attributed Relational Graph[J]. Acta Geodaetica et Cartographica Sinica, 2011, 40(1): 125–131. |
| [3] |
王骁, 钱海忠, 丁雅莉, 等.
采用拓扑关系与道路分类的立交桥整体识别方法[J]. 测绘科学技术学报, 2013, 30(3): 324–328.
WANG Xiao, QIAN Haizhong, DING Yali, et al. The Integral Identification Method of Cloverleaf Junction Based on Topology and Road Classification[J]. Journal of Geomatics Science and Technology, 2013, 30(3): 324–328. |
| [4] |
马超, 孙群, 陈换新, 等.
利用路段分类识别复杂道路交叉口[J]. 武汉大学学报(信息科学版), 2016, 41(9): 1232–1237.
MA Chao, SUN Qun, CHEN Huanxin, et al. Recognition of Road Junctions Based on Road Classification Method[J]. Geomatics and Information Science of Wuhan University, 2016, 41(9): 1232–1237. |
| [5] | DONAHUE J, JIA Yangqing, VINYALS O, et al. DeCAF:A Deep Convolutional Activation Feature for Generic Visual Recognition[J]. Computer Science, 2013, 50(1): 815–830. |
| [6] | JIA Yangqing, SHELHAMER E, DONAHUE J, et al. Caffe: Convolutional Architecture for Fast Feature Embedding[C]//Proceedings of the 22nd ACM International Conference on Multimedia. Orlando, Florida: ACM, 2014: 675-678. |
| [7] |
何小飞, 邹峥嵘, 陶超, 等.
联合显著性和多层卷积神经网络的高分影像场景分类[J]. 测绘学报, 2016, 45(9): 1073–1080.
HE Xiaofei, ZOU Zengrong, TAO Chao, et al. Combined Saliency with Multi-convolutional Neural Network for High Resolution Remote Sensing Scene Classification[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(9): 1073–1080. DOI:10.11947/j.AGCS.2016.20150612 |
| [8] | ZHU Qiqi, ZHONG Yanfei, ZHAO Bei, et al. Bag-of-visual-Words Scene Classifier With Local and Global Features for High Spatial Resolution Remote Sensing Imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(6): 747–751. DOI:10.1109/LGRS.2015.2513443 |
| [9] |
刘栋, 李素, 曹志冬.
深度学习及其在图像物体分类与检测中的应用综述[J]. 计算机科学, 2016, 43(12): 13–23.
LIU Dong, LI Su, CAO Zhidong. State-of-the-art on Deep Learning and Its Application in Image Object Classification and Detection[J]. Computer Science, 2016, 43(12): 13–23. DOI:10.11896/j.issn.1002-137X.2016.12.003 |
| [10] | LECUN Y, BOSER B, DENKER J S, et al. Backpropagation Applied to Handwritten Zip Code Recognition[J]. Neural Computation, 1989, 1(4): 541–551. DOI:10.1162/neco.1989.1.4.541 |
| [11] | HINTON G E, SALAKHUTDINOV R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786): 504–507. DOI:10.1126/science.1127647 |
| [12] | LECUN Y, BENGIO Y, HINTON G. Deep Learning[J]. Nature, 2015, 521(7553): 436–444. DOI:10.1038/nature14539 |
| [13] | DENG Li, YU Dong. Deep Learning:Methods and Applications[J]. Foundations and Trends in Signal Processing, 2014, 7(3-4): 197–387. DOI:10.1561/2000000039 |
| [14] |
谢剑斌, 兴军亮, 张立宁, 等.
视觉机器学习20讲[M]. 北京: 清华大学出版社, 2015.
XIE Jianbin, XING Junliang, ZHANG Lining, et al. 20 Lectures On Visual Machine Learning[M]. Beijing: Tsinghua University Press, 2015. |
| [15] |
周志华.
机器学习[M]. 北京: 清华大学出版社, 2016.
ZHOU Zhihua. Machine Learning[M]. Beijing: Tsinghua University Press, 2016. |
| [16] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. DOI:10.1109/5.726791 |
| [17] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Image Net Classification with Deep Convolutional Neural Networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: ACM, 2012: 1097-1105. |
| [18] | HEINZLE F, ANDERS K H, SESTER M. Pattern Recognition in Road Networks on the Example of Circular Road Detection[C]//RAUBAL M, MILLER H J, FRANK A U, et al. Geographic Information Science. Berlin, Heidelberg: Springer, 2006: 153-167. |
| [19] | MACKANESS W A, RUAS A, SARJAKOSKI L T. Generalisation of Geographic Information:Cartographic Modelling and Applications[M]. Amsterdam: Elsevier Science Ltd, 2007: 196-197. |
| [20] | YANG Bisheng, LUAN Xuechen, LI Qingquan. An Adaptive Method for Identifying the Spatial Patterns in Road Networks[J]. Computers, Environment and Urban Systems, 2010, 34(1): 40–48. DOI:10.1016/j.compenvurbsys.2009.10.002 |