



2. 福州大学空间数据挖掘与信息共享教育部重点实验室, 福建 福州 350002;
3. 福州大学福建省空间信息工程研究中心, 福建 福州 350002
2. Key Laboratory of Spatial Data Mining and Information Sharing of Ministry of Education, Fuzhou University, Fuzhou 350002, China;
3. Spatial Information Research Center of Fujian Province, Fuzhou University, Fuzhou 350002, China
随着经济的快速发展, 城市的规模、市政设施的种类、数据在急剧增加,城市的结构也在发生巨大的变化。城市环境中的道路交通设施,特别是路侧的行道树、车辆、杆状目标(交通标志牌、路灯)等设施是城市管理和更新的重要对象,广泛服务于环境保护、智能交通、高精度导航等领域。传统的测绘手段难以快速、精确采集和更新这些目标的信息。车载激光扫描系统作为近年来快速发展的高新技术,能够高效、精准地获取道路及其周围场景的三维空间信息,已成为城市道路交通信息采集和更新的一种重要途径。然而车载激光点云具有场景复杂、目标多样、数据量大且点密度分布不均等特点,给车载激光点云的数据处理带来很大挑战。
国内外研究学者针对车载激光点云数据处理开展深入研究。一些学者逐点(point-parse)分析局部邻域中的高程、强度、法向量等差异,将点云分割成不同目标[1-3]。基于点的邻域信息和局部变化,只能提取局部最优特征,目标分类精度易受邻域尺寸(点数)、点密度等因素影响,且针对复杂几何目标特征分类精度较低。由于同一目标的点云数据不仅具备相似的宏观特性(如形状、离散度、特征值分布等),还具有相似的局部几何特性(如法向量、局部粗糙度、曲率、点到平面距离等),同时还具备相似的属性特性(如反射强度、颜色信息等)。一些学者采用面向对象的策略(object-based),先将点云分割成目标,然后分析目标的几何、形状和纹理信息进行目标提取。如文献[4]基于多尺度超体素进行区域聚类分割,根据先验知识设定各类目标对象几何特征分类阈值实现多类目标层次化提取;文献[5]根据地物目标点云分割面的大小、形状、方向以及拓扑关系提取行道树、建筑物立面;文献[6-7]将点云数据分割成独立目标对象,并利用整体目标的特征分别提取路灯和行道树;文献[8-9]同样将分割成独立目标对象,然后基于模型驱动的方式计算目标模型和待检测对象之间成对3D形状上下的相似度进行目标点云提取。尽管这些低层次(low-level)基础特征在车载激光点云目标提取中取得一定的进展,但特征选择和参数设置均需要较强的先验知识。随着城市场景的增大以及复杂性的增强,直接用这些基础特征进行目标点云提取,经常表现不足,难以跨越低层数据特征到场景高层语义的鸿沟,导致“数据丰富、但语义信息匮乏”的现状。
深度学习作为机器学习领域的重要分支,通过建立类似于人脑的分层网络模型结构,对输入数据逐级提取从底层到高层的特征,从而能很好地建立从底层信号到高层语义的映射关系,在图像识别[10-13]、自然语言理解[14]、语音识别[15-16]等领域深度学习均取得了突破性的进展。近年来,一些学者将深度学习思想引入3D目标或点云目标提取中,有效地实现了对复杂目标的特征提取和自动分类。如文献[17]构建一种3D ShapNets模型,利用卷积深度信念网络(CDBN)将3D几何形状表示为体素的概率分布作为描述特征进行3D目标识别;文献[18]提出VoxNet模型,采用3D卷积神经网络(3D CNN)进行3D目标识别;文献[19]采用多视角卷积神经网络(CNN)进行3D目标识别;文献[20]提出一种3D ConvNet模型(包括3D区域建议网络和目标识别网络)实现RGB-D图像中的目标自动检测识别;文献[21]先将路面车载激光点云生成强度图像,然后构建深度玻尔兹曼机(DBM)描述强度图像的局部高阶特征,最后利用随机森林检测路面中的下水道井盖;文献[22-23]利用DBM作为特征提取模型,分别结合多尺度霍夫森林和视觉短语袋技术从车载激光点云数据中提取车辆和交通标志牌。
纵观国内外的研究现状可以看出,相对于较为成熟的车载激光扫描硬件系统,车载激光点云的目标提取还处于初级阶段。特别是将深度学习方法应用于大范围复杂城市场景车载激光点云目标提取的研究还非常有限。针对上述不足,本文采用面向对象的思想,以分割后目标对象代替传统逐点为单元进行处理,利用DBN的多层网络结构自动学习有效的高级特征并实现路侧多目标自动提取,从而提高车载激光扫描数据解译的智能化程度。
1 深度信念网络(deep belief network, DBN)简介DBN是一种多层网络结构的概率生成模型[24]。从结构上看,DBN由多层无监督的受限波尔兹曼机(restricted Boltzmann machine, RBM)[25]和一层有监督的分类层(如softmax)组成。相邻的两层可看成一个独立的RBM,低层RBM的输出,作为上一层RBM的输入,其结构如图 1所示。

|
| 图 1 DBN示意图 Fig. 1 Schematic diagram of DBN |
RBM作为无监督学习的生成式模型,其结构主要包含一层可见层以及一层隐含层,且层内无连接,层间全连接,如图 2所示。其中v、h分别表示可见层节点单元和隐含层节点单元,b、c分别表示可见层和隐含层的偏置,w表示两层各个节点之间的连接权重值。

|
| 图 2 RBM示意图 Fig. 2 Schematic diagram of RBM |
假设可见层和隐含层均为二值变量,那么当给定可见层以及隐含层各个节点的某一组状态(v, h)时,即可定义RBM的能量函数为
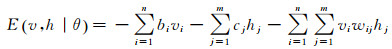 (1)
(1)
式中,θ=(wij, bi, cj)。基于能量函数(式(1))可得(v, h)的联合概率分布
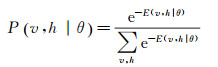 (2)
(2)
式中,e为自然常数。
由于RBM层内节点单元无连接,当给定一组可见层节点的状态值时,隐含层各个节点间的激活状态是相互独立的,那么对于隐含节点hj状态为1的概率
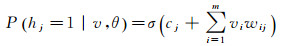 (3)
(3)
式中,σ(x)=1/(1+e-x)为sigmoid函数。同理,当给定一组隐含层各节点单元的值时,重构的可见层各节点单元vi状态为1的概率
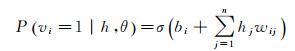 (4)
(4)
RBM的训练即是学习参数θ使其表示的Gibbs分布最大可能拟合给定的训练数据。然而采用k步Gibbs采样求解时k需达到一个比较大的值,那么其计算量将随着样本数量的增加以指数级增长,从而导致无法实现快速训练RBM。为了解决RBM训练效率的问题,文献[26]提出了基于对比散度(contrastive divergence,CD)快速训练方法,参数更新准则如下
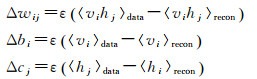 (5)
(5)
式中,〈·〉data表示输入数据所确定的期望;〈·〉recon为重构后RBM定义的分布上的期望。
2 路侧多类目标提取方法本文提出的路侧多目标提取方法主要包括数据预处理、点云分割、生成基于多方向目标对象特征描述和基于DBN的多目标提取4个主要步骤,如图 3所示。

|
| 图 3 车载激光点云路侧多目标提取流程 Fig. 3 Flow chart of roadside multiple objects extraction from MLS point clouds |
2.1 车载激光点云数据预处理
由于车载激光点云数据量庞大的特点,为了提高数据处理的效率,本文采用一种基于伪轨迹点的自动分段方法进行原始点云数据分段处理。首先,采用文献[27]的方法提取车载激光点云扫描线,根据扫描线上激光脚点与扫描仪距离越近点云分布越密集的特点,将每条扫描线上分布最密集的点作为车载激光扫描系统作业时的行驶路径(图 4(b))。然后对行驶路径上中的点进行等间距采样获得伪轨迹点,并将伪轨迹点按GPS时间顺序标记为(P1, P2, …, Pn),如图 4(c)所示;以Pi为坐标系原点O,Pi至Pi+1的方向为Y轴正方向,垂直Y轴向右为X轴正方向建立局部坐标系,将局部坐标系中坐标Y值介于Pi和Pi+1的点划分为Si段,分段结果如图 4(d)所示。

|
| 图 4 车载激光点云数据预处理 Fig. 4 Preprocessing of MLS point cloud |
本文主要针对道路两侧的行道树、车辆以及杆状目标的提取,而车载激光扫描数据中不仅存在大量的地面和建筑物点云数据,且它们常常作为连接的纽带将不同的地物点云连接束缚在一起,严重影响了数据处理的效率和空间复杂性。因此本文以分段后的点云片段作为处理单元,首先利用文献[1]的方法快速剔除建筑物点云;然后采用基于体素向上增长的策略滤除地面点云[28],最终得到路侧地物点云结果如图 4(e)、(f)所示。
2.2 路侧点云分割预处理后的路侧点云仍然散乱无序,本文采用基于连通分支(connected component)[29]的聚类分析算法进行地物点云聚类。首先利用Octree通过设定剖分体素最大边长wc进行地物点云体素剖分,即当剖分体素任一维度上的边长大于wc时,则进一步迭代剖分,剖分结果如图 5(a)、(b)所示;然后以每个体素内所有点的中心位置作为该体素的节点位置,并计算每两个节点间的空间距离作为边构建无向图G1={V1, E1},其中V1为图的节点,E1为节点之间连接的边;最后设定近邻阈值dn利用连通分支分析将图G1生成若干连通子图,每个连通子图中所有体素包含的点云构成一个聚类簇,并将聚类簇中点云数量小于一定阈值n时视为噪声点剔除,聚类结果如图 5(c)所示。

|
| 图 5 地物点云聚类 Fig. 5 Off-ground points clustering |
本文对整个场景点云数据采用分段处理,使得部分边界处的目标对象被划分到两个点云片段中。因此本文在对Si段地物点云进行聚类时,通过判断数据预处理的局部坐标系中伪轨迹点Pi所在XOZ面上是否存在聚类簇的点,将其标记为边界或非边界处聚类簇,并将边界处聚类簇点云添加至相邻Si+1片段的地物点云中,当对Si+1段点云进行聚类时即可得边界处目标完整的点云聚类结果。
同时聚类结果中存在一个聚类簇包含多个相邻地物的情况,如图 6(a)、(b)所示,本文采用基于体素的归一化分割(Ncut)方法进行分割。文献[30]提出了基于Ncut的图像分割方法,而后文献[9, 31-32]将Ncut扩展到3D空间应用于基于体素的点云分割。本文首先利用Octree同样通过设定剖分体素最大边长ws重新对聚类簇进行体素剖分,如图 6(c)、(d)所示,以每个体素中所有点的中心位置作为节点V2,根据式(6)计算各边E2的连接权重w构建加权图G2={V2, E2}

|
| 图 6 交错重叠点云分割 Fig. 6 Overlapping point cloud segmentation |
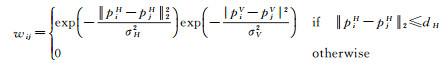 (6)
(6)
式中,pi=(xi, yi, zi)、pj=(xj, yj, zj)分别表示第i个节点和第j个节点的位置;piH=(xi, yi);piH=(xi, yi);piV=Zi;pjV=Zj;σH和σV分别为水平分布和竖直分布的标准差;dH为两节点间有效连接的最大水平距离阈值。
Ncut通过最小化目标函数Ncut(A, B)(式(7))使分割结果A、B的类内相似性最大和类间相似性最小
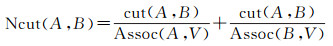 (7)
(7)
式中,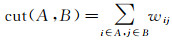
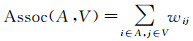
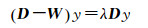 (8)
(8)
式中,W=wij;D为对角阵,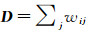
经过上述过程,道路两侧地物点云被分割成许多独立的目标对象,实现将三维离散点云的特征识别转换为面向对象的目标提取。由于DBN具备自主学习高级特征的能力,能够将基础特征抽象整合为更高级的描述特征,计算机利用这种高级特征进行目标识别具有更高的稳健性。因此本文仅利用目标的3个方向剖面构建全局描述特征作为DBN模型的输入数据进行目标自动提取。因本文DBN模型的节点采用服从伯努利分布的{0,1}二值变量,所以将目标对象每个剖面生成二值图像,并依次展开排列成二值向量。具体流程如图 7所示,首先在原始点云数据坐标系XOY平面上定义X轴正方向为0°方向,并标记为“方向1”,按逆时针方向,取120°方向和240°方向,分别标记为“方向2”和“方向3”,共标定3个不同方向;然后分别在垂直3个方向的平面上对目标点云进行50×50的规则格网划分,若格网中存在点则标记该格网值为“1”,否则标记为“0”,从而生成3幅二值图像;最后将每幅二值图像按行依次排列成2500维的二值向量,并将3个二值向量串联排列成7500维的二值向量作为目标对象的全局特征描述。

|
| 图 7 基于多个方向生成目标对象全局特征描述 Fig. 7 Generating global feature description based on multiple directions |
2.4 基于DBN的多目标提取
将上述提取的多方向目标对象全局描述特征向量输入DBN进行目标提取时,首先需要构建DBN模型,主要包括确定隐含层的节点数和隐含层的层数;其次训练DBN,学习DBN的网络参数。DBN作为包含多层隐藏层的网络结构,其训练过程主要包括预训练与微调两部分:①贪婪逐层预训练,采用无监督学习方法,对较低层进行训练,生成第1层RBM网络的初始参数,然后将低一层RBM的隐含层输出作为高一层的RBM的可见层输入, 通过逐层训练RBM的方式初始化DBN网络中各隐含层之间的参数,得到接近全局最优的网络参数;②有监督微调,在DBN的顶层利用分类器将RBM网络学习到高级特征组合进行分类,并采用BP算法有监督地训练输出层,同时将网络误差反向传播至所有RBM网络层中,微调整个DBN网络的参数,使DBN网络的参数达到全局最优,得到适合目标分类的DBN模型。最后利用训练好的DBN模型从车载激光扫描数据路侧点云分割结果中提取出行道树、车辆及杆状目标,整体流程如图 8所示。

|
| 图 8 基于DBN的多目标提取流程 Fig. 8 Flow chart of multiple objects extraction based on DBN |
3 试验与分析 3.1 试验数据
本文试验采用两份由Lynx Mobile Mapper系统采集的不同城市道路场景车载激光点云数据(图 9)。数据1为体育馆周边场景,其道路总长约为1379 m,共26 007 519个数据点,点密度约为95点/m2,整体呈环状分布,道路两侧分布着大量的车辆、行道树、路灯、交通指示牌等;数据2为城市街区场景,其道路总长约为1547 m,共17 205 416个数据点,点密度约为46点/m2,整体上呈直线型分布,其中包含两处直角弯,道路两侧分布着大量的行道树、路灯、交通指示牌等杆状目标。

|
| 图 9 两份不同道路场景的试验数据 Fig. 9 Experimental data of two different road scenes |
由于目前没有现成的训练样本集可用于训练目标点云提取的DBN网络模型,因此本文需建立一个训练样本集。首先采用人工的方式从若干不同场景的车载激光点云中提取不同形状、姿态的行道树、车辆、杆状目标作为基础正训练样本,部分如图 10(a)所示,数量分别为124、149、139。同时提取了100个其他地物作为负训练样本,部分如图 10(b)所示。

|
| 图 10 人工提取训练样本 Fig. 10 Manually extracted training samples |
由于人工提取样本的成本较高,本文为了快速扩增训练样本的总体容量,将人工提取的每个样本绕自身中心Z轴方向顺时针每旋转10°生成一个训练样本,如图 11所示,最终建立一个如表 1所示的训练样本集。

|
| 图 11 旋转生成训练样本 Fig. 11 Generating training samples by rotation |
| 样本类别 | 行道树 | 车辆 | 杆状目标 | 负样本 |
| 标签编码 | 1000 | 0100 | 0010 | 0001 |
| 基础样本数量 | 124 | 149 | 139 | 100 |
| 总体样本数量 | 4464 | 5364 | 5004 | 3600 |
3.2 构建DBN
DBN的隐含层节点数直接关系着隐含层对输入层的表达情况,节点数量过少则会限制其学习特征的能力,使得难以处理复杂的问题;过多则不仅影响训练效率,而且对输入数据的冗余信息也进行学习,易导致过度拟合。目前针对隐含层的节点数的设定还没有非常成熟的理论支撑,在实际应用过程中主要依靠经验和对比试验进行设置。本文采用对比试验确定隐含层节点数,并以测试精度和模型训练效率所为评价指标。首先从训练样本集中随机选取2000个样本作为测试数据,其余样本作为训练数据;其次DBN的输入层节点数为7500,隐含层节点数从500至7000每间隔500测试一次,测试结果如图 12所示。

|
| 图 12 不同隐含层节点数量测试结果变化趋势 Fig. 12 Variation trend of test results for different hidden layer nodes |
从测试结果可以看出,当隐含层节点数达2500时,其测试精度达94.35%且趋于平稳。因此综合考虑训练效率可以看出隐含层节点数为2500时,其性能更优。
DBN通过非线性深层网络结构拟合复杂数据,理论上隐含层数越多其对数据表达能力越强,但增加隐含层数的同时也增加了网络模型复杂度,不仅影响模型的训练效率,而且训练更加困难,如果训练不好其拟合效果反而更差。因此本文通过逐层增加的方式构造DBN进行测试,结果如表 2所示。
| DBN结构 | 隐含层 层数 |
测试精度 /(%) |
训练时间 /h |
| type A:7500-2500-4 | 1 | 94.35 | 8.36 |
| type B:7500-2500-2500-4 | 2 | 99.55 | 11.15 |
| type C:7500-2500-2500- 2500-4 |
3 | 98.00 | 13.93 |
| type D:7500-2500-2500- 2500-2500-4 |
4 | 97.85 | 16.72 |
从结果中可以看出,隐含层数为2的测试精度达最高99.55%,因此本文最终采用第2种网络结构7500-2500-2500-4的DBN作为多类目标提取模型。
3.3 试验结果本文试验计算环境为i7-4790 CPU、8GB内存,实现平台为Matlab2014a。试验采用15 m作为一个处理单元(约15万至20万个数据点)对原始车载激光点云进行分段处理。在路侧点云分割的过程中,由于感兴趣的行道树、车辆和杆状目标的体积均较大,同时车辆与行道树和杆状目标、杆状目标与行道树之间的最近距离一般都大于0.5 m。因此本文进行点云聚类时综合考虑效率和聚类效果将Octree剖分体素最大边长wc设为0.25 m,近邻距离阈值dn设为0.5 m。对部分相邻目标由于最近距离小于0.5 m导致多个目标被聚成一个类簇进行分割时,Octree剖分体素最大边长ws设为0.4 m,最大有效连接水平距离dH设为ws的2.5倍,最终得到路侧点云分割结果如图 13、图 14所示。构建分割后目标对象多方向的特征描述向量作为输入,并利用训练好type B(7500-2500-2500-4)DBN模型提取出两份试验数据中的行道树、车辆和杆状目标,结果如图 15、图 16所示。

|
| 图 13 试验数据1目标分割结果 Fig. 13 Experimental data 1 objects segmentation results |

|
| 图 14 试验数据2目标分割结果 Fig. 14 Experimental data 2 objects segmentation results |

|
| 图 15 试验数据1多目标提取结果 Fig. 15 Multiple objects extraction results of data 1 |

|
| 图 16 试验数据2多目标提取结果 Fig. 16 Multiple objects extraction results of data 2 |
从试验结果可以看出,两份试验数据中绝大部分的行道树、车辆及杆状目标均能够被正确提取。不仅对于点云数据完整的目标对象具有较好的提取效果,同时部分受遮挡影响导致点云缺失的目标也具有较好的提取效果。如图 15的①和②中所示,许多缺失局部点云的车辆都被正确提取,在图 16的③中路面上只有部分点云的车辆亦被正确标识。虽然本文取得较好的试验结果,但仍存在一些交叉错误提取的情况(图 17)。例如部分行道树(图 17(a))的树冠形态较小,使其整体与杆状目标较为形似,从而被错误提取为杆状目标;一些灌木丛分布形态与车辆较为近似导致被错误提取为车辆(图 17(b));部分杆状目标的形态结构与行道树非常近似导致被错误提取为行道树,如图 17(c)所示;还有部分行人形态与杆状目标较为近似被错误提取为杆状目标(图 17(d))。

|
| 图 17 交叉错误提取结果 Fig. 17 Cross error extraction results |
3.4 试验结果分析
试验数据中没有提供目标标定的真实参考数据,本文采用人工方式从场景点云数据中提取出行道树、车辆、杆状目标,其中部分提取结果由于遮挡导致点云严重缺失,若无场景语义信息辅助人工难以再次准确识别。因此本文将提取结果逐个再次进行人工识别,并通过统计得出未能识别的目标点云数量均小于200。最后本文将人工提取结果中点云数量大于200的视为有效目标作为试验结果质量评价的参考基准。同时采用准确率(precision)、召回率(recall)、精度(quality)以及综合评价指标F1值构建试验结果评价指标
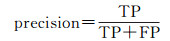 (9)
(9)
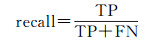 (10)
(10)
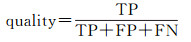 (11)
(11)
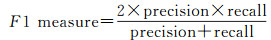 (12)
(12)
式中,TP为正确提取的数量;FP为错误提取的数量;FN未被提取的数量,结果如表 3所示。
| 试验数据 | 类别 | TP | FN | FP | precision/ (%) |
recall/ (%) |
quality/ (%) |
F1 measure/ (%) |
| 数据1 | 行道树 | 289 | 5 | 8 | 97.31 | 98.30 | 95.70 | 97.80 |
| 车辆 | 394 | 5 | 13 | 96.81 | 98.75 | 95.63 | 97.77 | |
| 杆状目标 | 163 | 3 | 9 | 94.77 | 98.19 | 93.14 | 96.45 | |
| 数据2 | 行道树 | 664 | 6 | 12 | 98.22 | 99.10 | 97.36 | 98.66 |
| 车辆 | 91 | 1 | 5 | 94.79 | 98.91 | 93.81 | 96.81 | |
| 杆状目标 | 90 | 3 | 7 | 92.78 | 96.77 | 90.00 | 94.73 |
从以上试验结果中可以看出,行道树提取结果的准确率达97.31%,召回率达98.30%,精度达95.70%,综合评价指标F1值达97.80%;车辆提取结果的准确率达94.79%,召回率达98.75%,精度达93.81%,综合评价指标F1值达96.81%;杆状目标提取结果的准确率达92.78%,召回率达96.77%,精度达90.00%,综合评价指标F1值达94.73%。由于目前还没有与本文一致仅针对路侧行道树、车辆和杆状目标多目标提取方法,因此本文采用单一目标提取的相关研究与本文方法进行对比,进而说明本文试验效果,对比结果如表 4所示。
从以上对比结果可以看出,虽然现有的单一目标提取方法准确率均比本文方法高,但行道树和车辆的准确率差距较小,并且本文方法的召回率、精度、综合评价指标F1值均高于现有的方法,从而验证了本文方法的有效性。
4 结论本文以车载激光点云数据为研究对象,采用面向对象和深度学习的思想,将点云的分类标记问题转化到基于目标识别问题上。利用同一类目标相似的整体性质进行特征提取,融合DBN网络多层特征学习和抽象的能力,实现行道树、车辆及杆状目标的提取。通过两份Lynx Mobile Mapper系统采集的不同城市场景点云数据进行试验验证。试验结果中行道树、车辆及杆状目标提取结果的准确率分别达97.31%、97.79%、92.78%,召回率分别达98.30%、98.75%、96.77%,精度分别达95.70%、93.81%、90.00%,综合评价指标F1值分别达97.80%、96.81%、94.73%。虽然本文方法能够有效提取绝大多数城市道路场景中的行道树、车辆及杆状目标,但提取结果的准确率仍低于现有的单一目标提取方法。这主要是由于本文描述目标对象时仅考虑其整体形态轮廓特征,而没有兼顾目标对象自身点云数据属性特征的差异,从而使得部分树冠点云缺失的树干容易被错误提取为杆状目标,形态与行道树近似的杆状目标容易被错误提取为行道树等。因而笔者在后续的学习工作中将进一步探索简单且能够更充分表征目标对象点云数据属性信息的特征描述子,从而进一步提高目标提取结果的精度。
| [1] | YANG Bisheng, WEI Zhen, LI Qingquan, et al. Automated Extraction of Street-scene Objects from Mobile LiDAR Point Clouds[J]. International Journal of Remote Sensing, 2012, 33(18): 5839–5861. DOI:10.1080/01431161.2012.674229 |
| [2] | LIN Yi, HYYPPA J. k-segments-based Geometric Modeling of VLS Scan Lines[J]. IEEE Geoscience and Remote Sensing Letters, 2011, 8(1): 93–97. DOI:10.1109/LGRS.2010.2051940 |
| [3] |
李婷, 詹庆明, 喻亮.
基于地物特征提取的车载激光点云数据分类方法[J]. 国土资源遥感, 2012, 92(1): 17–21.
LI Ting, ZHAN Qingming, YU Liang. A Classification Method for Mobile Laser Scanning Data Based on Object Feature Extraction[J]. Remote Sensing for Land & Resources, 2012, 92(1): 17–21. DOI:10.6046/gtzyyg.2012.01.04 |
| [4] |
董震, 杨必胜.
车载激光扫描数据中多类目标的层次化提取方法[J]. 测绘学报, 2015, 44(9): 980–987.
DONG Zhen, YANG Bisheng. Hierarchical Extraction of Multiple Objects from Mobile Laser Scanning Data[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(9): 980–987. DOI:10.11947/j.AGCS.2015.20140339 |
| [5] | PU Shi, RUTZINGER M, VOSSELMAN G, et al. Recognizing Basic Structures from Mobile Laser Scanning Data for Road Inventory Studies[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66(S6): S28–S39. |
| [6] | ZAI Dawei, CHEN Yiping, LI J, et al. Inventory of 3D Street Lighting Poles Using Mobile Laser Scanning Point Clouds[C]//Proceedings of 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS). Milan:IEEE, 2015:573-576. |
| [7] | HUANG Pengdi, CHEN Yiping, LI J, et al. Extraction of Street Trees from Mobile Laser Scanning Point Clouds Based on Subdivided Dimensional Features[C]//Proceedings of 2015 IEEE International Geoscience and Remote Sensing Symposium. Milan:IEEE, 2015:557-560. |
| [8] | YU Yongtao, LI J, LI Jun, et al. Pairwise Three-dimensional Shape Context for Partial Object Matching and Retrieval on Mobile Laser Scanning Data[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(5): 1019–1023. DOI:10.1109/LGRS.2013.2285237 |
| [9] | YU Yongtao, LI Jun, GUAN Haiyan, et al. Automated Extraction of 3D Trees from Mobile LiDAR Point Clouds[C]//ISPRS International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. Riva del Garda, Italy:ISPRS, 2014:629-632. |
| [10] | BASU S, GANGULY S, MUKHOPADHYAY S, et al. DeepSat:A Learning Framework for Satellite Imagery[C]//Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems. Seattle, Washington:ACM, 2015:37. |
| [11] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada:Curran Associates Inc., 2012:1097-1105. |
| [12] | GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH:IEEE, 2013:580-587. |
| [13] | SUN Yi, WANG Xiaogang, TANG Xiaoou. Deep Learning Face Representation from Predicting 10, 000 Classes[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH:IEEE, 2014:1891-1898. |
| [14] | SARIKAYA R, HINTON G E, DEORAS A. Application of Deep Belief Networks for Natural Language Understanding[J]. Proceedings of IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(4): 778–784. DOI:10.1109/TASLP.2014.2303296 |
| [15] | GRAVES A, MOHAMED A R, HINTON G. Speech Recognition with Deep Recurrent Neural Networks[C]//Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, BC:IEEE, 2013:6645-6649. |
| [16] | DENG Li, HINTON G, KINGSBURY B. New Types of Deep Neural Network Learning for Speech Recognition and Related Applications:An Overview[C]//Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver, BC:IEEE, 2013:8599-8603. |
| [17] | WU Zhirong, SONG Shuran, KHOSLA A, et al. 3D ShapeNets:A Deep Representation for Volumetric Shapes[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA:IEEE, 2015:1912-1920. |
| [18] | GARCIA-GARCIA A, GOMEZ-DONOSO F, GARCIA-RODRIGUEZ J, et al. PointNet:A 3D Convolutional Neural Network for Real-time Object Class Recognition[C]//Proceedings of 2016 International Joint Conference on Neural Networks. Vancouver, BC:IEEE, 2016:1578-1584. |
| [19] | SU Hang, MAJI S, KALOGERAKIS E, et al. Multi-View Convolutional Neural Networks for 3D Shape Recognition[C]//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago:IEEE, 2015:945-953. |
| [20] | SONG Shuran, XIAO Jianxiong. Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV:IEEE, 2016:808-816. |
| [21] | YU Yongtao, GUAN Haiyan, JI Zheng. Automated Detection of Urban Road Manhole Covers Using Mobile Laser Scanning Data[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(6): 3258–3269. DOI:10.1109/TITS.2015.2413812 |
| [22] | YU Yongtao, LI J, GUAN Haiyan, et al. Automated Detection of Three-dimensional Cars in Mobile Laser Scanning Point Clouds Using DBM-hough-forests[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(7): 4130–4142. DOI:10.1109/TGRS.2016.2537830 |
| [23] | YU Yongtao, LI J, WEN Chenglu, et al. Bag-of-visual-phrases and Hierarchical Deep Models for Traffic Sign Detection and Recognition in Mobile Laser Scanning Data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 113: 106–123. DOI:10.1016/j.isprsjprs.2016.01.005 |
| [24] | HINTON G E, OSINDERO S, TEH Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation, 2016, 18(7): 1527–1554. |
| [25] | CHO K H, ILIN A, RAIKO T. Improved Learning of Gaussian-Bernoulli Restricted Boltzmann Machines[C]//Proceedings of the 21th International Conference on Artificial Neural Networks. Espoo, Finland:Springer, 2011:10-17. |
| [26] | HINTON G E. Training Products of Experts by Minimizing Contrastive Divergence[J]. Neural Computation, 2002, 14(8): 1771–1800. DOI:10.1162/089976602760128018 |
| [27] |
方莉娜, 杨必胜.
车载激光扫描数据的结构化道路自动提取方法[J]. 测绘学报, 2013, 42(2): 260–267.
FANG Li'na, YANG Bisheng. Automated Extracting Structural Roads from Mobile Laser Scanning Point Clouds[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(2): 260–267. |
| [28] | YU Yongtao, LI J, GUAN Haiyan, et al. Automated Extraction of Urban Road Facilities Using Mobile Laser Scanning Data[J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4): 2167–2181. DOI:10.1109/TITS.2015.2399492 |
| [29] | REINGOLD O. Undirected Connectivity in Log-space[J]. Journal of the ACM, 2008, 55(4): 17. |
| [30] | SHI Jianbo, MALIK J. Normalized Cuts and Image Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888–905. DOI:10.1109/34.868688 |
| [31] | ZHONG Lishan, CHENG Liang, XU Hao, et al. Segmentation of Individual Trees From TLS and MLS Data[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(2): 774–787. DOI:10.1109/JSTARS.2016.2565519 |
| [32] | REITBERGER J, SCHNÖRR C, KRZYSTEK P, et al. 3D Segmentation of Single Trees Exploiting Full Waveform LIDAR Data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2009, 64(6): 561–574. DOI:10.1016/j.isprsjprs.2009.04.002 |
| [33] | GUAN Haiyan, YU Yongtao, LI J, et al. Pole-like Road Object Detection in Mobile LiDAR Data via Supervoxel and Bag-of-contextual-visual-words Representation[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(4): 520–524. DOI:10.1109/LGRS.2016.2521684 |