



2. 国家计算机网络应急技术处理协调中心, 北京 100029
2. National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, China
高光谱遥感图像由数十数百个波段组成,每个像元可表示为一条连续的光谱曲线,即图谱合一。目前已广泛应用于环境监测、国防建设和目标探测等领域[1-5]。由于波段数多、信息冗余多且波段间相关性强,直接进行地物分类时易出现“维数灾难”问题[3-5],致使处理过程复杂化,分类精度和分类效率明显降低。因此,如何减少数据冗余、发掘内在结构、提取有用判别信息,是提升高光谱图像分类性能的关键。
研究者们已提出一系列特征提取方法。经典方法如主成分分析(principal component analysis, PCA)[6]和线性判别分析(linear discriminant analysis, LDA)[7],均为全局线性方法。PCA以方差最大化寻求全局最佳逼近,LDA利用了样本的判别信息保持样本集的可分性;虽然它们都有效减小了数据冗余,但无法真正揭示高光谱数据集的非线性多模结构。基于流形学习的拉普拉斯映射(Laplacian eigenmap, LE)[8]和局部线性嵌入(local linear embedding, LLE)[9],能处理非线性的高维数据,但存在新样本学习问题。其线性化算法是局部保持投影(locality preserving projection, LPP)[10]和邻域保持嵌入(neighborhood preserving embedding, NPE)[11],具有良好的非线性流形学习能力,且方便处理新样本,但这类方法忽视了样本的判别信息,破坏了数据集的可分性,限制了分类精度的提高。为充分利用少量标记样本的判别信息和大量无标记样本蕴藏的非线性结构信息,半监督判别分析(semi-supervised discriminant analysis,SDA)[12]、半监督局部费舍尔判别分析(semi-supervised local Fisher discriminant analysis,SELF)[13]和半监督局部判别分析(semi-supervised local discriminant analysis,SELD)[14]等算法应运而生。这些算法充分利用少量标记样本的判别信息来保持数据集的可分性,还深入发掘未标记样本包含的局部流形结构信息或方差信息,改善了特征提取效果,提升了分类能力[15]。
以上算法只利用了光谱数据,未考虑高光谱图像数据集特有的地物空间分布结构信息对特征提取和分类的作用。高光谱数据集图谱合一,空间位置靠近的像元具有较强的光谱相关性,且距离越近,相关性越强[1-2];从地物分布看,空间近邻像元在很大概率上属于同类地物,相同类别地物在图像中往往呈现集中性或呈块状分布[16-26]。联合使用空间信息和光谱信息(简称空谱)的方式,有基于合成核分类器的多模特征融合[16]、基于图像滤波或图像分割的分类后处理[17-19]等,但这几种方式都属于在分类过程中加入空间信息。对空谱联合特征提取的研究相对较少。主要有在光谱特征、纹理特征等多模特征空间提取低维特征[20],或者对基于光谱特征空间提取的低维特征进行图像域平滑滤波[21-22],但都没有在特征提取算法函数中考虑高光谱地物的空间分布信息;文献[23-25]在流形学习构建相似图时,考虑了空间距离的影响,但无监督算法的本质,决定了此类算法无法进一步提高后续的地物分类精度。
针对以上问题,本文提出面向高光谱分类的无监督空间近邻像元均值嵌入(local pixel mean embedding, LPME)和半监督空谱判别分析(semi-supervised spatial-spectral discriminant analysis, S3DA)。通过空间近邻像元散度的最小化,最大限度保存了高光谱图像像元的空间近邻结构,实现了空间近邻像元均值嵌入;在此基础上,S3DA充分利用标记样本的判别信息来保持数据集的可分性,使同类地物像元和同一空间邻域内像元的聚集关系在投影子空间保持不变,更好揭示了高光谱图像数据集图谱合一的本质属性,从而提升分类性能。在PaviaU和Indian Pines高光谱数据集上验证了本文算法的有效性。
1 本文算法 1.1 线性判别分析(LDA)记nl个有标记的训练样本构成的样本集为
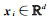
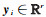
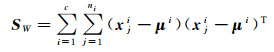 (1)
(1)
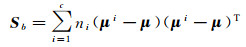 (2)
(2)
式中,c是类别数;ni是第i类的样本数;xji表示第i类的第j个样本;μi是第i类样本的均值向量,μ是样本集Xl的均值向量。
LDA的目标函数为
 (3)
(3)
最佳投影向量a即广义特征值问题Sba=λSWa的最大的非零特征值对应的特征向量。由于类间散度矩阵Sb的秩为c-1,故最多存在c-1个非零特征值和对应的特征向量,即LDA算法最多可以提取出c-1个低维嵌入特征。当nl<d时,即小样本情况下,SW是奇异矩阵,无法直接求解,必须进行正则化处理[9, 26]。
1.2 空间近邻像元均值嵌入(LPME)高光谱图像数据集具有明显的空间聚集属性,即空间上近邻的像元在很大概率上属于同类地物,其光谱特征也有较强的相似性和一致性[16-27]。为此,高光谱图像数据集的像元间的空间近邻结构,应该在投影后的特征空间中得到保持。
令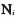
 (4)
(4)
式中,mi是以xi为中心的空间邻域
定义样本集Xl的总体散度矩阵St为
 (5)
(5)
易知St=SW+Sb。为不失一般性,将数据中心化,即Xl中所有样本减去均值向量。中心化后μ=0,St可写为St=XlXlT。
与LDA的原理类似,本文提出LPME算法,使空间近邻像元在投影后尽量靠近其均值向量,使空间近邻像元散度极小化,以保存图像的空间近邻结构和地物的空间分布信息;同时,使总体散度St最大化,最大限度保存数据的方差信息和多样化信息[27-29]。LPME的目标函数定义为
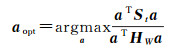 (6)
(6)
LPME利用了样本集Xl及其空间近邻像元,但没有使用Xl的标记信息,故是无监督的。最佳投影向量a即广义特征值问题Sta=λHWa的最大的非零特征值对应的特征向量。
1.3 半监督空谱判别分析(S3DA)LDA是监督算法,只能利用标记样本的光谱信息,学习得到的投影方向保存了数据集的判别信息,能够使投影子空间中同类数据更加靠近、异类数据更加分散。当LDA应用于高光谱特征提取时,无法利用高光谱图像特有的地物空间分布信息,其学习得到的子空间只反映了同类像元的光谱近邻结构(相似性关系),破坏了像元间特有的空间近邻结构。如果在特征提取过程考虑地物的空间分布信息,就能保存更多的像元间的空间近邻细节结构信息,从而降低局部空间邻域内像元在低维特征空间的波动起伏。
反之,LPME是无监督的,只能利用高光谱图像数据集的特有的地物空间分布信息,保存像元间的空间近邻结构,使提取的低维特征符合地物的空间分布规律。然而,LPME没有考虑像元的标记信息,即没有保存同类像元间的光谱近邻结构信息。对同类地物大片均匀分布区域的两个光谱近邻的同类像元,如果空间距离较远,LPME无法将其直接联系起来。为此,假如在算法中融入判别信息,就能够更好地提升投影方向的判别能力,增强低维嵌入特征的类别可分性。
由于标记样本的获取代价比较昂贵,而未标记样本数量庞大且容易获得;同时,利用标记样本只能保存图像的同类地物的光谱近邻结构,而像元的空间近邻结构只需使用未标记样本即可得到。基于此,本文提出S3DA算法。其目标函数为
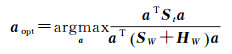 (7)
(7)
S3DA能同时利用少数标记样本和较多的未标记样本,将高光谱图像的光谱信息和空间信息自动融合,以保存光谱近邻同类像元的判别信息和空间近邻像元的分布信息;S3DA使用的未标记样本,都位于标记样本的周围,有明确的空间分布和物理解释,更符合高光谱图像数据集的本质属性,因此能够提取更有效的判别特征。由于ω2nl>d很容易满足,此时样本数大于维数,故HW很容易满秩,有效避免了奇异性。矩阵St的秩由nl和d决定,能提取的低维特征数大于c-1(当nl>c时),较多的维数能更好地表达数据集的本质特征;由于St能最大限度保存样本集的方差信息和多样化信息,有利于提升分类精度[27-29]。
在求解时,此问题转化为广义特征值问题,即
 (8)
(8)
其前r个最大特征值λ1>λ2>…λr对应的特征向量a1, a2, …, ar组成最优投影矩阵A。
1.4 LPME和S3DA求解步骤LPME和S3DA算法求解的具体步骤为:
输入:包含N个样本点的高光谱图像数据集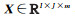
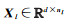
(1) 求类内散度矩阵SW。
(2) 求空间近邻像元散度矩阵HW。
(3) 求训练样本集总体散度矩阵St。
(4) 求解广义特征值问题,得到对应的特征向量a1, a2, …, ar组成的最优投影矩阵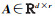
输出:低维数据Y=ATX。
2 试验数据及设置 2.1 试验数据集为评估本文LPME和S3DA的分类性能,使用具有代表性的PaviaU[19]和Indian Pines[27]高光谱遥感数据集进行分类试验。
(1) PaviaU数据集:该数据集图像是2002年由ROSIS传感器获取的航空遥感图像,地点在意大利北部Pavia大学区域。图像大小为610×340像素,空间分辨率为1.3 m;包含了430 nm到860 nm光谱范围内的115个波段,光谱分辨率为4 nm到12 nm;去除噪声影响严重的波段后,剩余103个波段。该图像参考数据样本共计42 776个,含有9类地物信息。其假彩色图像和真实地物信息如图 1所示。

|
| 图 1 PaviaU高光谱图像 Fig. 1 PaviaU hyperspectral image |
(2) Indian Pines数据集:该数据集图像由AVIRIS传感器拍摄的美国西部的农业植被区域。图像大小为145×145像素,空间分辨率为20 m;包含了400 nm到2500 nm光谱范围内的224个波段,光谱分辨率为9.7 nm到12 nm;去除噪声影响严重的波段后,剩余200个波段用于试验。该图像参考数据样本共计10 249个,含有16类地物信息。其假彩色图像和真实地物信息如图 2所示。

|
| 图 2 Indian Pines高光谱图像 Fig. 2 Indian Pines hyperspectral image |
2.2 试验设置
试验中,与Baseline、LDA、SDA、SELF、SELDlpp[14]和SELDnpe[14]等进行对比。其中Baseline是对未降维数据直接分类的结果,LDA是经典的监督算法,SDA、SELF、SELDlpp和SELDnpe是半监督算法。为避免小样本时出现奇异,LDA的类内散度矩阵SW加上了单位矩阵正则项,正则系数设置为10-3。SDA的参数α和SELF的参数β分别在{0.1, 0.5, 2.5, 12.5, 62.5}和{0, 0.1, 0.2, …, 0.9, 1.0}中选取,使分类精度最优。SDA、SELDlpp和SELDnpe在构建近邻图时,光谱近邻数k设置为5。S3DA和LPME的空间邻域ω设置为3。LDA、SDA提取的低维特征数量为c-1,其余算法的嵌入维数上界均设置为30。
在学习投影矩阵时,训练样本包括标记样本集
在分类时,所有算法均使用Xl作为训练样本,剩余全部样本均为测试样本。使用最近邻分类器(nereast neighbor,NN),并采用总体精度(overall accuracy, OA)、平均精度(average accuracy,AA)和Kappa系数作为评价指标。为提高实验的精确度和可靠性,重复进行10次,每次随机选取训练样本,将10次试验的分类精度求平均值。
3 试验结果及分析 3.1 PaviaU试验结果及分析根据试验设置,图 3为各算法在PaviaU数据集上不同维数下的分类精度曲线,表 1为不同标记样本数下的最大总体分类精度。

|
| 图 3 不同算法在不同标记样本、不同维数下的分类精度 Fig. 3 Overall accuracies of different algorithms with different labeled samples in different dimensions |
| (%) | ||||||||
| 标记样本 | Baseline | LDA | SDA | SELF | SELDlpp | SELDnpe | LPME | S3DA |
| 5 | 56.81±4.52 | 56.28±4.65 | 62.35±5.15 | 57.05±4.50 | 60.38±4.35 | 60.20±4.62 | 63.03±5.85 | 66.10±6.06 |
| 10 | 62.07±3.18 | 52.21±3.32 | 69.10±3.92 | 62.41±3.22 | 67.94±3.02 | 68.12±2.92 | 71.74±4.27 | 73.53±4.06 |
| 15 | 64.15±3.04 | 60.28±2.24 | 72.22±3.60 | 64.56±3.01 | 71.04±2.25 | 71.06±2.57 | 75.95±1.67 | 77.71±1.36 |
| 20 | 66.74±2.58 | 62.94±2.00 | 74.88±2.04 | 67.24±2.51 | 74.16±1.57 | 74.30±1.06 | 78.01±1.45 | 79.03±1.60 |
| 25 | 67.20±1.22 | 68.41±2.01 | 75.91±1.97 | 67.78±1.16 | 75.05±1.40 | 75.39±1.37 | 79.50±1.64 | 80.79±1.60 |
| 30 | 69.45±1.35 | 69.61±1.09 | 77.94±1.85 | 70.09±1.25 | 78.48±0.95 | 78.27±0.77 | 80.44±1.14 | 81.50±0.99 |
由图 3可知,随着嵌入维数的增加,各算法的分类精度不断增加,并逐渐达到最大值,之后不再升高,或者逐步降低。这是由于各个算法在本征维数时取得最优的分类精度,而嵌入在高维数据中的本征维数是未知的、不可确定的。当低维嵌入特征逐步增加时,其包含的判别信息越来越丰富,分类精度也相应地变大;但当达到本征维数时,分类精度取得最优值;此时,如果嵌入特征的维数再增加,有可能引入冗余信息或噪声,致使分类精度不再提高,甚至逐渐降低。由图可知,保留30个低维嵌入特征时,各算法均取得了最大分类精度,满足了分类任务的要求。
在表 1中,当每类地物取5、10、15、20、25、30个标记训练样本(对样本数不足50个的类别,最多选取一半)和300个未标记训练样本的情况下(S3DA使用的未标记样本是标记样本的8倍,即40、80、120、160、200、240个),各算法的最大总体分类精度随着标记样本数的增加而增加,这是因为标记样本越多,包含的标记信息越丰富,提取的低维特征的判别能力越强,其分类精度越好。在不同的标记样本数目下,相比其他算法,S3DA的分类精度始终是最高的,LPME仅次于S3DA。LPME比其他算法提高约2%~7%,S3DA高出其余算法约3%~10%,且S3DA始终高于LPME约1%~3%;同时,训练样本越少,S3DA相对LPME的分类精度提升越明显。
这是因为,LDA使数据集的类内散度最小化,即同类的光谱近邻像元在投影后靠近其均值向量,保存了高光谱图像的光谱近邻结构和同类地物的光谱相似性关系;SDA、SELF、SELDlpp和SELDnpe等算法,在LDA的基础上还保存了流形结构等信息,但他们都没有考虑高光谱图像的空间聚集属性。而本文的LPME算法,能使高光谱图像的空间近邻像元散度极小化,即空间近邻像元在投影后靠近其均值向量,保存了像元间的空间近邻结构和地物的空间分布信息,从而达到了较高的分类精度。S3DA集成了LDA和LPME的优势,同时利用了标记样本和无标记样本,不仅通过类内散度极小化保证投影子空间的类别可分性,还保存了图像的空间近邻结构,增强了同类像元和同一空间邻域像元的在低维空间的聚集性,使提取的低维特征更符合高光谱图像数据集的本质属性,从而强化了判别能力,改善了特征提取效果。
表 2是选取30个标记样本时各类地物的分类精度。S3DA和LPME在大部分地物类别都具有较好的分类效果,尤其是“Meadows”和“Bare Soil”的分类精度比其余算法提高约5%~25%,这是因为这两类地物在图像中呈大片块状均匀分布,有利于S3DA和LPME提取出更有判别力的低维特征。图 4为对应的分类图,可以看出S3DA和LPME获得了更多光滑区域,尤其是在图中圆圈所示的“Bare Soil”区域,错分点明显减少。但是,空间聚集特性的引入,也使得部分错分点呈块状分布,即错分像元的空间近邻像元也倾向于被错分,这在实际应用中需要加以注意。
| (%) | ||||||||||
| 序号 | 类别 | 训练样本 | 测试样本 | LDA | SDA | SELF | SELDlpp | SELDnpe | LPME | S3DA |
| 1 | Asphalt | 30 | 6601 | 58.75 | 72.65 | 68.24 | 71.39 | 67.12 | 69.51 | 69.34 |
| 2 | Meadows | 30 | 18 619 | 72.29 | 75.31 | 65.31 | 77.27 | 78.85 | 80.62 | 82.59 |
| 3 | Gravel | 30 | 2069 | 58.84 | 71.59 | 62.26 | 70.79 | 68.02 | 71.31 | 71.18 |
| 4 | Trees | 30 | 3034 | 90.66 | 90.35 | 88.29 | 89.31 | 90.03 | 92.25 | 92.37 |
| 5 | Metal Sheets | 30 | 1315 | 99.48 | 99.57 | 99.14 | 99.61 | 99.57 | 99.81 | 99.82 |
| 6 | Bare Soil | 30 | 4099 | 65.03 | 78.80 | 65.26 | 78.09 | 80.06 | 92.21 | 92.63 |
| 7 | Bitumen | 30 | 1300 | 58.53 | 89.38 | 87.82 | 93.42 | 91.33 | 86.57 | 85.40 |
| 8 | Bricks | 30 | 3652 | 56.52 | 75.67 | 69.45 | 75.00 | 71.41 | 64.53 | 66.90 |
| 9 | Shadows | 30 | 917 | 97.80 | 99.96 | 99.95 | 99.97 | 99.86 | 99.97 | 99.93 |
| 总体精度(OA) | - | - | 69.61 | 77.94 | 70.09 | 78.48 | 78.27 | 80.44 | 81.50 | |
| Kappa系数 | - | - | 61.42 | 71.86 | 62.30 | 72.43 | 72.15 | 75.01 | 76.28 | |
| 平均精度(AA) | - | - | 73.10 | 83.70 | 78.41 | 83.87 | 82.91 | 84.09 | 84.46 | |

|
| 图 4 在PaviaU上各算法的分类识别图 Fig. 4 Classification maps of different algorithms in PaviaU data set |
3.2 Indian Pines试验结果及分析
在Indian Pines数据集上也进行了试验,图 5为各算法在不同标记样本下不同维数下的分类精度曲线,表 3为对应的最高总体分类精度。

|
| 图 5 不同算法在不同标记样本、不同维数下的分类精度 Fig. 5 Overall accuracies of different algorithms with different labeled samples in different dimensions |
| (%) | ||||||||
| 标记样本 | Baseline | LDA | SDA | SELF | SELDlpp | SELDnpe | LPME | S3DA |
| 5 | 42.95±3.03 | 43.42±3.09 | 44.64±3.25 | 49.03±3.71 | 42.33±2.93 | 42.78±2.64 | 53.77±3.43 | 57.08±3.51 |
| 10 | 49.41±2.22 | 48.20±2.56 | 51.95±2.32 | 56.29±2.23 | 49.27±2.42 | 50.20±2.26 | 59.19±1.93 | 61.32±1.74 |
| 15 | 51.45±2.16 | 51.14±2.02 | 56.20±1.73 | 59.98±2.14 | 52.15±1.46 | 54.09±1.64 | 63.91±2.32 | 66.05±2.11 |
| 20 | 54.77±1.89 | 54.95±2.86 | 60.24±1.53 | 62.90±1.56 | 55.58±1.40 | 57.65±1.53 | 68.11±1.66 | 69.15±1.43 |
| 25 | 56.46±1.24 | 58.76±1.61 | 62.19±1.95 | 63.88±0.50 | 57.20±0.89 | 59.92±0.88 | 68.63±1.33 | 69.63±1.14 |
| 30 | 57.15±1.60 | 60.27±1.44 | 63.96±1.59 | 65.31±1.36 | 58.30±0.96 | 61.08±1.28 | 70.79±0.83 | 71.77±0.57 |
从图 5和表 3可以看出,其他几种算法的分类精度均低于本文提出的LPME和S3DA。在不同的标记样本数下,LPME比其他算法提高约5%~10%,S3DA高出其余算法约6%~14%,且S3DA始终高于LPME约1%~4%。同时,训练样本越少,S3DA相比LPME的分类精度提升也越明显。
这是因为LDA在线性二分类问题中应用效果较好,但本数据集具有多模非线性属性,虽然它能够保证不同类别数据的可分性和同类数据的聚集性,却无法利用高光谱数据集特有的空间信息;SDA、SELF、SELDlpp和SELDnpe等半监督算法,充分利用了标记样本的判别信息,保持了数据集的可分性,且通过较多的未标记样本挖掘数据集的光谱近邻流形结构或最大的方差信息,保存了数据集的非线性属性,但他们利用的未标记样本均是随机选取的,其潜在分布是未知的,也没有明确的物理意义,无法符合高光谱图像中不同地物的空间分布规律。反之,S3DA使用的未标记样本,是标记样本的空间近邻像元,有明确的空间分布和物理意义,更符合高光谱图像数据集的本质属性,使同类像元和空间近邻像元的相似性和聚集性在投影子空间保持不变,因此能够提取更有效的判别特征,取得更高的分类精度。
3.3 空间邻域大小与无标记样本数的影响S3DA利用空间近邻的无标记样本来保存图像的空间近邻结构,故空间邻域大小ω与S3DA利用的无标记样本数有直接的对应关系;同时,由于无标记样本的选取有明确物理意义,故无标记样本数量受空间邻域大小限制,无法自由选择。在Indian Pines和PaviaU数据集中选取30个标记训练样本进行试验。试验中,ω分别选取为3、5、7、9、11、13,即选取的无标记样本总数为240、720、1440、2400、3600、5024。
图 6是不同ω时的分类精度。由图 6可知,随着ω值的增加,尽管无标记样本数在增加,但S3DA的分类精度却逐步下降。这是因为随着ω值增加,空间邻域内的像元逐步增加,与中心像元距离逐步增大,属于同类地物的概率逐渐变小,即属于异类地物的概率逐步增大,像元的均值向量偏离了同类地物的典型光谱特征,使像元在投影后也偏离了同类地物,故分类精度不断降低。由图 6可知,当ω值较小时,即选取较少的无标记样本时,分类精度最高;这意味着较少的计算量,在实际应用中具有重要意义。

|
| 图 6 不同ω值下的分类精度 Fig. 6 Overall accuracies with different ω |
3.4 时间复杂度分析
LDA的复杂度分别为O((nl+c)d2);SDA将数据集的流形结构信息引入LDA,复杂度为O((nl+c)d2+nud2+2nu2d);SELDlpp和SELDnpe集成了LDA的判别能力和LPP、NPE的流形结构保存能力,复杂度为O(nld2+3nu2d+2nud2),SELDnpe计算重构系数额外还需要O(nudk3);SELF充分利用了样本的方差信息,复杂度为O(3nl2d+2nld2+nud2)。本文算法LPME和S3DA的复杂度分别为O(ω2nld2)和O((ω2nl+nl+c)d2),主要取决于空间邻域ω、波段数d和标记样本总数nl。
由于nu通常大于nl,故SDA、SELF、SELDlpp、SELDnpe的计算量相对较大,LDA和本文S3DA、LPME的计算代价较小。试验硬件平台为Intel(R) Core(TM) i7-2600 3.40 GHz CPU和16.0 GB RAM,软件版本为Matlab7.0。
以选取30个标记样本为例。表 4是各算法的运行时间。本文S3DA和LPME的运行时间大于LDA,但小于SDA、SELF、SELDlpp和SELDnpe,这与复杂度分析的结论一致。由于Indian Pines数据集的波段数是PaivaU的近2倍,且地物类别较多,每次选取的样本总数也较多,故Indian Pines数据集上各算法耗时比PaviaU数据集多。表中SELF的运行时间最长,这主要是因为程序设计的原因。
| s | |||||||
| Data sets | LDA | SDA | SELF | SELDlpp | SELDnpe | LPME | S3DA |
| PaviaU | 0.007 | 0.44 | 1.94 | 0.37 | 0.76 | 0.07 | 0.16 |
| Indian Pines | 0.009 | 0.77 | 4.88 | 0.61 | 1.21 | 0.13 | 0.23 |
4 结论
本文结合高光谱图像的图谱合一特性,提出了面向高光谱分类的无监督空间近邻像元均值嵌入和半监督空谱判别分析算法。该算法利用少量标记样本和较多的无标记空间近邻样本,通过类内散度矩阵和空间近邻像元散度矩阵极小化,使标记样本包含的判别信息和无标记样本蕴藏的空间近邻结构在投影子空间得以保存,强化了同类像元和空间近邻像元的聚集性,在特征提取过程中自动融入空间信息,提取了更有效的判别特征,提升了分类性能。在PaviaU和Indian Pines高光谱数据集的试验表明,总体分类精度分别达到81.50%和71.77%。与传统特征提取算法相比,分类精度有了明显地提升。
但本文算法只考虑了高光谱图像的判别能力和空间分布特性,没有考虑高维数据蕴藏的非线性流形结构,如何将三者同时结合起来提取更有效的特征,是下一步研究的内容。
| [1] | FAUVEL M, TARABALKA Y, BENEDIKTSSON J A, et al. Advances in Spectral-Spatial Classification of Hyperspectral Images[J]. Proceedings of the IEEE, 2013, 101(3): 652–675. DOI:10.1109/JPROC.2012.2197589 |
| [2] | 黄鸿, 郑新磊. 高光谱影像空-谱协同嵌入的地物分类算法[J]. 测绘学报, 2016, 45(8): 964–972. HUANG Hong, ZHENG Xinlei. Hyperspectral Image Land Cover Classification Algorithm Based on Spatial-spectral Coordination Embedding[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(8): 964–972. DOI:10.11947/j.AGCS.2016.20150654 |
| [3] | 杨钊霞, 邹峥嵘, 陶超, 等. 空-谱信息与稀疏表示相结合的高光谱遥感影像分类[J]. 测绘学报, 2015, 44(7): 775–781. YANG Zhaoxia, ZOU Zhengrong, TAO Chao, et al. Hyperspectral Image Classification Based on the Combination of Spatial-Spectral Feature and Sparse Representation[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(7): 775–781. DOI:10.11947/j.AGCS.2015.20140207 |
| [4] | 骆仁波, 皮佑国. 有监督的邻域保留嵌入的高光谱遥感影像特征提取[J]. 测绘学报, 2014, 43(5): 508–513. LUO Renbo, PI Youguo. Supervised Neighborhood Preserving Embedding Feature Extraction of Hyperspectral Imagery[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(5): 508–513. DOI:10.13485/j.cnki.11-2089.2014.0079 |
| [5] | 李志敏, 张杰, 黄鸿, 等. 面向高光谱图像分类的半监督Laplace鉴别嵌入[J]. 电子与信息学报, 2015, 37(4): 995–1001. LI Zhimin, ZHANG Jie, HUANG Hong, et al. Semi-Supervised Laplace Discriminant Embedding for Hyperspectral Image Classification[J]. Journal of Electronics & Information Technology, 2015, 37(4): 995–1001. DOI:10.11999/JEIT140600 |
| [6] | JACKSON J E. A User's Guide to Principal Components[M]. New York: A Wiley-Interscience Publication, 1992. |
| [7] | BANDOS T V, BRUZZONE L, CAMPS-VALLS G. Classification of Hyperspectral Images with Regularized Linear Discriminant Analysis[J]. IEEE Transactions on Geoscience and Remote Sensing, 2009, 47(3): 862–873. DOI:10.1109/TGRS.2008.2005729 |
| [8] | BELKIN M, NIYOGI P. Laplacian Eigenmaps for Dimensionality Reduction and Data Representation[J]. Neural Computation, 2003, 15(6): 1373–1396. DOI:10.1162/089976603321780317 |
| [9] | ROWEIS S T, SAUL L K. Nonlinear Dimensionality Reduction by Locally Linear Embedding[J]. Science, 2000, 290(5500): 2323–2326. DOI:10.1126/science.290.5500.2323 |
| [10] | HE Xiaofei, NIYOGI P.Locality Preserving Projections[C]//Advances in Neural Information Processing Systems.Cambridge:MIT Press, 2004(16):153-160. |
| [11] | HE Xiaofei, CAI Deng, YAN Shuicheng, et al.Neighborhood Preserving Embedding[C]//Proceedings of the 10th IEEE International Conference on Computer Vision.Beijing:IEEE, 2005:150-156. |
| [12] | CAI Deng, HE Xiaofei, HAN Jiawei.Semi-supervised Discriminant Analysis[C]//Proceedings of the 11th IEEE International Conference on Computer Vision.Rio de Janeiro:IEEE, 2007:1-7. |
| [13] | SUGIYAMA M, IDÉ T, NAKAJIMA S, et al. Semi-supervised Local Fisher Discriminant Analysis for Dimensionality Reduction[J]. Machine Learning, 2010, 78(1-2): 35–61. DOI:10.1007/s10994-009-5125-7 |
| [14] | LIAO Wenzhi, PIZURICA A, SCHEUNDERS P, et al. Semisupervised Local Discriminant Analysis for Feature Extraction in Hyperspectral Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 51(1): 184–198. DOI:10.1109/TGRS.2012.2200106 |
| [15] | LUO Renbo, LIAO Wenzhi, HUANG Xin, et al. Feature Extraction of Hyperspectral Images with Semisupervised Graph Learning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2016, 9(9): 4389–4399. DOI:10.1109/JSTARS.2016.2522564 |
| [16] | LI Jun, MARPU P R, PLAZA A, et al. Generalized Composite Kernel Framework for Hyperspectral Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 51(9): 4816–4829. DOI:10.1109/TGRS.2012.2230268 |
| [17] | KANG Xudong, LI Shutao, BENEDIKTSSON J A. Spectral-Spatial Hyperspectral Image Classification with Edge-preserving Filtering[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(5): 2666–2677. DOI:10.1109/TGRS.2013.2264508 |
| [18] | TARABALKA Y, BENEDIKTSSON J A, CHANUSSOT J. Spectral-spatial Classification of Hyperspectral Imagery Based on Partitional Clustering Techniques[J]. IEEE Transactions on Geoscience and Remote Sensing, 2009, 47(8): 2973–2987. DOI:10.1109/TGRS.2009.2016214 |
| [19] | LI Jun, BIOUCAS-DIAS J M, PLAZA A. Spectral-Spatial Hyperspectral Image Segmentation Using Subspace Multinomial Logistic Regression and Markov Random Fields[J]. IEEE Transactions on Geoscience and Remote Sensing, 2012, 50(3): 809–823. DOI:10.1109/TGRS.2011.2162649 |
| [20] | WEN Jinhua, FOWLER J E, HE Mingyi, et al. Orthogonal Nonnegative Matrix Factorization Combining Multiple Features for Spectral-Spatial Dimensionality Reduction of Hyperspectral Imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(7): 4272–4286. DOI:10.1109/TGRS.2016.2539154 |
| [21] | KANG Xudong, LI Shutao, BENEDIKTSSON J A. Feature Extraction of Hyperspectral Images with Image Fusion and Recursive Filtering[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(6): 3742–3752. DOI:10.1109/TGRS.2013.2275613 |
| [22] | XIA Junshi, BOMBRUN L, ADALI T, et al. Spectral-Spatial Classification of Hyperspectral Images Using ICA and Edge-Preserving Filter via an Ensemble Strategy[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(8): 4971–4982. DOI:10.1109/TGRS.2016.2553842 |
| [23] | 魏峰, 何明一, 梅少辉. 空间一致性邻域保留嵌入的高光谱数据特征提取[J]. 红外与激光工程, 2012, 41(5): 1249–1254. WEI Feng, HE Mingyi, MEI Shaohui. Hyperspectral Data Feature Extraction Using Spatial Coherence Based Neighborhood Preserving Embedding[J]. Infrared and Laser Engineering, 2012, 41(5): 1249–1254. |
| [24] | PU Hanye, CHEN Zhao, WANG Bin, et al. A Novel Spatial-Spectral Similarity Measure for Dimensionality Reduction and Classification of Hyperspectral Imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(11): 7008–7022. DOI:10.1109/TGRS.2014.2306687 |
| [25] | LUNGA D, PRASAD S, CRAWFORD M M, et al. Manifold-Learning-based Feature Extraction for Classification of Hyperspectral Data:A Review of Advances in Manifold Learning[J]. IEEE Signal Processing Magazine, 2014, 31(1): 55–66. DOI:10.1109/MSP.2013.2279894 |
| [26] | YUAN Haoiang, TANG Yuanyan, LU Yang, et al. Spectral-Spatial Classification of Hyperspectral Image Based on Discriminant Analysis[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014, 7(6): 2035–2043. DOI:10.1109/JSTARS.2013.2290316 |
| [27] | ZHOU Yicong, PENG Jiangtao, CHEN C L P. Dimension Reduction Using Spatial and Spectral Regularized Local Discriminant Embedding for Hyperspectral Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(2): 1082–1095. DOI:10.1109/TGRS.2014.2333539 |
| [28] | GAO Quanxue, MA Jingjie, ZHANG Hailin, et al. Stable Orthogonal Local Discriminant Embedding for Linear Dimensionality Reduction[J]. IEEE Transactions on Image Processing, 2013, 22(7): 2521–2531. DOI:10.1109/TIP.2013.2249077 |
| [29] | WEINBERGER K Q, SAUL L K.An Introduction to Nonlinear Dimensionality Reduction by Maximum Variance Unfolding[C]//Proceedings of the 21st Association on Advances in Artificial Intelligence.Boston, MA:AAAI, 2006:1683-1686. |