



2. 武汉大学遥感信息工程学院, 湖北 武汉 430079
2. School of Remote Sensing and Information Engineering, Wuhan University, Wuhan 430079, China
湿地在调节气候、维持区域生态平衡以及提供野生动植物栖息地等方面具有重要作用。湿地的类型多种多样,通常分为自然和人工两大类。自然湿地包括沼泽地、泥炭地、湖泊、河流、海滩和盐沼等,人工湿地主要有水稻田、水库、池塘等[1-2]。湿地生态系统具有覆盖范围广、难以直接接近等特点,传统的地面实测方法耗时长且效率低,而遥感技术能够宏观、动态地提取地表信息,利用遥感技术进行湿地检测和信息提取受到越来越多国内外学者的关注[3-5]。
当前,湿地信息提取主要采用的是中、低分辨率的遥感影像[6-7],利用高分辨率遥感影像进行湿地信息提取难以得到令人满意的结果,主要原因在于:① 湿地在高分辨率遥感影像中表现为植被、土壤和水体组成的复杂场景,无论是基于像元还是面向对象的方法都难以得到较完整的提取结果;② 湿地常常与林地、水体和低矮灌木发生混淆,容易受到“同物异谱”和“异物同谱”现象的干扰[8]。
因此,将高分辨率影像和多光谱影像、SAR等多源遥感数据进行结合,能克服单一数据源的局限性,提高湿地信息提取的精度[9-11]。并且,利用多源遥感数据可以提取土壤含水量、地表温度、植被指数等地表环境参数,使得湿地信息提取的结果更加准确[12-14]。
使用多源遥感数据容易造成特征维度的增加,带来的冗余及噪声会降低分类过程的效率,引起分类的混淆,并导致分类精度降低。面对多源遥感数据的湿地信息提取,如果不能对高维特征空间进行有效的遴选与组合,难以得到令人满意的精度。概率潜在语义分析(probabilistic latent semantic analysis, pLSA)[15]是一种文本分析方法,可以有效地进行特征降维和特征组合,并能够解决分类过程中的“同物异谱”和“异物同谱”现象,目前已成功应用于遥感图像的识别和分类中[16-17]。
本文将高分辨率遥感影像中的湿地看作是由水体、土壤和低矮灌木等多种地物组成的复杂场景,结合LandSat和MODIS等多光谱遥感图像提取湿地的光谱、纹理、地物组成成分、地表温度和土壤含水量等特征,利用概率潜在语义分析构建湿地场景的语义特征空间,最后利用SVM分类器实现湿地场景的检测。
通过试验表明,pLSA能够有效地对湿地的高维特征空间进行特征降维和特征组合;土壤含水量、地表温度等环境特征的加入能更加有效地表征湿地特征,提高湿地检测精度。
1 pLSA简介pLSA是Hoffman针对潜在语义分析(latent semantic analysis, LSA)提出的一种数据生成模型,其基本思想是根据词汇表中单词出现的频率发掘文本集中的主题[15, 18]。假定一组由特征集W={w1, w2, …, wM}描述的目标集O={o1, o2, …, oN},并由此组成一个N×M的特征频率矩阵N=(n(oi, wj))ij,n(oi, wj)表示特征wj在目标oi中出现的频率。此外,每一对可视数据(oi, wj)与一组潜在成分(主题)Z={z1, z2, …, zK}相关, K为人工指定的一个常数。
假设:oi和wj之间是条件独立的,并且潜在成分zk在目标和特征集上的分布也是条件独立的。则用于表述目标中特征内容的生成模型P(oi, wj)可以通过式(1) 和式(2) 计算得到
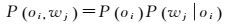 (1)
(1)
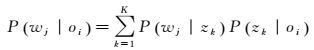 (2)
(2)
式中,P(oi)表示目标oi的出现概率;P(wj|zk)表示潜在成分zk在特征wj上的概率密度;P(zk|oi)表示目标oi在潜在成分zk上的概率密度。
根据极大似然估计,通过求取式(3) 定义的对数-似然函数的极大值,计算pLSA模型的参数P(wj|zk)和P(zk|oi)
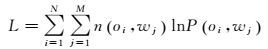 (3)
(3)
在pLSA模型中,极大似然估计的标准过程是期望最大(expectation maximization)算法。EM算法交替于两个步骤:① E-步,利用当前估计的参数值计算潜在成分变量的后验概率;② M-步,基于所给后验概率,更新参数值。对于pLSA模型,应用贝叶斯公式即可得到E-步,如下
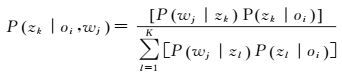 (4)
(4)
通过极大化式(4),重新估计参数P(wj|zk)和P(zk|oi),得M-步
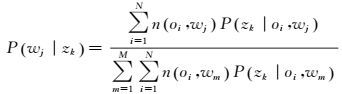 (5)
(5)
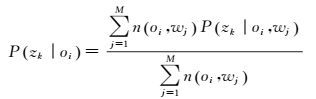 (6)
(6)
在使用随机数初始化之后,交替实施E步骤和M步骤进行迭代计算,直至式(7) 定义的E(L)达到收敛。
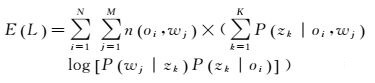 (7)
(7)
试验区选择湖北省孝感市大悟县,获取2014年3月Quickbird高分辨率影像,大小为8310×3945像素,面积为11 834.945 km2。同时获取与高分辨率影像对应的同时期的LandSat 8和MODIS影像,多源遥感数据的详细信息以及在湿地检测中的作用如表 1所示。
| 数据 | 分辨率/m | 获取时间 | 采用的通道 | 作用 |
| QuickBird | 0.61 | 2014-03-27 | 近红外、红、绿光 | 提取光谱、纹理和地物组成成分 |
| LandSat 8 | 30 | 2014-04-29 | TIRS 10 | 反演环境特征 |
| MODIS | 1000 | 2014-03-27 | 通道2和19 | 计算大气透过率 |
为了在提高影像空间分辨率的同时保留图像的光谱信息,采用Gram-Schmidt图像融合方法,分别将Quickbird影像和LandSat 8影像的近红外、红光和绿光通道与全色波段进行融合,该方法能够较好保持空间纹理信息,在损失信息量较少的前提下,保留图像的光谱信息。获得空间分辨率为0.61 m和15 m分辨率的融合后影像,如图 1所示。

|
| 图 1 试验区影像 Fig. 1 Images for experiment |
试验区内主要地物为:道路、居民地、低矮灌木、林地、湖泊、河流等。考虑到城市湿地受人类影响的特殊性和复杂性,本文所检测的城市湿地类型主要包含3大类,如表 2所示。
| 类型 | 描述 |
| 自然湿地 | 保留河床、河道、河漫滩的河流,与地下水连通的湖泊等 |
| 半人工湿地 | 运河、渠道、水稻田等 |
| 人工湿地 | 养殖池塘、景观和娱乐水面等 |
2.2 特征提取
提取图像光谱、纹理、地物组成成分和地表环境4种类型的特征,如表 3所示。
| 特征 | 特征描述 |
| 光谱 | 近红外、红光、绿光通道的光谱 |
| 纹理 | LBP纹理 |
| 地物组成成分 | 5种地物类型的频率分布 |
| 环境特征 | 地表温度、土壤含水量 |
2.2.1 纹理特征提取
局部二进制模式(local-binary-pattern,LBP)[19]是一种纹理描述算子,该算子计算局部窗口内像素的局部空间结构和灰度反差,并采用统计分析的方法来描述纹理。其定义如下
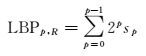 (8)
(8)
式中
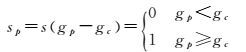 (9)
(9)
式中, p表示半径为R时邻域点的个数;gc为中心点的灰度值;gp为邻域点灰度值。按照该方法得到的二进制模式较多,对于纹理的表达不利,因此,本文采用了等价模式LBP(uniform-pattern LBP)[20],即当某个LBP所对应的循环二进制数从0到1或从1到0最多有两次跳变时,该LBP所对应的二进制就称为一个等价模式类,其余模式都归为另一类,由此得到的二进制模式种类大大减少,相比GLCM、HOG等方法,得到的特征向量维数较少,减少了高频噪声带来的影响且计算复杂度低。
对于高分辨率影像,纹理在不同波段上具有高度的一致性,将各波段影像求均值得到灰度影像,并对此灰度影像的3×3邻域进行采样,计算后得到59维的纹理特征向量。LBP纹理反映了每个像元与周围像元的关系,描述了研究区域内湿地的纹理信息。
2.2.2 地物组成成分特征提取研究区内湿地主要由土壤、水体和低矮灌木3种地物类型组成,分析湿地中土壤、水体和低矮灌木这3种地物类型的频率分布有助于表征湿地的地物特征。然而研究区域除了这3种地物类型,还包括不渗水面和林地,为了不影响湿地地物类型的统计,同时分类更加精细,本文用决策树模型将QuickBird影像分成水体、林地、低矮灌木、裸土和不渗水面5种地物类型,如图 2(a)所示。将研究区内的湿地看作是由水体、土壤和低矮灌木等多种地物组成的场景,在图像场景窗口中分别统计5类地物出现的概率,将其作为湿地场景的地物组成成分特征。对整个研究区以及其中的湿地场景、非湿地场景样本中的5种地物类型分别出现的概率统计结果如图 2(b)所示。

|
| 图 2 分类结果和不同地物类别的概率 Fig. 2 Classification results and probability of different subclasses |
2.2.3 环境特征提取
湿地具有较茂密的植被和丰沛的水源,因此对周围环境有显著降温作用,土壤含水量也明显高于非湿地,本文提取研究区的地表温度和土壤含水量作为湿地的环境特征。由于QuickBird影像只有近红外、红、绿和蓝光4波段,无法反演湿地的环境特征,因此本文利用同时期LandSat 8和MODIS影像进行湿地地表温度、土壤含水量等环境特征的反演。
LandSat 8卫星自发射以来,其TIRS传感器第11波段的定标精度一直达不到预定目标,不适合使用劈窗算法来对LandSat 8数据做地表温度反演。因此本文中的地表温度利用LandSat 8影像和MODIS影像使用单窗算法反演得到[21],如式(10) 所示
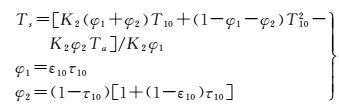 (10)
(10)
式中,Ts是地表温度;T10为LandSat 8的TIRS10的亮度温度;Ta为大气平均作用温度(K);K2为常数1 321.08;ε10表示地表等效比辐射率;τ10表示大气透过率。
亮度温度利用定标系数对图像DN值进行辐射定标,将像元的DN值转换为大气层上界光谱辐射亮度,之后用普朗克公式反推得到,公式如下
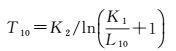 (11)
(11)
式中,K1、K2为常数;L10为大气层上界光谱辐射亮度。
根据研究区所处位置,大气平均作用温度选择中纬度夏季模式的大气平均作用温度估算公式,如下所示
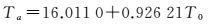 (12)
(12)
式中,T0为研究区地面观测得到的近地表空气温度。
地表等效比辐射率的计算考虑地物由裸土、水体和植被3种地物类型组成,通过3种地物类型的组成成分和植被、裸土和水体的比辐射率计算像元的等效比辐射率,如式(13) 所示
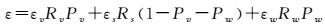 (13)
(13)
式中,εv、εs、εw分别表示植被、裸土和水体的比辐射率,εv=0.984 4,εs=0.973 1,εw=0.992;Rw、Rv和Rs分别是水体、植被和裸土的温度比率,根据经验估计分别取值为0.995 65、0.992 4、1.007 44;Pw和Pv分别是水体和植被在像元内的构成比例,采用基于NDVI的像元二分模型计算获得。
大气透过率通过同时期的MODIS数据反演获得。利用MODIS数据第2和19波段计算大气水汽含量,根据大气透过率和大气水含量之间存在的关系拟合得到大气透过率。
土壤含水量反演使用条件植被温度指数(vegetation temperature condition index, VTCI)法,如下
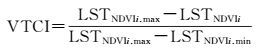 (14)
(14)
式中
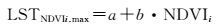 (15)
(15)
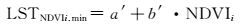 (16)
(16)
式中,LSTNDVIi.max、LSTNDVIi.min分别表示在研究区内,当NDVI值等于某一特定值时的地表温度的最大值和最小值;a、b、a′、b′为待定系数,通过做研究区内的NDVI和LST的散点图近似获得。
VTCI可在理论上解释为当NDVI值相等时,LST差异大小的比率。VTCI的值越小,干旱程度越严重。LSTmax被认为是热边界(warm edge),在此边界上土壤水分的有效性很低,干旱程度最为严重;LSTmin为冷边界(cold edge),在此边界上土壤水分不是植物生长的限制因素,因此植被供水指数可以表征地物的土壤含水量。
将地表温度和土壤含水量反演结果进行重采样后和QuickBird影像进行配准,并对地表温度和土壤含水量反演结果进行聚类,划分为5个等级,如图 3所示。分别统计每一等级在湿地场景内出现的频率,将其作为湿地的环境特征。对试验区样本的环境特征按照不同等级的概率进行统计,如图 4所示,可以看出湿地和非湿地在环境特征上是存在显著差别的。

|
| 图 3 湿地环境数据反演结果 Fig. 3 Inversion results of environment data in wetland |

|
| 图 4 环境特征概率统计 Fig. 4 Probability statistics of environment features |
2.3 基于pLSA的湿地信息提取
采用目视判别与实地调研相结合的方法,在试验区图像上进行湿地(正样本)与非湿地(负样本)ground truth的标注,分别如图 5(a)和5(b)所示。为了符合正负样本实际分布情况,负样本的个数要多于正样本,最终选取的正负样本数分别为204、462个。按照1:1的比例分配训练样本和测试样本,分别将其中的102、231个作为训练,其余的作为测试。

|
| 图 5 试验区ground truth Fig. 5 Experimental area ground truth |
提取样本的5种类型特征,得到特征频率矩阵,用pLSA模型中的EM算法对所有训练样本的特征频率矩阵进行计算,算法收敛后得到特征的概率密度分布P(wj|zk),同时,每个训练样本用一个K维潜语义向量P(zk|oitrain)来表示。根据得到的每一组概率密度分布P(zk|oitrain)及其对应的标注结果训练SVM分类器。
保持由训练集得到的P(wj|zk)不变,得到该区域的P(zk|oitest)。再使用训练好的SVM分类器对新窗口中产生的每一组P(zk|oitest)进行判别得到对应区域最终的识别结果,如图 6所示,灰色框所覆盖的区域为湿地检测结果。

|
| 图 6 Quickbird影像湿地检测结果 Fig. 6 Wetland detection result from Quickbird image |
3 试验结果分析
本文采用查准率(precision)、查全率(recall)和正确率(accuracy)来评价主题数目和多种特征的使用对湿地目标检测精度的影响[22-23],以及来衡量本文提出的方法与传统方法检测性能的好坏。其中,查全率反映了湿地检测的完整性,查准率反映了湿地检测的准确度,正确率反映了利用pLSA模型进行湿地检测的综合正确性,如式(17)—式(19) 所示。为了参照实际湿地分布情况检验本文方法的效果,专门进行了针对试验区的实地考察。经过考察在研究区影像上标注为湿地和非湿地区域的数目为E和E′,利用本文方法检测为湿地区域的数目为M,其中, R个是正确的,利用本文方法判别为非湿地区域的数目中R′个是正确的,则
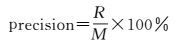 (17)
(17)
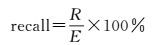 (18)
(18)
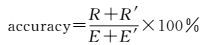 (19)
(19)
为了验证结果的稳定性,在保证测试样本个数相同(正样本:102,负样本:231) 的前提下,对ground truth进行20次随机样本选择,对每一组样本产生的湿地检测正确率统计结果进行平均。
3.1 主题个数K对湿地检测精度的影响对湿地高维特征进行概率潜在语义建模时,潜在主题Z的数目K是需要人工指定的, K值的大小影响着算法性能的优劣[24],因此有必要分析不同的K值对于算法检测结果的影响。分别对比采用“光谱+纹理”特征和采用“光谱+纹理+地物组成成分+环境数据”特征两种情况下,不同潜在主题个数K对应的湿地检测正确率,统计结果如表 4和图 7所示。其中,在图 7中,空心圆点代表 20次随机样本选择下的检测平均正确率,每个空心圆点上两条横线之间的线段则对应着检测结果的两倍标准差。
| K | 光谱+纹理 | 光谱+纹理+组分+环境数据 | |||
| 均值/(%) | 标准差 | 均值/(%) | 标准差 | ||
| 10 | 67.03 | 0.95 | 73.50 | 1.18 | |
| 12 | 71.88 | 1.19 | 80.06 | 1.52 | |
| 14 | 70.07 | 1.41 | 81.92 | 1.54 | |
| 16 | 74.76 | 1.21 | 83.55 | 1.24 | |
| 18 | 77.61 | 0.94 | 85.15 | 1.05 | |
| 20 | 76.40 | 1.10 | 83.13 | 1.29 | |
| 22 | 72.73 | 1.17 | 78.90 | 1.00 | |
| 24 | 68.80 | 1.27 | 70.35 | 1.26 | |

|
| 图 7 不同K值对应的检测平均正确率及标准差 Fig. 7 Average accuracy and standard deviation in different K |
从表 4和图 7中可以看出,不论潜在语义个数是多少,使用“光谱+纹理+地物组成成分+环境数据”特征组合的检测平均正确率均高于使用“光谱+纹理”特征组合的平均正确率,说明了本文提出的加入组成成分和环境数据特征有利于提高湿地检测精度。
在采用“光谱+纹理+地物组成成分+环境数据”特征组合的情况下,从整体趋势而言,平均正确率先随着潜语义个数K值的增大而变高;当K值为18时,平均正确率达到最高值,说明此时pLSA能够对湿地和非湿地样本进行有效建模,实现较满意的检测效果;而当K值大于18时,湿地检测的平均正确率总体呈现下降趋势。由此可见,潜语义个数K并不是越大越好,当K值不断增大时,特征矩阵难以较好的聚类,导致检测结果差或者不太稳定。在本次湿地检测试验中选定K值为18作为最优潜语义主题个数。
3.2 不同特征组合、不同方法的湿地检测结果评价及对比分析为了进一步对本文所提算法的检测结果进行评价,分别采用“光谱+纹理”特征(特征组合a)、“光谱+纹理+地物组成成分”特征(特征组合b)和“光谱+纹理+地物组成成分+地表温度+土壤含水量”特征(特征组合c)时,使用“SVM”和“pLSA+SVM(本文方法)”两种方法的湿地检测平均查全率和平均查准率,如表 5所示。括号中显示的是对应的方法和特征组合下,对20次随机采样的查全率和查准率分别统计后得到的标准差。
| 特征组合 | 查全率 | 查准率 | |||||||
| SVM/(%) | 标准差 | pLSA+SVM/(%) | 标准差 | SVM/(%) | 标准差 | pLSA+SVM/(%) | 标准差 | ||
| a | 86.18 | 2.37 | 89.34 | 2.02 | 74.24 | 1.69 | 75.56 | 1.48 | |
| b | 85.74 | 1.63 | 86.78 | 1.33 | 76.97 | 1.45 | 79.75 | 1.36 | |
| c | 83.33 | 1.65 | 85.19 | 0.80 | 80.00 | 1.11 | 84.81 | 0.83 | |
| 注:a为“光谱+纹理”特征, b为“光谱+纹理+地物组成成分”特征, c为“光谱+纹理+地物组成成分+地表温度+土壤含水量”特征,为20次查全率和查准率统计后得到的标准差。 | |||||||||
从表 5的纵向可以看出,当特征较少时,虽然查全率高但结果不稳定,查准率也较低。加入了地物组成成分特征和定量特征来描述湿地场景后,查准率显著提高且标准差较小,说明检测结果趋于稳定。从横向来看,pLSA+SVM(本文方法)方法通过对低层特征提取了潜在语义后,比直接使用低层特征进行检测的SVM方法得到的查全率和查准率均有提高,且标准差显著下降了,证明了本文方法的优势。
从表 5可以看出,只使用光谱和纹理两种特征时,难以得到较好的湿地识别结果,湿地与其他灌木等地物出现了“异物同谱”的现象,为了改善这种现象,加入地表温度、土壤含水量、场景组成成分等环境特征。因为湿地主要由水、水生植物、湿土组成,且对周围环境有降温作用,土壤含水量也明显高于非湿地,因此加入这些特征能够提高湿地识别精度。
图 8(a)中地物类别为低矮植被和裸土,图 8(b)中地物类别主要为裸土,图 8(c)中地物为低矮植被和不渗水面,这3个区域中地物的光谱、纹理特征和湿地近似,容易被错分为湿地,加入了地物组成成分特征后,这3个区域均被正确识别为非湿地,说明了地物组成成分特征对于解决“同特征异类别”问题的有效性。

|
| 图 8 加入地物组成成分特征检测结果 Fig. 8 Detection results by adding object composition features |
图 9(a)主要由裸土和低植被覆盖组成,地表温度相对较高。图 9(b)中主要由高速公路和绿化植被组成,温度较高,且含水量较少。通过环境参数特征的加入,这两个窗口区域可以被正确识别为非湿地。图 9(c)为村庄周边的一个大的水塘,温度较低,且含水量较高,在环境参数特征的参与下,该区域被识别为湿地。可见,加入地表温度、土壤含水量等环境参数特征能够弥补光谱、纹理特征的不足。

|
| 图 9 加入环境参数特征检测结果 Fig. 9 Detection results by adding environment features |
在图 10(a)中,场景内包含水体、低矮植被、裸土,pLSA将其描述为湿地潜语义,正确识别为湿地场景。图 10(b)为城市中的河流及其表面附着生长的水生植被,pLSA通过建模,识别出场景中有组成湿地的潜语义要素,正确判别为湿地场景。图 10(c)中,为房屋和植被组合,pLSA将其描述为居民地场景潜语义,正确判别为非湿地。可见pLSA模型通过提取潜在语义,建立低层特征与高层语义特征之间的联系,将复杂的场景用语义组合描述,从而实现了相比传统SVM方法更优的检测效果。

|
| 图 10 pLSA+SVM方法检测结果 Fig. 10 Detection results in pLSA+SVM method |
4 总结
本文提出一种基于概率潜在语义分析的多源遥感影像湿地检测方法。首先提取高分辨率影像的光谱、纹理和湿地场景的地物组成成分,并结合由多光谱遥感数据提取的湿地地表温度、土壤含水量,组成湿地场景的特征空间;利用概率潜在语义分析将湿地场景表示成多个潜在语义的组合,用潜在语义的权值向量来描述湿地场景的特征空间,利用SVM分类器实现湿地场景的检测。试验表明,地物组成成分和定量环境特征的加入能有效表征湿地特征空间,明显提高湿地检测精度,相比传统的光谱和纹理特征,查准率提升了7.759%。概率潜在语义分析将湿地场景的高维特征空间映射到低维的潜在语义空间,提高了检测的精度和效率。与传统SVM方法相比,加入定量特征后,查全率和查准率分别提升了2.232%和6.013%。
| [1] | 李玉凤, 刘红玉. 湿地分类和湿地景观分类研究进展[J]. 湿地科学, 2014, 12(1): 102–108. LI Yufeng, LIU Hongyu. Advance in Wetland Classification and Wetland Landscape Classification Researches[J]. Wetland Science, 2014, 12(1): 102–108. |
| [2] | 曹宇, 莫利江, 李艳, 等. 湿地景观生态分类研究进展[J]. 应用生态学报, 2009, 20(12): 3084–3092. CAO Yu, MO Lijiang, LI Yan, et al. Wetland Landscape Ecological Classification:Research Progress[J]. China Journal of Applied Ecology, 2009, 20(12): 3084–3092. |
| [3] | 李建平, 张柏, 张泠, 等. 湿地遥感检测研究现状与展望[J]. 地理科学进展, 2007, 26(1): 33–43. LI Jianping, ZHANG Bai, ZHANG Ling, et al. Current Status and Prospect of Researches on Wetland Monitoring Based on Remote Sensing[J]. Progress in Geography, 2007, 26(1): 33–43. DOI:10.11820/dlkxjz.2007.01.004 |
| [4] | FROHN R C, D'AMICO E, LANE C, et al. Multi-temporal Sub-pixel LandSat ETM+Classification of Isolated Wetlands in Cuyahoga County, Ohio, USA[J]. Wetlands, 2012, 32(2): 289–299. DOI:10.1007/s13157-011-0254-8 |
| [5] | 江冲亚, 李满春, 刘永学. 海岸带水体遥感信息全自动提取方法[J]. 测绘学报, 2011, 40(3): 332–337. JIANG Chongya, LI Manchun, LIU Yongxue. Full-automatic Method for Coastal Water Information Extraction from Remote Sensing Image[J]. Acta Geodaetica et Cartographica Sinica, 2011, 40(3): 332–337. |
| [6] | SOSNOWSKI A, GHONEIM E, BURKE J J, et al. Remote Regions, Remote Data:A Spatial Investigation of Precipitation, Dynamic Land Covers, and Conflict in the Sudd Wetland of South Sudan[J]. Applied Geography, 2016, 69: 51–64. DOI:10.1016/j.apgeog.2016.02.007 |
| [7] | HAN Xingxing, CHEN Xiaoling, FENG Lian. Four Decades of Winter Wetland Changes in Poyang Lake Based on LandSat Observations between 1973 and 2013[J]. Remote Sensing of Environment, 2015, 156: 426–437. DOI:10.1016/j.rse.2014.10.003 |
| [8] | OZESMI S L, BAUER M E. Satellite Remote Sensing of Wetlands[J]. Wetlands Ecology and Management, 2002, 10(5): 381–402. DOI:10.1023/A:1020908432489 |
| [9] | HOUHOULIS P F, MICHENER W K. Detecting Wetland Change:A Rule-based Approach Using NWI and SPOT-XS Data[J]. Photogrammetric Engineering and Remote Sensing, 2000, 66(2): 205–211. |
| [10] | JOLLINEAU M Y, HOWARTH P J. Mapping an Inland Wetland Complex Using Hyperspectral Imagery[J]. International Journal of Remote Sensing, 2008, 29(12): 3609–3631. DOI:10.1080/01431160701469099 |
| [11] | LI Junhua, CHEN Wenjun. A Rule-based Method for Mapping Canada's Wetlands Using Optical, Radar and DEM Data[J]. International Journal of Remote Sensing, 2005, 26(22): 5051–5069. DOI:10.1080/01431160500166516 |
| [12] | 李慧. 基于多源遥感数据的湿地信息提取及景观格局研究-以闽江河口区湿地为例[D]. 福州: 福建师范大学, 2005. LI Hui. Wetland Information Extraction Based on Multi-source RS Data and Landscape Pattern Analysis:A Case of Minjiang River Estuary[D]. Fuzhou:Fujian Normal University, 2005. http://cdmd.cnki.com.cn/Article/CDMD-10394-2005124513.htm |
| [13] | WRIGHT C, GALLANT A. Improved Wetland Remote Sensing in Yellowstone National Park Using Classification Trees to Combine TM Imagery and Ancillary Environmental Data[J]. Remote Sensing of Environment, 2007, 107(4): 582–605. DOI:10.1016/j.rse.2006.10.019 |
| [14] | KINDSCHER K, FRASER A, JAKUBAUSKAS M E, et al. Identifying Wetland Meadows in Grand Teton National Park Using Remote Sensing and Average Wetland Values[J]. Wetlands Ecology and Management, 1997, 5(4): 265–273. DOI:10.1023/A:1008265324575 |
| [15] | HOFMANN T. Unsupervised Learning by Probabilistic Latent Semantic Analysis[J]. Machine Learning, 2001, 42(1-2): 177–196. |
| [16] | 周晖, 郭军, 朱长仁, 等. 引入PLSA模型的光学遥感图像舰船检测[J]. 遥感学报, 2010, 14(4): 663–680. ZHOU Hui, GUO Jun, ZHU Changren, et al. Ship Detection from Optical Remote Sensing Images Based on PLSA Model[J]. Journal of Remote Sensing, 2010, 14(4): 663–680. |
| [17] | 陶超, 谭毅华, 彭碧发, 等. 一种基于概率潜在语义模型的高分辨率遥感影像分类方法[J]. 测绘学报, 2011, 40(2): 156–162. TAO Chao, TAN Yihua, PENG Bifa, et al. A Probabilistic Latent Semantic Analysis Based Classification for High Resolution Remotely Sensed Imagery[J]. Acta Geodaetica et Cartographica Sinica, 2011, 40(2): 156–162. |
| [18] | WANG Yong, MEI Tao, GONG Shaogang, et al. Combining Global, Regional and Contextual Features for Automatic Image Annotation[J]. Pattern Recognition, 2009, 42(2): 259–266. DOI:10.1016/j.patcog.2008.05.010 |
| [19] | OJALA T, PIETIKINEN M, HARWOOD D. A Comparative Study of Texture Measures with Classification Based on Featured Distributions[J]. Pattern Recognition, 1996, 29(1): 51–59. DOI:10.1016/0031-3203(95)00067-4 |
| [20] | OJALA T, PIETIKAINEN M, MAENPAA T. Multiresolution Gray-scale and Rotation Invariant Texture Classification with Local Binary Patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971–987. DOI:10.1109/TPAMI.2002.1017623 |
| [21] | 胡德勇, 乔琨, 王兴玲, 等. 单窗算法结合LandSat 8热红外数据反演地表温度[J]. 遥感学报, 2015, 19(6): 964–976. HU Deyong, QIAO Kun, WANG Xingling, et al. Land Surface Temperature Retrieval from LandSat 8 Thermal Infrared Data Using Mono-window Algorithm[J]. Journal of Remote Sensing, 2015, 19(6): 964–976. |
| [22] | CONGALTON R G. A Review of Assessing the Accuracy of Classifications of Remotely Sensed Data[J]. Remote Sensing of Environment, 1991, 37(1): 35–46. DOI:10.1016/0034-4257(91)90048-B |
| [23] | FOODY G M. Status of Land Cover Classification Accuracy Assessment[J]. Remote Sensing of Environment, 2002, 80(1): 185–201. DOI:10.1016/S0034-4257(01)00295-4 |
| [24] | QUELHAS P, MONAY F, ODOBEZ J M, et al. A Thousand Words in a Scene[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(9): 1575–1589. DOI:10.1109/TPAMI.2007.1155 |