



2. 中国科学院大学, 北京 100049;
3. 江苏省地理信息资源开发与利用协同创新中心, 江苏 南京 210023
2. University of Chinese Academy of Sciences, Beijing 100049, China;
3. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing 210023, China
在城市道路系统中,某路段的交通状态(如速度、流量)会受到其周围路段交通状态变化的影响。例如,某一路段发生拥堵,可能会导致较多本欲进入该路段的机动车会绕行至周边的路段,从而造成周边路段的交通状态发生变化。道路之间的这种交通依赖关系通常称为道路交通相关性。对城市道路交通相关性进行建模有助于理解城市道路系统内部的交互作用模式,并为交通插值和预测提供基础[1-9]。
现有研究及应用通常假定一定空间或拓扑距离内的道路具有交通相关性[3-14]。例如,文献[4]认为一定欧氏距离内的道路具有交通相关性;文献[8]将一定时间可达的道路视为交通相关道路;文献[7]假定一定拓扑距离内的道路具有交通相关性,并将其用于交通预测;文献[9]在交通数据插值时使用拓扑距离来定义道路空间邻近关系。
然而,这种基于距离的方法忽视了道路交通相关性的时空异质性。一方面,众多研究表明路网中的交通流分布具有明显的空间异质性,少部分道路承担了大部分交通流[15]。同时,交通流在道路之间的传播扩散也具有各向异性,上游路段的交通流通常不会均匀地扩散到所有下游路段,而是集中在特定方向上[16],使得道路之间的交通相关性具有空间异质性。另一方面,道路系统中的路况随时间变化剧烈,不难推测道路之间交通交互强度也具有显著的时间异质性。因此,在度量道路交通相关性时考虑其时空异质性是十分必要的。文献[16-17]试图从城市路网拓扑结构的角度出发识别道路交通相关集。尽管这些研究考虑了道路交通影响的空间异质性,但道路交通相关集的划分依据主要来源于理论分析,缺乏定量化的依据。
机动车如同城市道路系统中的微观分子,其成千上万条出行轨迹使得道路在交通上联系紧密。从大量真实出行轨迹中量化道路之间的交通相关性是一种自下而上、由里及表的思路。同时,自然语言处理领域(natural language processing,NLP)的词向量技术[19-22]可以根据词在大量文本中的上下文关系提取词与词之间的语义相似度,因此,本文应用词向量模型Word2Vec[20]根据路段在大量出行路径中的上下游关系提取路段与路段之间的交通相关性。具体由于出行路径由路段序列构成,而文本文档由词序列构成,因此把每条出行路径类比为一篇文本文档,每条路段类比为一个词,然后利用Word2Vec模型从大量出行路径中为每条路段训练出一个实数向量(类比为从语料库中为每个词训练出一个词向量)。根据模型原理,两个词之间的向量相似度高表明它们在文本中的共现频率高(即具有语义相关性,如“道路”和“拥堵”),或者表明它们在文本中的上下文比较相似(即具有语义相似性,如“道路”和“路段”)。类似的,两条邻近路段之间的向量相似度高表明它们在路径中的共现频率高,或者它们在出行路径中共享上下游路段的次数较多。本文将在方法部分进行细致说明,这两种情况均体现了它们具有较强的交通相关性。
本文首先从2011年5月北京市浮动车数据(floating car data,FCD)中提取出200万条载客路径,并根据路径出发时间将其划分为工作日早高峰、工作日晚高峰、工作日平峰、周六日及节假日5个数据集;然后利用词向量模型Word2Vec为每条路段训练出一个实数向量,并通过计算向量之间的余弦相似度来度量对应路段之间的交通相关性;最后利用交通状态数据(道路全天通行时速的时间序列)对结果的有效性进行了验证。
1 研究方法本节首先介绍Word2Vec模型的基本原理,然后给出本文交通相关性定量化的方法流程。
1.1 Word2Vec模型原理词向量技术当前是NLP领域的热门技术之一。该技术的发展始于2000年[19],自2013年起因Word2Vec模型[20]的出现而受到极大关注。词向量技术的主要思想是将词表示为一个N维实数向量,两个向量的相似度可以用来度量其对应词的语义相似度(如“道路”和“路段”)或语义相关度(如“道路”和“拥堵”)。除此之外,词向量还广泛应用于信息抽取、文档分类、命名实体识别等NLP任务[22]。
Word2Vec分为CBOW(Continuous Bag-of-Words)模型和Skip-gram模型两种(模型架构见图 1)[20]。两个模型均为神经网络,其区别在于CBOW利用上下文信息来预测目标词,而skip-gram从目标词来预测上下文信息。

本文试验部分将使用Skip-gram模型,下面简单介绍其原理。
给定词序列w1, w2, …, wT,Skip-gram模型的目标是最大化如下平均对数概率
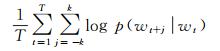 (1)
(1)
式中,k为训练窗口大小(window size),表示目标词前后各k个词被视为目标词的邻近词(即上下文);p(wt+j|wt)为给定目标词wt正确预测邻近词wt+j的概率;T为语料库中所有词的数目。
在Skip-gram模型中,每个词w都有一个输入向量uw和输出向量vw。给定词wj,正确预测词wi的概率定义为
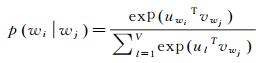 (2)
(2)
式中,V是词典中所有词语的数目。
模型的训练由反向传播随机梯度下降法[22]实现。
1.2 路段交通相关性度量 1.2.1 建立类比关系如前所述,词向量模型可以通过训练语料库中的文本文档将每个词表示为实数向量形式,两个向量相似度高表示它们对应的词在文本中的共现次数多,或者它们的上下文较为相似。每个文本文档都由词序列构成,而每条出行路径都由路段序列构成。通过将每条路段类比为词,每条出行路径类比为文本文档,可以利用词向量模型从大量出行路径中为每条路段训练出一个实数向量。对应地,两条邻近路段的向量相似度高表示这两条路段在出行路径中的共现频率高,或者它们在出行路径中总是共享上下游路段。通过图 2示意图来说明两种情况均表明这两条路段具有较强的交通相关性。

|
| 图 2 道路交通交互关系示意图 Fig. 2 Sketch map of traffic interactive relationships among roads |
图 2中空心圆之间的实线段代表路段,箭头表示路段交通流的方向。灰度相同的路段代表它们具有共同的上游路段或下游路段,而路段的宽度表示它们从共同上游路段分担的交通量的相对大小或者流向共同下游路段的交通量的相对大小。例如,在图 2中,路段0是路段1、2和3的共同下游,但路段0所承担的流量主要源于路段1,少部分源于路段2和3;路段0同时是路段4、5和6的共同上游,但路段0中的流量主要流向路段5和6,少部分流入路段4。
两条路段在出行路径中的共现频率高,则它们具有较强的交通相关性。在图 2中,路段0的交通流分别主要源自于1,路段0和1在出行路径中具有较高的共现频率。这两条路段之间的影响和交互作用明显强于其他邻近路段。路段0的交通流量大小取决于路段1;而如果路段0由于交通事故造成拥堵,路段1会比路段2和3更容易受到影响。
两条路段在出行路径中频繁共享上/下游路段,则两条路段具有较强的交通相关性。图 2中,由于路段5和6具有共同的上游,即路段0。假如路段5由于交通事故发生了拥堵,更多来自路段0的车辆可能会选择路段6作为替代路径,进而使路段6的交通状态其受到影响。
1.2.2 训练路段向量为了度量两条路段之间的交通相关性,首先使用Word2Vec模型获取每条路段的向量表达。该模型的原理在2.1.2节介绍过,在试验中,使用Python第三方库“gensim”中的工具来训练Word2Vec模型,其函数表达及主要参数为
model= gensim.models.Word2Vec(documents, dimension=200, window=5)
Documents是文本文档集合,每一个文本文档都表达为词的序列。Dimension指向量空间的维度,一般取几十到几百。Window即窗口是最重要的参数,决定了在模型训练中使用每个词的前后多少个邻近词作为上下文。例如,窗口等于5意味着每个词在当前文档中前面5个和后面5个邻近词会在训练中当作中间词的上下文。
1.2.3 计算路段之间的向量相似度一个词的向量表示该词在所构建的n维向量空间中的位置,经训练,“相似/相关”的词在向量空间中距离更近。通过将词表达为向量形式,可以通过计算向量之间的相似性来定量化两个词之间的语义相似度或语义相关度。
类似地,通过计算向量之间的相似度来度量任意两条路段之间的交通相关性,相似度越高表明相关性越强。
给定两个向量x和y,其余弦相似度cos θ的计算公式为
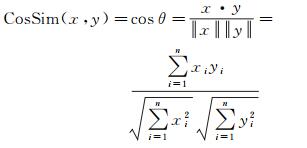 (3)
(3)
式中,xi和yi分别为向量x和y的第i项。相似度范围从-1到1。值越大,相似度越大。
2 试验分析 2.1 数据 2.1.1 道路网络本文使用北京市五环及五环周边的道路中心线数据作为试验数据(图 3)。该路网中共有26 621条路段,道路等级分为高速路、环路、主干道、次干道和支路,在图 3中分别以深红色、橘红色、蓝色、深灰色和浅灰色表示。

|
| 图 3 北京城区道路网络 Fig. 3 Road network of downtown Beijing |
由于该路网由道路中心线表示,而实际道路中的交通流通常具有两个相反的方向,其道路交通状态可能完全不同,需要区分对待。因此,为每一条真实路段增加一条虚拟路段,并将其方向设置为相反,使得整个路网变成有向网络。
2.1.2 浮动车数据本文使用的浮动车数据采集自北京市2万辆配备GPS设备的出租车,采集时间为2011年和2012年5月1日至31日,采样间隔约为60 s。每一条GPS记录都包含了车辆ID、瞬时经纬度坐标、瞬时速度及载客/空车情况。
将2011年5月的数据用于生成出行路径,以训练Word2Vec模型;2012年5月的数据用于计算道路交通状态,以对结果进行验证。
2.1.2.1 出行路径使用地图匹配算法[25]将所有载客GPS轨迹与路网进行匹配,以得到由路段ID序列构成的出行路径。路径i表示为
routei= [road segmentIDi, 1, road segmentIDi, 2, …, road segmentIDi, N]
式中,N为路径i所包含的路段数目。为顾及道路交通相关性的时间异质性,将路径按照其出发时间划分为5个数据集:工作日早高峰(7:00-9:00)、工作日晚高峰(17:00-19:00)、工作日平峰(0:00-7:00、9:00-17:00、19:00-24:00)、周六日及节假日。其中,节假日为五一国际劳动节,放假时间为2011年5月1-2日。
2.1.2.2 路段交通状态本节从浮动车数据中计算道路交通状态数据,该数据将被用于验证本文方法的有效性。
首先,计算路段i在日期d的第t个时段(本文取每15 min为一个时段,全天共96个时段)的车辆平均行驶速度
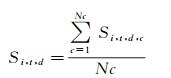 (4)
(4)
式中,Nc为路段i在日期d的时段t的车辆数目;Si, t, d, c为该时段车辆c的即时速度(km/h)。
然后将不同日期路段在工作日早高峰、工作日晚高峰、工作日平峰、周六日及节假日各时段的车辆平均行驶速度按照时间顺序分别合并为一个长时间序列。如此,每条路段都分别在工作日早高峰、工作日晚高峰、工作日平峰、周六日和节假日对应一条交通状态时间序列。
2.2 结果展示及分析Word2Vec模型最重要的参数是窗口大小。本文中利用工作日早高峰、工作日晚高峰、工作日平峰、周六日和节假日5个路径数据集,在窗口分别取1、2、3、4、5、6、7和8情况下,共训练了40个模型。
为对结果进行展示,首先选取了名为“志新路”的某路段(图 4中标注黑色星形的路段),展示了不同时段其与其邻近路段的向量相似性(向量在窗口取值为5的情况下训练得到)。通过这个案例可以看出:

|
| 图 4 志新路与其邻近路段的交通相关性 Fig. 4 Traffic correlation degree between "Zhixin Rd." and its neighbors |
(1) 志新路与其邻近路段的交通相关性随时间变化显著。工作日早高峰、工作日晚高峰及节假日的交通相关性明显强于工作日平峰及周六日,体现了本文的方法可以捕捉到道路交通相关性的时间异质性。
(2) 志新路与其邻近路段的交通相关性具有明显的空间异质性。以工作日早高峰为例,路段9、10和13都是志新路的下游,但是志新路与路段13的交通相关性强于与路段10。这可能是由于标识黑色星形的志新路与路段13同属车流量较大的主干道,而路段9和10为等级较低的次干道。此外,尽管有些路段对并不是直接上下游关系,如志新路与路段4、6、8或11,但是由于它们具有共同的上游或下游,它们依然在交通上具有交互作用。
然后,分别统计了所有1、2、3及4阶邻近路段之间的向量相似度平均值。“n阶”指两条路段在路网中的最短拓扑距离为n。从图 5可以看到:

|
| 图 5 n-阶邻近路段对的向量平均余弦相似度 Fig. 5 Average cosine similarities between n-order neighboring road segments' vectors |
(1) 当窗口为1时,路段交通相关性很低且明显区别于其他窗口值对应的结果。这可能由于窗口太小,训练过程中路段的上下文信息不足。窗口值从2到8的结果先略微上升,然后基本保持平稳。
(2) 工作日早高峰、工作日晚高峰和节假日的结果十分接近,且均高于周六日,进一步高于工作日平峰。该统计结果与前面针对志新路的展示结果较为一致。工作日早晚高峰及节假日道路系统中的交通量比较大,此时道路交通相关性也较大;反之,工作日平峰及周六日交通量较小,相应地,道路交通相关性也较小。该结果的合理性体现了该方法可以正确探测道路交通相关性的时间异质性。
(3) 除了窗口取1时的模型训练结果,1阶邻近路段之间的交通相关性大于2阶邻近路段,2阶邻近路段大于3阶邻近路段,而3阶邻近路段大于4阶邻近路段。这说明在平均水平上,距离越近的路段其交通相关性越强,不但符合地理学第一定律,也说明该方法捕捉到了距离因素对道路交通交互强度的影响。
2.3 结果验证使用2.1.2节介绍的交通状态数据来验证本文结果。需要强调的是,笔者并没有将本文方法直接与基于空间或拓扑距离的方法进行对比,其原因是通过前面的分析可知,本文方法不但可以捕捉到距离因素(即在平均水平上,拓扑距离越近的路段其交通相关性越强),还捕捉到了道路交通相关性的时空异质性。而基于空间或拓扑距离的方法将一定距离内的路段视为交通相关路段,完全忽视了其时空异质性。
本文方法所度量的时间异质性的合理性已在前文分析过,本节主要验证本文方法所度量的空间异质性的正确性。验证的基本思想是如果两条路段的向量相似性更高(即交通相关性更强),则它们的交通状态时序变化也应当更相似。
由于窗口取2到8时模型训练出的结果基本持平,因此无需验证所有窗口下的模型训练结果,而是以窗口等于5为例。
道路之间的交通影响通常具有时间延迟效应,其交通状态的变化并非完全同步。因此,使用动态时间规整(dynamic time warping,DTW)算法[26]代替皮尔森相关系数来度量两条路段之间交通状态时间序列的相似性,并使用下面步骤来检验本文方法所得出的具有较高向量相似度的道路对(即交通相关性更强的道路对)是否也具有更一致的交通状态变化趋势。
(1) 对于每条路段,对其所有的1阶邻近路段按照与其交通相关性的大小进行排序(降序)。一般来说,每条路段有3条1阶上游路段和3条1阶下游路段,共6条1阶邻近路段。
(2) 求算所有路段与其第n交通相关路段之间交通状态DTW距离平均值(n=1, 2, 3, 4, 5, 6)。
结果如图 6所示,横轴代表排序n,纵轴代表所有路段与其第n交通相关路段的交通状态DTW距离的平均值。可以看出,在平均水平上,交通相关性越强的路段对,其道路交通状态也越相似(即DTW距离越小)。这说明本文方法能够正确度量道路交通相关性,正确刻画了其空间异质性。

|
| 图 6 所有路段与其第n交通相关路段的交通状态DTW距离平均值 Fig. 6 Average DTW distances of all the road segments with their nth most similar 1-order neighbors |
3 讨论
除了提出顾及时空异质性的城市道路交通相关性定量化方法,本文贡献还体现在以下两个方面。
第一,机动车如同路网中不停移动的微观分子,其无数条出行轨迹不但构成了整个路网中的交通分布模式,也是道路之间产生影响和交互作用的根本原因。因此,与对“表象”数据(如交通流量、交通状态等)直接进行统计分析不同,将大数据与数据驱动方法结合,从大量出行路径中度量道路之间的交通相关性,为交通研究提供了一种由里及表、自下而上的思路。
第二,本文首次将自然语言处理领域的词向量技术应用于交通领域。由于“路段-路径”与“词-文本”之间较好的对应关系,本文提议未来更多文本处理领域的技术如Topic Model及TF-IDF等均可应用于出行路径选择行为分析及交通相关研究。
但本文也存在一些不足。例如,尽管路径由路段序列构成,文本文档由词序列构成,“路段-路径”和“词-文本文档”之间具有很好地对应关系,但二者之间依然具有细微差别。由于路段和路段之间具有固定的连接方式,每条路段通常只有3条直接邻接上游路段和3条直接邻接下游路段,而每个词在文本中可能出现的上下文词则更多样。本文中并未探讨这种差别是否会对模型训练结果造成影响。
4 结论对道路系统中的交通相关性进行量化不仅有助于理解道路系统内部的交互作用模式,还可以服务于出行信息服务及交通插值、预测等应用。本文使用词向量模型来为每条路段训练实数向量,并通过向量之间的相似度来度量道路之间的交通相关性。通过试验,主要得到以下结论:
(1) 向量相似性越高的邻近路段,其交通状态变化趋势也越相似,证明了本文方法可以正确度量道路之间的交通相关性并刻画出其空间异质性。
(2) 工作日早晚高峰及节假日路段之间的交通相关性大于工作日平峰和周末,该结果的合理性体现了本文方法可以正确捕捉道路交通相关性的时间异质性。
本文所提出的道路交通相关性定量化方法及对结果的分析可为交通规划、诱导及其他相关应用提供方法论和理论基础。
| [1] |
陆锋, 郑年波, 段滢滢, 等.
出行信息服务关键技术研究进展与问题探讨[J]. 中国图象图形学报, 2009, 14(7): 1219–1229.
LU Feng, ZHENG Nianbo, DUAN Yingying, et al. Travel Information Services:State of the Art and Discussion on Crucial Technologies[J]. Journal of Image and Graphics, 2009, 14(7): 1219–1229. DOI:10.11834/jig.20090701 |
| [2] |
欧阳俊, 陆锋, 刘兴权, 等.
基于多核混合支持向量机的城市短时交通预测[J]. 中国图象图形学报, 2010, 15(11): 1688–1695.
OUYANG Jun, LU Feng, LIU Xingquan, et al. Short-term Urban Traffic Forecasting based on Multi-Kernel SVM Model[J]. Journal of Image and Graphics, 2010, 15(11): 1688–1695. |
| [3] | WANG Junjie, WEI Dong, HE Kun, et al. Encapsulating Urban Traffic Rhythms into Road Networks[J]. Scientific Reports, 2014, 4: 4141. |
| [4] | KAMARIANAKIS Y, PRASTACOS P. Space-time Modeling of Traffic Flow[J]. Computers & Geosciences, 2005, 31(2): 119–133. |
| [5] | VLAHOGIANNI E I, KARLAFTIS M G, GOLIAS J C. Optimized and Meta-optimized Neural Networks for Short-term Traffic Flow Prediction:A Genetic Approach[J]. Transportation Research Part C:Emerging Technologies, 2005, 13(3): 211–234. DOI:10.1016/j.trc.2005.04.007 |
| [6] | MIN Xinyu, HU Jianming, ZHANG Zuo.Urban Traffic Network Modeling and Short-term Traffic Flow Forecasting based on GSTARIMA Model[C]//Proceedings of the 13th International IEEE Conference on Intelligent Transportation Systems (ITSC).Funchal, Portugal:IEEE, 2010:1535-1540. |
| [7] | WANG J, CHENG T, HEYDECKER B, et al.STARIMA for Journey Time Prediction in London[C]//Proceedings of the 5th IMA Conference on Mathematics in Transport.London, UK:IMA, 2010. |
| [8] | DING Qingyan, WANG Xifu, ZHANG Xiuyuan, et al. Forecasting Traffic Volume with Space-time ARIMA Model[J]. Advanced Materials Research, 2011, 156-157: 979–983. |
| [9] | ZOU Haixiang, YUE Yang, LI Qingquan, et al. An Improved Distance Metric for the Interpolation of Link-based Traffic Data Using Kriging:A Case Study of A Large-scale Urban Road Network[J]. International Journal of Geographical Information Science, 2012, 26(4): 667–689. DOI:10.1080/13658816.2011.609488 |
| [10] | WHITTAKER J, GARSIDE S, LINDVELD K. Tracking and Predicting A Network Traffic Process[J]. International Journal of Forecasting, 1997, 13(1): 51–61. DOI:10.1016/S0169-2070(96)00700-5 |
| [11] | STATHOPOULOS A, KARLAFTIS M G. A Multivariate State Space Approach for Urban Traffic Flow Modeling and Prediction[J]. Transportation Research Part C:Emerging Technologies, 2003, 11(2): 121–135. DOI:10.1016/S0968-090X(03)00004-4 |
| [12] | MIN Wanli, WYNTER L. Real-time Road Traffic Prediction with Spatio-temporal Correlations[J]. Transportation Research Part C:Emerging Technologies, 2011, 19(4): 606–616. DOI:10.1016/j.trc.2010.10.002 |
| [13] | CHENG Tao, HAWORTH J, WANG Jiaqiu. Spatio-temporal Autocorrelation of Road Network Data[J]. Journal of Geographical Systems, 2012, 14(4): 389–413. DOI:10.1007/s10109-011-0149-5 |
| [14] | ZOU Haixiang, YUE Yang, LI Qingquan, 2014.Explaining the Urban Traffic State from Road Network Structure and Spatial Variance:Empirical Approach Using Floating Car Data[C]//Proceedings of the 93rd Transportation Research Record Annual Meeting.Washington D.C., USA. |
| [15] | JIANG Bin. Street Hierarchies:A Minority of Streets Account for A Majority of Traffic Flow[J]. International Journal of Geographical Information Science, 2009, 23(8): 1033–1048. DOI:10.1080/13658810802004648 |
| [16] | LIU Xiliang, LU Feng, ZHANG Hengcai, et al. Intersection Delay Estimation from Floating Car Data Via Principal Curves:A Case Study on Beijing's Road Network[J]. Frontiers of Earth Science, 2013, 7(2): 206–216. DOI:10.1007/s11707-012-0350-y |
| [17] |
段滢滢, 陆锋.
基于道路结构特征识别的城市交通状态空间自相关分析[J]. 地球信息科学学报, 2012, 14(6): 768–774.
DUAN Yingying, LU Feng. Spatial Autocorrelation of Urban Road Traffic Based on Road Network Characterization[J]. Journal of Geo-Information Science, 2012, 14(6): 768–774. |
| [18] |
刘康, 段滢滢, 陆锋.
基于拓扑与形态特征的城市道路交通状态空间自相关分析[J]. 地球信息科学学报, 2014, 16(3): 390–395.
LIU Kang, DUAN Yingying, LU Feng. Spatial Autocorrelation Analysis of Urban Road Traffic Based on Topological and Geometric Properties[J]. Journal of Geo-Information Science, 2014, 16(3): 390–395. |
| [19] | BENGIO Y, DUCHARME R, VINCENT P, et al. A Neural Probabilistic Language Model[J]. Journal of Machine Learning Research, 2003, 3: 1137–1155. |
| [20] | MIKOLOV T, CHEN Kai, CORRADO G, et al.Efficient Estimation of Word Representations in Vector Space[C]//Proceedings of Workshop at International Conference on Learning Representations.2013:1-12. |
| [21] | DEERWESTER S, DUMAIS S T, FURNAS G W, et al. Indexing by Latent Semantic Analysis[J]. Journal of the American Society for Information Science, 1990, 41(6): 391–407. DOI:10.1002/(ISSN)1097-4571 |
| [22] |
仇培元, 陆锋, 张恒才, 等.
蕴含地理事件微博客消息的自动识别方法[J]. 地球信息科学学报, 2016, 18(7): 886–893.
QIU Peiyuan, LU Feng, ZHANG Hengcai, et al. Automatic Identification Method of Micro-blog Messages Containing Geographical Events[J]. Journal of Geo-Information Science, 2016, 18(7): 886–893. |
| [23] | PENNINGTON J, SOCHER R, MANNING C D.Glove:Global Vectors for Word Representation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP).Doha, Qatar:Association for Computational Linguistics, 2014, 14:1532-1543. |
| [24] | RUMELHART D E, HINTON G E, WILLIAMS R J. Learning Representations by Back-propagating Errors[J]. Nature, 1986, 323(6088): 533–536. DOI:10.1038/323533a0 |
| [25] | LIU Xiliang, LIU Kang, LI Mingxiao, et al. A ST-CRF Map-Matching Method for Low-frequency Floating Car Data[J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(5): 1241–1254. DOI:10.1109/TITS.2016.2604484 |
| [26] | SAKOE H, CHIBA S. Dynamic Programming Algorithm Optimization for Spoken Word Recognition[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing, 1978, 26(1): 43–49. DOI:10.1109/TASSP.1978.1163055 |