


2. 北京航空工程技术研究中心, 北京 100076
2. Beijing Aeronautical Technology Research Center, Beijing 100076, China
遥感影像的分类效果很大程度取决于提取的影像特征,文献[1]将现有的遥感影像特征提取方法分为3大类:①人工特征,如影像的光谱、纹理、空间、GIST、SIFT、HOG等;②基于无监督的特征,如主成分分析、K-均值聚类、稀疏编码等;③深度特征,如SAE、CNNs等。由于深度特征可以代表影像更为抽象的特征,因此近两年大量研究采用深度神经网络来提取遥感影像的特征[2-8]。然而,深度网络能够提取出有效特征的前提是有足够的训练样本[9]。对于一幅陌生的遥感影像,首要的是选取大量的样本并且对其进行标记,这在实际过程中非常耗时[10-11]。因此在训练样本有限甚至没有的情况下如何训练出泛化能力较强的网络是目前深度学习领域正在解决的热点问题。
假设已有一个相对较大的已经标注过的遥感影像数据集,若利用其更加丰富的数据作为训练样本,理论上可以训练出更为成熟、泛化能力更强的网络,用这个网络将会对新的遥感影像提取出更好的特征。然而,不同数据集之间由于传感器、拍摄角度、季节等的差异,造成同一类型的地物在不同的域中差异巨大。直接将大规模数据集样本训练的网络来预测目标数据集,得到的分类结果并不理想。由此,不同数据集之间的域适应问题得以提出,在域适应问题中,提供训练样本的数据集所在的域称为源域,对需要进行分类的数据集称为目标域。
近些年,诸多学者对域适应问题进行了研究,研究的图像对象主要集中在Office/Caltech数据集,和Mnist/Mnist_M/USPS/SVHN数据集,前者包含4个域,内容为数码照片,后者是0-9数字图像。研究的问题可按照目标域中是否有可用标签分为两类[12]:一种是监督/半监督学习,即目标域中所有类或者部分类中部分图像含有标签,可以直接作为训练样本;另一种是完全无监督学习,即目标域中没有可用标签。研究的方法通常有两种类型:一是用人工特征、或者训练好的CNN网络对遥感影像进行特征提取,然后求出一个转换矩阵,将源域的特征映射到目标域中,使两个域的影像享有同一个特征空间,这类方法的相关研究有ARC-t[13]、MMDT[14]、HFA[15]、GFK[16]、Landmarks[17]等,其中,GFK和Landmarks是无监督的,其他方法为监督学习的方法。
域适应的另外一种类型是基于深度学习的方法。文献[18]在标签代价函数的基础上,引入了称为域混淆损失的代价函数,具体做法是在最后一层全连接层之前加了域适应层,源域和目标域的样本经过该层的输出特征后,计算其最大平均偏差距离(maximum mean discrepancy,MMD),该距离与标签损失之和为新的目标函数。针对监督和半监督分类,文献[19]在文献[18]的基础上加入了软标签损失,用来保持源域和目标域各类之间相对分布的一致性。文献[20]使用了对抗网络框架[21]来解决域适应问题,其目标函数包括标签分类器和域分类器两部分,该方法的对抗思想体现在:对于域适应问题,一是希望网络学到的特征表示具有域不变的特征,这就导致域分类器不能正确进行域分类,即域分类器的分类损失最大;二是在对域分类器训练同时,要求标签分类器能尽可能地正确分类,即标签分类器的分类损失最小。
目前域适应方法普遍的试验对象为普通图像,近年来也有学者针对遥感影像的域适应方法进行针对性的研究[22-23]。遥感影像相对于普通图像在域适应问题上有很大不同:一方面其源域和目标域差异较大;另一方面图像包含的地物信息丰富,需要更深的网络,而更深的网络需要更为丰富的样本数据支持。传统域适应方法直接用于遥感影像很难取得较好的分类效果。
针对遥感影像域适应过程中的高分辨率遥感影像尺寸大而数据量小的问题,本文提出了基于对抗网络和辅助任务的遥感影像域适应方法,其创新点在于:①首次进行遥感影像无监督域适应场景分类的研究,构建了遥感影像域适应试验的数据集,设计了结合辅助任务的对抗网络架构;②引入域损失函数,在目标函数中增加了域分类任务,使分类器学习到域不变特征;③引入不同标签空间的辅助分类任务,丰富了训练样本,提高网络的泛化能力和特征提取能力。试验表明,本文方法加入了域损失任务与辅助分类任务,与主流域适应算法相比,在分类效果上有明显的优势。
1 本文提出的方法问题描述:设源域数据集合为S={(xsi, ysi)}i=1ns,其中xsi为源域中图像数据,ysi为相应的标签,ysi∈Ys={0,1,2,…l, l+1, …L}, ns为源域中样本数量;目标域数据集合为T={(xti)}i=1nt,xti为目标域中图像数据,nt为目标域中样本数量,目标域中每个样本的标签yti是未知的,但是其所在空间是已知的,yti∈Yt={0,1,2,…l},即YT⊂YS。S和T服从不同的分布, 记S~Ds,T~Dt,且Ds≠Dt。将源域中与目标域享有共同标签空间的样本称为主样本Smain={(xmaini, ymaini)}i=1nmain,源域中不属于目标域空间的样本称为辅助样本Saux={(xauxi, yauxi)}i=1naux,且满足
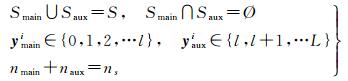 (1)
(1)
式中,xmaini和xauxi分别为主样本和辅助样本中图像数据;ymaini和yauxi为相应的标签;nmain和naux为样本数量。
算法的目的是,利用源域数据S,求解一个分类器Cθ,使得
 (2)
(2)
本文方法的框架如图 1所示,源域和目标域的数据共同输入到多层卷积神经网络提取特征,然后将辅助样本的特征作为辅助标签预测器(上侧区域)的输入;将主样本的特征输入到主标签预测器(中间区域)和域预测器中(下侧区域);将目标域的特征输入到域预测器中。所有分类器输出后与相应的标签计算损失。本文方法的损失函数为

|
| 图 1 本文方法的框架 Fig. 1 Framework of the proposed method |
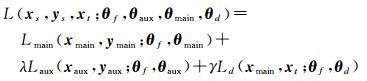 (3)
(3)
损失函数由3部分构成:主损失函数Lmain、辅助类损失函数Laux和域损失函数Ld,λ与γ为相应的权重系数。
1.1 对抗网络本文设计的网络基于两个目的:一是网络可以对地物类型进行分类,二是网络具有域不变特性,即网络区分不出来输入影像来自于哪一个域。前者可以理解调整网络参数,使类损失函数最小;后者可以通过一个域损失函数来实现。对于两个不同域的影像,除了其自带的类标签,人为定义一个域标签,比如对于源域其标签为0,对于目标域其标签为1。域损失越大,域分类器就越难区别输入影像来自源域或目标域,网络的域适应性也就越好。因此,网络参数需要同时满足分类损失最小化和域损失最大化,这两个部分是对抗的。
主损失函数为类别损失,其定义如下
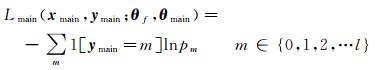 (4)
(4)
式中,xmain、ymain分别为共享样本数据和标签;θf为特征提取单元的网络参数;θmain为主分类器的网络参数,该分类器由若干个全连接层组成,分类器最后输出的单元数为主类的类别数;1为指示函数,当ymain=m成立时值取1,否则取0;pm为softmax层的输出值,pm=softmax[θmainTf(xmain; θf)]。
按照所在域的不同,分别为源域中的主样本和目标域中的样本增加一个域标签,记为ydmain与ydt,并定义:{ydmain}nmain=0,{ydt}nt=1。域损失定义如下
 (5)
(5)
式中,θd为域分类器的网络参数,该分类器输出的单元数为域标签的类别数,即为2;1为指示函数,当yd=d成立时值取1,否则取0;pd为域分类器softmax层的输出值,pd=softmax[θdTf(xmain, xt; θf)]。
由于对抗网络的目标是学习到域不变特征,也就是说域分类器分辨不出类别最好。因此域的损失函数不能与类别损失函数一样越小越好,而是在源域类别损失相对较小的情况下,域损失函数越大越好。因此求解目标是
 (6)
(6)
注意到式(6)中,Ld的求解目标是使其最大化,这种情况不能用梯度下降进行求解。为了解决这个问题,定义一个中间函数R(x),在前向与反向传播中
 (7)
(7)
式(7)表示正向传播时无影响,而反向用梯度更新参数时进行梯度反转,由此就得到可以满足使用梯度下降法的表现形式。
1.2 辅助任务在本文遥感影像域适应应用场景中,源域样本中还包括了目标域中不存在类别的样本。为了充分利用源域的样本,本文加入了辅助任务,其思想来源于多任务学习。多任务学习在单一任务的基础上,结合了辅助的任务学习共同的特征表示[24-25]。通过辅助任务学习,最大限度地丰富了训练样本,学习到的特征相对于单任务学习具有更好的泛化能力,并且有效地减小类内距离与增大类间距离,有利于提高分类精度。
本文的辅助损失函数的定义如下
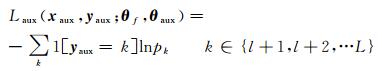 (8)
(8)
式中,xaux、yaux分别为辅助样本数据和标签;θaux为辅助类线性分类器的网络参数,分类器最后输出的单元数为辅助类的类别数;1为指示函数,当yaux=k成立时值取1,否则取0;pk为softmax层的输出值,pk=softmax[θauxTf(xaux; θf)]。辅助损失函数为类别损失,要求其损失越小越好,即求解目标为
本文方法的参数更新流程如下
输入:源域数据S={(xsi, ysi)}i=1ns,目标域数据T={(xti)}i=1nt,初始化参数θf、θaux、θmain、θd,权重系数λ与γ,迭代次数i=0,初始学习率ϕ(0),最大迭代次数num_step,单次输入样本数量batchsize
While i<num_step:
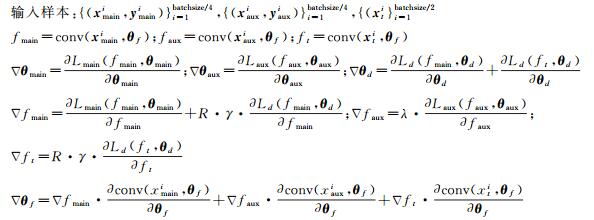
更新参数:
θmain=θmain-ϕ(i)·Δθmain,θaux=θaux-ϕ(i)·Δθaux,θd=θd-ϕ(i)·Δθd,θf=θf-ϕ(i)·Δθf
i+=1
End while
输出:θf,θmain,并预测标签
本方法有3个需要人工设置的参数,λ、γ及学习率ϕ。其中,λ是固定的,γ和ϕ按照式(9)和式(10)更新
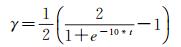 (9)
(9)
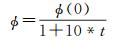 (10)
(10)
式中,ϕ(0)为初始学习率;t=i/num_step,i为当前迭代次数,num_step为最大迭代次数。
2 试验 2.1 构建数据集目前还没有公开的适用于遥感影像域适应试验的数据集,故本文使用了3个数据作为数据源构建域适应数据集,分别是:①NWPU-RESISC45数据集[1](简称NWPU),该数据集含有45类场景的遥感影像,每类影像都包含有700张图片,共31500张影像;②一整幅遥感影像为Quickbird卫星拍摄的西安市遥感影像(简称Xian),尺寸为13312×7680像素。对Xian进行了切割,并人工分类标注,选出与NWPU重叠的8个类,共339张影像;③一整幅遥感影像为高分二号卫星拍摄的广州市遥感影像(简称GZ),与处理Xian类似,对其进行切割与人工标注,选出与NWPU重叠的8个类,共826幅影像。因此以上3个数据集共构成了两组遥感影像域适应数据集,将其分别命名为NWPU-Xian8及NWPU-GZ8。示例图像如图 2所示,每张示例图像底部数字为该类样本数。从图 2可以看出,NWPU-Xian8的图像差异较大,Xian的影像颜色存在失真,并且噪声较为严重,而NWPU-GZ8影像差异较小。两组数据集中NWPU的其余37类影像在这里不再展示,请参考文献[1]。以上所有影像的尺寸为256×256。

|
| 图 2 数据集各类示例 Fig. 2 Samples from each category in the domain adaptation datasets |
2.2 试验设置
针对两组数据集进行的试验中,分别将NWPU整个45类作为源域,Xian及GZ作为目标域。因此在NWPU-Xian8及NWPU-GZ8中,主任务的数据类别都为8类,辅助类别为37类。训练及测试时对输入到网络中的影像随机裁剪为227×227,网络的各个参数,比如卷积核大小,步长和卷积层的层数如图 3所示,前8个方框表示特征提取层,本文特征提取阶段使用了预训练的Alexnet网络结构[24]。紧接着特征提取层,为3个网络分支,这3个分支分别为主分类器,辅助分类器和域分类器。3个分类器都是由全连接层构成,其最终输出结点分别为8、37和2。本文所有试验代码基于tensorflow进行搭建,硬件环境为Amazon EC2的P2.xlarge实例,该实例的GPU型号为nvidia tesla k80。

|
| 图 3 本文方法的网络结构 Fig. 3 The net structure of the proposed approach |
2.3 试验结果与分析
将本文方法与文献中其他方法进行试验对比。对比的方法有:①source only,将源域数据输入到网络进行训练,直接对目标域进行分类,不加入域损失和辅助损失函数;②GFK,文献[5]中的方法;③Landmark,文献[6]所介绍的方法,是文献[5]方法的扩展,GFK和Landmark,其使用的图像特征是由预训练的alexnet网络的fc7层提取得到,每张图像都表示为4096维特征;④source+domain,文献[20]中的方法,即源域样本分类与域分类同时进行,没有增加辅助分类任务;⑤MMD,文献[7]中的方法,使用MMD损失函数进行域间最小化。对于source only及后3种方法,设置初始学习率ϕ(0)=0.002,batchsize=64,最大迭代次数为10000;MMD中,MMD损失是用fc7的输出进行计算得到,系数为0.25;本文方法中,λ=1。各类方法最后对目标域数据进行分类,对于GFK和Landmark,计算20次试验的平均精度作为其最终精度。对于其他方法,设置每训练25次进行一次测试,将最后10次测试的平均精度作为其最终精度,6种方法最终测试精度列于表 1。基于最后一次测试的结果计算各方法预测的混淆矩阵,将各个方法对于NWPU-Xian8数据集的混淆矩阵列于图 4。
| (%) | ||||||
| source only | GFK | Landmark | source+domain | MMD | 本文方法 | |
| NWPU-Xian8 | 58.40 | 60.47 | 69.44 | 76.40 | 63.12 | 79.63 |
| NWPU-GZ8 | 76.99 | 78.32 | 81.07 | 83.50 | 77.05 | 84.63 |

|
| 图 4 NWPU-Xian8数据集混淆矩阵 Fig. 4 Confusion matrix for NWPU-Xian8 dataset |
从表 1可以得到看出,本文方法在精度上优于其他算法,source+domain次之。图 4中,本文方法相对于其余5类方法,表现较为均衡,对于容易混淆的intersection、freeway和overpass这3类的精度也有了一定的提高。由此表明了对抗网络和辅助任务可以较好地学习到域不变特征,提高网络的泛化能力和分类精度。
为了进一步验证本文方法提取域不变特征的优势,用高维数据可视化工具t-SNE对NWPU-Xian8数据集聚类结果进行可视化(t-SNE详情参见文献[27])。聚类的对象为进入到分类器之前目标域所有数据的特征。如图 5所示,图(a)为直接采用预训练的Alexnet网络提取的fc7层特征,图(b)为本文方法倒数第2层输出的特征,两种特征都为4096维。两张图分别表示未进行域适应和进行了域适应后目标域数据各类之间的关系。可以看出进行域适应后,目标域各类之间距离增大,同类之间距离减小,很好地学习到了域不变特征。

|
| 图 5 NWPU-Xian8数据集目标域图像特征的二维可视化 Fig. 5 2-D visualization of image feature in the target domain for NWPU-Xian8 dataset |
3 结论
本文针对遥感影像场景分类中小样本量的无监督学习问题,提出了一种结合对抗网络与辅助任务的遥感影像域适应方法,建立了基于深度卷积神经网络的遥感影像分类框架,在标签损失函数的基础上加入了域分类器,并使得域损失函数与标签损失形成对抗的关系,最后引入了辅助分类任务,扩充训练样本。在本文构建的遥感影像域适应数据集上试验结果表明,本文方法能够通过域损失学习到域不变特征,通过辅助分类任务增加类间距离、减小类内距离,并使网络具有良好的泛化能力,在不同域的无监督分类中有明显的优势。对小样本量的Xian和GZ数据集无监督分类精度达到79.63%和84.63%,相对于直接利用大样本量数据集NWPU对Xian和GZ数据集分类(58.40%和76.99%),本文方法分类效果有显著提高。
| [1] | CHENG Gong, HAN Junwei, LU Xiaoqiang. Remote Sensing Image Scene Classification:Benchmark and State of the Art[J]. Proceedings of the IEEE, 2017, 105(10): 1865–1883. DOI:10.1109/JPROC.2017.2675998 |
| [2] | HU Fan, XIA Guisong, HU Jingwen, et al. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-resolution Remote Sensing Imagery[J]. Remote Sensing, 2015, 7(11): 14680–14707. DOI:10.3390/rs71114680 |
| [3] | ZOU Qin, NI Lihao, ZHANG Tong, et al. Deep Learning Based Feature Selection for Remote Sensing Scene Classification[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(11): 2321–2325. DOI:10.1109/LGRS.2015.2475299 |
| [4] |
许夙晖, 慕晓冬, 赵鹏, 等.
利用多尺度特征与深度网络对遥感影像进行场景分类[J]. 测绘学报, 2016, 45(7): 834–840.
XU Suhui, MU Xiaodong, ZHAO Peng. Scene Classification of Remote Sensing Image Based on Multi-scale Feature and Deep Neural Network[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(7): 834–840. DOI:10.11947/j.AGCS.2016.20150623 |
| [5] | ZHANG Fan, DU Bo, ZHANG Liangpei. Scene Classification via a Gradient Boosting Random Convolutional Network Framework[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(3): 1793–1802. DOI:10.1109/TGRS.2015.2488681 |
| [6] | ROMERO A, GATTA C, CAMPS-VALLS G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(3): 1349–1362. DOI:10.1109/TGRS.2015.2478379 |
| [7] | NOGUEIRA K, PENATTI O A B, DOS SANTOS J A. Towards Better Exploiting Convolutional Neural Networks for Remote Sensing Scene Classification[J]. Pattern Recognition, 2017(61): 539–556. |
| [8] | ZHOU Xichuan, LI Shengli, TANG Fang, et al. Deep Learning with Grouped Features for Spatial Spectral Classification of Hyperspectral Images[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(1): 97–101. DOI:10.1109/LGRS.2016.2630045 |
| [9] | GE Weifeng, YU Yizhou.Borrowing Treasures from the Wealthy:Deep Transfer Learning through Selective Joint Fine-tuning[J].arXiv preprint arXiv:1702.08690, 2017. |
| [10] | LIN Daoyu, FU Kun, WANG Yang, et al. MARTA GANs:Unsupervised Representation Learning for Remote Sensing Image Classification[J]. IEEE Geoscience and Remote Sensing letters, 2017, 14(11): 2092–2096. DOI:10.1109/LGRS.2017.2752750 |
| [11] |
何小飞, 邹峥嵘, 陶超, 等.
联合显著性和多层卷积神经网络的高分影像场景分类[J]. 测绘学报, 2016, 45(9): 1073–1080.
HE Xiaofei, ZOU Zhengrong, TAO Chao, et al. Combined Saliency with Multi-convolutional Neural Network for High Resolution Remote Sensing Scene Classification[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(9): 1073–1080. DOI:10.11947/j.AGCS.2016.20150612 |
| [12] | WEISS K, KHOSHGOFTAAR T M, WANG D D. A Survey of Transfer Learning[J]. Journal of Big Data, 2016, 3(1): 9–48. DOI:10.1186/s40537-016-0043-6 |
| [13] | KULIS B, SAENKO K, DARRELL T.What You Saw is not What You Get:Domain Adaptation Using Asymmetric Kernel Transforms[C]//Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Colorado Springs, CO, USA:IEEE, 2011:1785-1792. |
| [14] | HOFFMAN J, RODNER E, DONAHUE J, et al.Efficient Learning of Domain-invariant Image Representations[C]//Proceedings of the International Conference on Learning Representations (ICLR).Scottsdale, Arizona:ICLR, 2013. |
| [15] | DUAN Lixin, XU Dong, TSANG I W.Learning with Augmented Features for Heterogeneous Domain Adaptation[C]//Proceedings of the 29th International Conference on Machine Learning.Edinburgh, Scotland, UK:ICML, 2012:711-718. |
| [16] | GONG Boqing, SHI Yuan, SHA Fei, et al.Geodesic Flow Kernel for Unsupervised Domain Adaptation[C]//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition.Providence, RI, USA:IEEE, 2012:2066-2073. |
| [17] | GONG Boqing, GRAUMAN K, SHA Fei.Connecting the Dots with Landmarks:Discriminatively Learning Domain-invariant Features for Unsupervised Domain Adaptation[C]//Proceedings of the 30th International Conference on Machine Learning.Atlanta, USA:ICML, 2013:222-230. |
| [18] | TZENG E, HOFFMAN J, ZHANG Ning, et al.Deep Domain Confusion:Maximizing for Domain Invariance[J].arXiv preprint arXiv:1412.3474, 2014. |
| [19] | TZENG E, HOFFMAN J, DARRELL T, et al.Simultaneous Deep Transfer Across Domains and Tasks[C]//Proceedings of 2015 IEEE International Conference on Computer Vision.Santiago, Chile:IEEE, 2015:4068-4076. |
| [20] | GANIN Y, LEMPITSKY V.Unsupervised Domain Adaptation by Backpropagation[C]//Proceedings of the 32nd International Conference on Machine Learning.Lille, France:ICML, 2015:1180-1189. |
| [21] | GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al.Generative Adversarial Nets[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal, Canada:MIT Press, 2014:2672-2680. |
| [22] | TUIA D, PERSELLO C, BRUZZONE L. Domain Adaptation for the Classification of Remote Sensing Data:An Overview of Recent Advances[J]. IEEE Geoscience and Remote Sensing Magazine, 2016, 4(2): 41–57. DOI:10.1109/MGRS.2016.2548504 |
| [23] | LI Xue, ZHANG Liangpei, DU Bo, et al. Iterative Reweighting Heterogeneous Transfer Learning Framework for Supervised Remote Sensing Image Classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(5): 2022–2035. DOI:10.1109/JSTARS.2016.2646138 |
| [24] | ZHANG Zhanpeng, LUO Ping, LOY C C, et al.Facial Landmark Detection by Deep Multi-task Learning[C]//Proceedings of the 13th European Conference on Computer Vision.Zurich, Switzerland:Springer, 2014:94-108. |
| [25] | SELTZER M L, DROPPO J.Multi-task Learning in Deep Neural Networks for Improved Phoneme Recognition[C]//Proceedings of 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).Vancouver, BC, Canada:IEEE, 2013:6965-6969. |
| [26] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E.Imagenet Classification with Deep Convolutional Neural Networks[C]//Advances in Neural Information Processing Systems.Spain:NIPS, 2012:1097-1105. |
| [27] | VAN DER MAATEN L, HINTON G. Visualizing Data Using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(11): 2579–2605. |