



随着科学技术的进步,遥感卫星获取影像的分辨率不断提升,目前已经出现的高分卫星IKONOS、QuickBird使得遥感影像的分辨率达到米级、甚至亚米级别,标志着遥感领域已经进入了高分辨率影像时代。高分辨率遥感影像不仅具有丰富的空间、纹理特征,而且包含了大量场景语义信息。然而,由于场景的构成复杂且地物覆盖类别众多,很难从海量的影像数据中,直接获取感兴趣的场景信息。如何有效地表达和识别高分影像中的场景成为极具挑战的课题,已引起了遥感学术界的广泛关注[1]。
为了理解和识别高分影像中的场景信息,学者们先后提出了很多场景分类方法, 大致可以分为两类:基于低层次特征的方法和基于中层语义特征建模的方法[2]。基于低层次特征方法通常采用颜色、纹理等全局统计信息来表达场景。文献[3]利用贝叶斯网络集成颜色特征、小波纹理特征和先验语义特征对室内、外场景影像进行分类。文献[4]提出了基于全局低层次特征的Gist方法,该方法将整幅场景作为对象,无需对场景中的目标进行分割,计算简单、快速,但只能区分较少类别的场景且精度有限。基于中层语义建模的典型方法就是视觉词袋模型(BoVW)[5],通过对图像低级特征进行量化统计,进而表示视觉单词分布,为图像分类提供基础数据,它建立了场景对象的低层次特征和高层次语义之间的联系,能够较好地表达场景信息,获得比较高的分类精度,但是需要大量的存储空间和计算量,场景对象的分割效果也直接影响分类结果。文献[6]提出了一种基于词袋模型的影像表达方法--空间金字塔匹配核(SPMK),计算简单有效。文献[7]通过计算视觉字典的共现,再结合BoVW方法,提出了一种空间共现核方法(SPCK++),相比传统方法BoVW和SPMK分类精度最高,但是以上两种核方法都采用了非线性莫西核,计算复杂度非常高。此外,应用较多的场景分类方法还有主题模型(LDA)[8-10],它是一种层次概率模型,基于视觉词典的分布来无监督的学习主题分布。基于主题模型还有很多扩展方法,例如将其与支持向量机(SVM)结合的SVM-LDA[11]方法,以上特征建模方法都依赖于K均值聚类来产生视觉字典,因此特征表达对于分类有很大的局限性。
最近,还有学者将深度学习算法应用到影像分类中,例如,文献[12]提出一种无监督特征学习方法,利用稀疏自编码网络提取特征,分类结果较已有算法有所提高,但是稀疏自编码只是一个浅层的网络,提取特征有限。文献[13]利用卷积神经网络[14]对遥感影像进行分类,虽然分类精度很高,但是没有涉及场景。总体而言,当前卷积神经网络在图像方面的应用主要集中在人脸识别、字母识别(车牌号、手写体等)、车辆检测以及自然场景分类,对于高分辨率遥感影像场景分类的研究甚少。因此,本文提出一种联合显著性和多层卷积神经网络的高分影像场景分类方法。通过显著性算法,获取能够表达场景信息的显著目标区域,然后在这些显著区域进行采样,构建初始样本集;利用深度卷积神经网络从样本集中提取高层次特征,最后联合不同层次特征输入支持向量机中分类。
1 原理与方法 1.1 场景分类存在的问题影像场景可以看成多个独立目标的集合,例如商业区由道路、建筑物、停车场等组成,这些独立目标具有不同的结构和纹理信息,通过不同的组合以及空间排列方式,形成不同的场景类别。场景分类对于影像解译和理解具有重大的意义,同一场景类别具有语义一致性,但是由于影像自身的差异和变化(例如光照、物体的形状、大小、位置等)使得同一类别的对象不一致;此外,不同场景类别之间还具有视觉相似性,这就给场景分类带来了困难[15]。具体表现为:
(1) 相同类内差异性:属于同一类别的场景影像,具有不同的表现形式,如图 1中的高尔夫球场,有树木围绕的球场,也有宽阔没有草的球场,还有茂盛草地的球场,这些不同形式的高尔夫球场,在纹理、色调等方面都存在差异。

|
| 图 1 相同类内差异性(类别为高尔夫球场) Fig. 1 Differences within the same class (category: golf course) |
(2) 不同类间相似性:场景类别虽然多种多样,但是组成场景的基本目标却是少量的,因此在不同的场景影像中,依然能够发现相似之处。如图 2的3类不同场景类别交叉路口、建筑物、居民区,都有房子、道路等目标存在,区别只在于哪种目标占据影像的比例大,因此在分类时,这些类别很容易互相混淆,影响最终的分类精度。

|
| 图 2 不同类间相似性(类别依次为:交叉路口、建筑物、居民区) Fig. 2 Similarity between different classes (categories: intersection、building、residential) |
1.2 显著性采样
由于类内差异性和类间相似性的存在,直接利用原始影像进行特征提取,类别之间会相互影响,导致分类效果差。通过采样获取有意义的影像块,来代替原始影像的方法能够有效地提高分类效率和结果。传统的方法是直接分块,即对影像进行规则格网划分,然后随机选取块,此方法的前提是假定影像的不同区域包含相同的信息,对于遥感影像不太适用。文献[16]中利用SIFT采样,首先提取影像的SIFT特征点,将影像划分成格网,随机选取位于格网内的SIFT特征点,再以这些特征点为中心,选取一个矩形块,最后将很多块连接起来构成一个新影像作为初始输入。SIFT采样相比直接分块,能够针对性地选取一些与场景有关联的块,但是SIFT主要是一些边缘和角点,并不能选取可以表达场景信息的区域。
因此,本文采用显著性探测算法[17]来指导采样。显著性探测,就是在大量信息中选择感兴趣区域的过程,这些感兴趣区域通常包含了影像中的绝大部分信息,因此能够很好地表达影像。本文选取一种新的显著性探测方法--PCA Saliency[18]。该方法通过计算图案差异性、颜色差异性以及影像结构的先验知识,得到最终的显著图。一般的显著性方法在定义差异性时,采用最邻近算法,未考虑影像块内部的统计规律,该方法引入了影像块内部统计分析,利用主成分分析(PCA)来表达影像块,进而定义差异性。
(1) 图案差异性。传统度量图案差异性是通过计算每个影像块与其他影像块之间的距离,忽略了像素之间的联系。这里基于两个准则来计算图案差异性:自然影像中的非显著区通常集中在高维空间,而显著区则更加发散[18];计算到平均块距离时,应该考虑影像块的分布。通过计算主成分可以得到分布情况
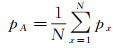 (1)
(1)
 (2)
(2)
式中,px代表影像块;pA代表平均影像块;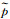
(2) 颜色差异性。在CIE LAB色彩空间,通过计算某个区域与其他区域的L2范数距离之和,来表征颜色差异性
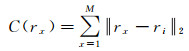 (3)
(3)
(3) 影像结构的先验信息。先验信息包括以下内容:显著像素通常集聚成类,在场景中对应一个实际目标;人眼定位目标通常趋向于影像中心。通过计算高斯权重图G(px)来表示先验知识。
最终的显著图是上面三者的乘积S(px)=G(px)×P(px)×C(px),结果归一化到[0,1]之间,为了获得更加准确的显著图,还采用多个尺度:100%、50%、25%来计算,具体细节可以参考文献[18]。用上述方法计算高分影像的显著图,如图 3所示。

|
| 图 3 6类高分场景影像以及显著性探测结果 Fig. 3 Six categories of high resolution scene image and corresponding saliency detection results |
从图 3的显著性探测结果来看,不同区域对应不同的值,在图像上显示为明暗的差异。对于飞机、港口、储罐,显著区域是较明亮的飞机、船艇和圆形罐体,其他区域接近黑色;农田由于纹理重复出现,都比较显著,所以整体较亮。以上大部分类别的显著区域都是比较亮的,但对于河流和交叉路口来说,显著区域正好相反,都比较暗。总体来说,显著区域与非显著区域的对比差异明显,合理定义阈值可以获取感兴趣的显著区域。从目视来看,显著区域包含的目标对于场景理解最具代表性(例如港口中的船),识别出关键目标也就相应地识别出了场景。
显著区域得到以后,就可以采集样本块。假设有N幅影像,对于每幅影像都可以得到对应的显著图,由于不同类别影像差异,显著区域有可能在明或暗处,因此笔者定义两个阈值α、β来区分显著与非显著区域,在大于α或小于β的区域随机选择M个块,每块大小为m×m,波段数为3(RGB)。因此,每幅影像构建样本集的大小为:m×m×3×M。
1.3 卷积神经网络影像分类的关键在于特征提取,选取特征的好坏决定了最终的分类结果。人工设计的低层次特征,比如Gabor、LBP、SIFT等,在特定的分类和识别任务中取得了非常大的成功。然而,对于新的数据和任务,人工设计有效的特征需要大量新的先验知识,这无疑是困难的[19]。近年来,深度学习引起了广泛的关注,其通过建立类似于人脑的分层模型结构,对输入数据逐级提取从底层到高层的特征,从而能很好地建立从底层信号到高层语义的映射关系[20]。在图像处理方面,应用比较成功的深度学习模型就是卷积神经网络(CNNs),它的起源可以追溯到1980年的神经认知机,它也是第一个真正成功训练多层网络结构的学习算法,该方法将局部感受野、权值共享、空间亚采样3种思想结合起来获得某种程度的位移、尺度、形变不变性,具有结构简单、训练参数少和适应性强等特点。一个基本的卷积神经网络结构可以分为3层:特征提取层(过滤器层)、特征映射层(非线性映射层)以及特征池化层(亚采样层),通过堆积多个基本网络结构可以形成一个深度卷积神经网络。
(1) 过滤器层:利用该层进行特征提取,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征。假设输入影像I是一个二维矩阵,大小为r×c,利用一个可训练的过滤器组K,尺寸为w×w,对其进行卷积运算,最终得到一个大小为((r-w)/s+1)×((c-w)/s+1)的输出Y
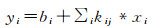 (4)
(4)
式中,*表示卷积运算;xi表示卷积层的输入;kij是卷积核参数;bi是偏差值;s为步长,每个滤波器对应一种特定的特征。
(2) 特征映射层:为保证特征有效性,利用一个非线性函数对过滤器层的结果进行映射,得到特征图F
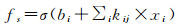 (5)
(5)
式中,σ是激活函数,常用的激活函数有tanh、sigmoid和softplus。tanh函数是sigmoid函数的一种变体,它的取值范围是[-1,1],而sigmoid取值范围是[0,1]。线性修正单元ReLU[21]与生物神经元受刺激后的激活模型最为接近,而且具有一定的稀疏性,计算简单,有助于提升效果,也逐渐被用来作为神经网络的激活函数。
(3) 特征池化层:通过卷积获得特征以后,理论上可以直接利用这些特征训练分类器,但实际上一个中等大小的图像卷积后的特征维度都在百万数量级,直接训练分类器很容易过拟合(over-fitting),因此需要对卷积特征进行下采样,即池化操作。将卷积特征图F分成大小为m×m的不相交区域,然后统计这些区域的平均值(或最大值)作为池化特征P,大小为{((r-w)/s+1)/m}×{((c-w)/s+1)/m}。池化后的特征维度大大降低,避免了过拟合,而且具备抗差性。
除了以上基本的网络层,为了更好地训练卷积网络,通常会加入一些技巧或策略,例如局部反差调整(local response normalization)和Dropout策略,局部反差调整通过将神经元激活值规范化,可以防止梯度弥散;Dropout能够有效避免过拟合,提高网络的泛化能力,合理地利用这些策略会加快网络的训练过程。
卷积神经网络是一种监督学习模型,需要一定的标记样本来训练,训练过程与传统的BP算法相似,所有权重在训练之前随机初始化,然后进行前向传播并输出结果,计算输出结果与实际样本标签的差,按极小化误差的方法反向传播调整权矩阵。假设有输入样本(X, Yp),前向传播后得到输出Op=Fn(…(F2(F1(XpW(1))W(2)…)W(n)),计算代价函数cos t=Op-Yp,然后利用随机梯度下降法或L-BFGS[22]优化算法求解。本文试验构建了一个13层的卷积神经网络,包括输入层、5个卷积层、两个池化层,两个局部反差调整层、两个全连接层和一个输出层,网络参数和结构如图 4所示,利用ReLU作为激活函数,采用最大池化,最后联合多层特征一起分类。利用显著性采样后,每幅影像由很多块代替,最后计算分类结果时,需要统计这些块的分类情况,将个数最多的类别作为该影像的最终分类结果。

|
| 图 4 本文试验构建的卷积神经网络结构参数图 Fig. 4 A convolutional neural network structure parameter map constructed in this paper |
2 高分影像场景分类试验
本文方法的整体流程如图 5所示,首先利用显著性探测算法,获取影像的显著区域,在对应的原始影像上采集样本块(包含3个波段);然后将采集的样本块划分为训练集和测试集,将训练集输入卷积神经网络中训练,提取层次特征并结合样本标签训练SVM分类器;测试阶段,利用分类器对样本块进行分类,获取样本块标签,由于每个场景影像由很多块组成,所以对样本块标签进行直方图统计,将最大频数所对应的标签作为最终场景影像的类别。

|
| 图 5 方法总体流程 Fig. 5 Overall architecture of the proposed method |
2.1 试验数据集
本文所用的两类高分辨率遥感影像分别是:①UC Merced 21类场景影像,该数据选自美国USGS国家城市地图图像中的不同地区的航空遥感影像,分辨率为0.3 m左右,每类有100幅,大小为256×256,影像类别具有高度的重复性,例如密集住宅区、中等住宅区和稀疏住宅区;②Wuhan 7类场景影像,该数据集是将武汉地区的QuickBird影像融合后,人工选取了7个场景类别,分辨率为0.6 m左右,每类有200幅,尺寸为256×256,影像示例如图 6所示。

|
| 图 6 武汉7类场景影像库 Fig. 6 Wuhan 7 scene datasets |
2.2 试验结果与分析
为了验证本文方法的有效性,根据采样策略的不同(有、无显著性)以及分类策略的不同(利用单层特征、利用多层特征)进行了交叉试验。无显著性采样的方法,直接从原始影像中随机选取相同数目的影像块进行分类;多层特征是指将两个全连接层(fc6和fc7)和第5个卷积层(C5)的特征联合起来,而单层特征只用最后的全连接层特征(fc7)。试验参数设置及结果如下所述。
(1) UC Merced:定义交叉路口、立交桥和河流的显著区域阈值β=0.3,其余类别的显著阈值α=0.8,每幅影像随机选取100块,每块大小为64×64×3,与文献[23]一样,每类影像随机选取80%作为训练样本,其余作为测试样本,卷积神经网络各层参数设置如图 4所示。几种交叉试验的分类结果见表 1。
| (%) | |||||
| 特征 | 无显著性 | 有显著性 | |||
| 单层特征 | 多层特征 | 单层特征 | 多层特征 | ||
| 精度 | 87.62 | 89.76 | 92.14 | 92.86 | |
从表 1的结果来看,利用显著性采样比直接采样的分类结果都高,说明显著性采样结果更具代表性,选取的样本都是与场景信息强相关的;通常利用卷积神经网络提取特征进行分类,都只用单层特征(输出层特征)。表 1结果说明结合不同层次特征进行分类相比单层特征分类精度有所提高,不同层次的特征增加了目标的可区分性。从图 7的分类混淆矩阵可以看出,飞机、海滩、丛林、港口、停车场、河流等大多数类别分类精度较高,甚至达到100%,由于这些场景内的目标复杂程度不高,且不同类别目标的差异性大,用显著性可以准确地提取出关键目标,识别出关键目标也就相应的识别出场景;而分类精度较低的类别主要是建筑物、密集住宅区、中等住宅区、稀疏住宅区,这些类别场景相似性高,区别仅在于密集程度不同,而利用显著性提取的都是建筑物,容易混淆,导致分类结果差。此外,针对图 1的类内差异性问题,从高尔夫球场的分类精度(90%)来看,有差异的影像都能正确地分为一类,说明本文方法能有效地解决这个问题;UC Merced 21类中比较相似的类别有高速公路、交叉路口、立交桥、跑道,这些可以看作道路类;建筑物、密集住宅区、中等住宅区、稀疏住宅区、活动住房这些可以看作建筑类。对于图 2的类间相似性问题,可以从这两个大类的分类结果来分析:表 2分别为道路类和建筑类的分类精度,从表中可以看出每个子类的精度至少在80%以上,平均分类精度也达到88%以上,说明对于相似性的类别,本文方法也能够有效的区分。表 3为已有分类方法的比较,本文方法总体分类精度达到92.86%,相比传统的词袋模型和主题模型方法,分类精度有了一定的提高。
| (%) | ||||||||||
| 类别子类 | 道路类 | 建筑类 | ||||||||
| 高速公路 | 交叉路口 | 立交桥 | 跑道 | 建筑物 | 密集住宅区 | 中等住宅区 | 稀疏住宅区 | 活动住房 | ||
| 精度 | 85 | 100 | 100 | 100 | 85 | 85 | 90 | 80 | 100 | |
| 平均精度 | 96.25 | 88 | ||||||||

|
| 图 7 UC Merced 21类卫星场景影像分类混淆矩阵(显著性+多层特征) Fig. 7 Confusion matrix showing the classification performance with the UC Merced 21 dataset(with saliency and multi-layer features) |
(2) Wuhan:该数据集是从大影像上人工选取的,影像类别数较少,采样块大小仍为64×64×3,每幅图选取100块,显著区域阈值α=0.8,选取80%影像作为训练,其余作为测试;卷积神经网络的参数与UC Merced基本相同(只是最后输出层参数不一样),也针对不同策略进行了交叉试验。表 4为不同策略交叉试验的分类结果。
由于Wuhan数据集是从实际的大影像选取的,类别数没有那么多,所以分类精度很高,从表 4可以看出词袋模型的分类精度也有91.36%,而利用卷积神经网络的精度达到98.93%,说明卷积特征对于目标具有很好的识别能力。此外,可以得出与UCM数据相同的结论,即利用显著性采样和联合多层特征,对于分类精度具有一定的提升。
3 结论本文针对高分辨率遥感影像多利用中、低层次特征,难以有效表达场景语义信息的问题,提出了一种联合显著性和多层卷积神经网络的分类算法。通过显著性采样,可以获取能够表达影像信息的有意义的关键目标,减弱了其他无关或次要目标的影响,降低了数据冗余;卷积神经网络具有权值共享,结构简单、训练参数少及适应性强等特点,能够逐层学习,获取高层次的特征,更好地表达场景信息。两类高分影像的结果表明,该方法能够有效提高分类精度,但是本文方法依然存在不足,例如,卷积神经网络的层次结构和参数设置是否最优依然是值得研究的问题;此外,对于只有细微差异的类别来说,像不同密度的住宅区,显著性算法也较难区分它们。以后的工作可以借鉴已有的网络模型结构进一步研究,以期得到更高的分类精度。
| [1] | CHERIYADAT A M. Unsupervised Feature Learning for Aerial Scene Classification[J]. IEEE Transactions on Geoscience and Remote Sensing , 2014, 52 (1) : 439 –451. DOI:10.1109/TGRS.2013.2241444 |
| [2] | VAILAYA A, FIGUEIREDO M A T, JAIN A K, et al. Image Classification for Content-based Indexing[J]. IEEE Transactions on Image Processing , 2001, 10 (1) : 117 –130. DOI:10.1109/83.892448 |
| [3] | SERRANO N, SAVAKIS A E, LUO Jiebo. Improved Scene Classification Using Efficient Low-level Features and Semantic Cues[J]. Pattern Recognition , 2004, 37 (9) : 1773 –1784. DOI:10.1016/j.patcog.2004.03.003 |
| [4] | OLIVA A, TORRALBA A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope[J]. International Journal of Computer Vision , 2001, 42 (3) : 145 –175. DOI:10.1023/A:1011139631724 |
| [5] | SIVIC J, ZISSERMAN A. Video Google: A Text Retrieval Approach to Object Matching in Videos[C]//Proceedings of the Ninth IEEE International Conference on Computer Vision. Nice, France: IEEE, 2003, 2: 1470-1477. |
| [6] | LAZEBNIK S, SCHMID C, PONCE J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories[C]//Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY: IEEE, 2006: 2169-2178. |
| [7] | YANG Yi, NEWSAM S. Spatial Pyramid Co-occurrence for Image Classification[C]//Proceedings of IEEE International Conference on Computer Vision. Barcelona: IEEE, 2011: 1465-1472. |
| [8] | BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet Allocation[J]. The Journal of Machine Learning Research , 2003, 3 : 993 –1022. |
| [9] | LIENOU M, MAITRE H, DATCU M. Semantic Annotation of Satellite Images Using Latent Dirichlet Allocation[J]. IEEE Geoscience and Remote Sensing Letters , 2010, 7 (1) : 28 –32. DOI:10.1109/LGRS.2009.2023536 |
| [10] | VĂDUVA C, GAVĂT I, DATCU M. Latent Dirichlet Allocation for Spatial Analysis of Satellite Images[J]. IEEE Transactions on Geoscience and Remote Sensing , 2013, 51 (5) : 2770 –2786. DOI:10.1109/TGRS.2012.2219314 |
| [11] | BOSCH A, ZISSERMAN A, MUÑOZ X. Scene Classification Using a Hybrid Generative/Discriminative Approach[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2008, 30 (4) : 712 –727. DOI:10.1109/TPAMI.2007.70716 |
| [12] | ZHANG Fan, DU Bo, ZHANG Lianpei. Saliency-guided Unsupervised Feature Learning for Scene Classification[J]. IEEE Transactions on Geoscience and Remote Sensing , 2015, 53 (4) : 2175 –2184. DOI:10.1109/TGRS.2014.2357078 |
| [13] | 赵爽.基于卷积神经网络的遥感图像分类方法研究[D].北京:中国地质大学(北京), 2015. ZHAO Shuang. Remote Sensing Image Classification Method Based on Convolutional Neural Networks[D]. Beijing: China University of Geosciences (Beijing), 2015. http://cdmd.cnki.com.cn/article/cdmd-11415-1015391341.htm |
| [14] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based Learning Applied to Document Recognition[J]. Proceedings of the IEEE , 1998, 86 (11) : 2278 –2324. DOI:10.1109/5.726791 |
| [15] | 解文杰.基于中层语义表示的图像场景分类研究[D].北京:北京交通大学, 2011. XIE Wenjie. Research on Middle Semantic Representation Based Image Scene Classification[D]. Beijing: Beijing Jiaotong University, 2011. http://cdmd.cnki.com.cn/article/cdmd-10004-1011102614.htm |
| [16] | CHENG Dongyang, SUN Tanfeng, JIANG Xinghao, et al. Unsupervised Feature Learning Using Markov Deep Belief Network[C]//Proceedings of the 2013 20th IEEE International Conference on Image Processing. Melbourne, VIC: IEEE, 2013: 260-264. |
| [17] | 温奇, 李苓苓, 刘庆杰, 等. 基于视觉显著性和图分割的高分辨率遥感影像中人工目标区域提取[J]. 测绘学报 , 2013, 42 (6) : 831–837. WEN Qi, LI Lingling, LIU Qingjie, et al. A Man-made Object Area Extraction Method Based on Visual Saliency Detection and Graph-cut Segmentation for High Resolution Remote Sensing Imagery[J]. Acta Geodaetica et Cartographica Sinica , 2013, 42 (6) : 831 –837. |
| [18] | MARGOLIN R, TAL A, ZELNIK-MANOR L. What Makesa Patch Distinct?[C]//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR: IEEE, 2013: 1139-1146. |
| [19] | BENGIO Y, COURVILLE A, VINCENT P. Representation Learning: A Review and New Perspectives[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2013, 35 (8) : 1798 –1828. DOI:10.1109/TPAMI.2013.50 |
| [20] | 余凯, 贾磊, 陈雨强, 等. 深度学习的昨天、今天和明天[J]. 计算机研究与发展 , 2013, 50 (9) : 1799–1804. YU Kai, JIA Lei, CHEN Yuqiang, et al. Deep Learning: Yesterday, Today, and Tomorrow[J]. Journal of Computer Research and Development , 2013, 50 (9) : 1799 –1804. |
| [21] | MAAS A L, HANNUN A Y, NG A Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models[C]//Proceedings of ICML Workshop on Deep Learning for Audio, Speech, and Language. [S.l.]: ICML, 2013: 1. |
| [22] | SCHMIDT M, VAN DEN BERG E, FRIEDLANDER M, et al. Optimizing Costly Functions with Simple Constraints: A Limited-memory Projected Quasi-Newton Algorithm[C]//Proceedings of the 12th International Conference on Artificial Intelligence and Statistics. Florida: ACM, 2009: 456-463. |
| [23] | YANG Y, NEWSAM S. Bag-of-visual-words and Spatial Extensions for Land-use Classification[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. San Jose: ACM, 2010: 270-279. http://www.oalib.com/references/17176337 |