



2. 中国科学院大学,北京 100101 ;
3. 江苏省地理信息资源开发与利用协同创新中心,江苏 南京 210023
2. University of Chinese Academy of Sciences, Beijing 100101, China ;
3. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing 210023,China
包含地理实体(如地名、组织机构、地缘政治实体)间语义关系(如从属、合作、继承关系)和空间关系(如拓扑、方位、距离关系)的文本资源在广义地理信息采集与服务中占据重要地位[1-2],为地图数据库更新提供了巨大潜能,催生了开放式地理实体关系抽取研究[3-5]。开放式地理实体关系抽取旨在从自然语言文本中抽取地理实体间的空间关系和语义关系,形成结构化的表达形式[6]。它不限定于处理规范的新闻文本或者特定领域文本,无须预先定义关系的类别;以“抽取”代替“识别”,挖掘文本中蕴含的一切关系实例,能更好地适应高动态、富信息的网络文本的处理需求[7]。
相比实体关系抽取[8],地理实体关系抽取有如下特殊性:①缺乏大规模地理实体关系标注语料[9]用于训练监督的机器学习模型,以检测种类繁多的关系类型;②缺乏典型的地理知识库作为启动弱监督机器学习模型的种子。现有的地理知识库(GeoNames Ontology、OSM SemanticNetwork、GeoWordNet等)仅限于描述面状地理实体间的“分离”、“包含”和“相邻”3种空间关系,远不能满足多类型地理实体关系抽取的需求;③文本蕴含的地理实体关系实例分布异质性极强,热点地理实体相关的关系描述频繁出现,而不受关注的地理实体文本描述较少;④地理实体关系抽取结果难以定量评价。人工逐条检查上万条地理实体关系实例的质量是不切实际的,而小规模的随机采样又无法计算系统的召回率。因此,从自然语言文本中抽取地理实体关系面临着巨大的挑战。
本文重在解决开放式地理实体关系抽取的两个核心问题:①缺乏大规模标注语料和地理知识库的前提下,如何自动产生地理实体间空间关系和语义关系的结构化元组;②如何定量评价开放式地理实体关系抽取效果。本文利用bootstrapping技术分析关系词的词法特征,引入到关键词提取的权值计算中,据此将共现地理实体组织成结构化形式,然后分析结果集的质量分布情况,计算关系抽取精度和召回率,并基于百度百科文本验证方法的有效性。
1 相关工作针对文本蕴含地理实体关系抽取的问题,大量的研究成果集中在模式匹配方法。该方法通过提取和泛化词法(句法)模式,可识别出有限的关系实例。文献[10]将蕴含“包含”和“相邻”空间关系的隐式表达(文本中未出现关系词)定义为词法模式,作为查询条件在Google和Yahoo中搜索新的地理实体关系实例。该方法适用于按照行政区划级别排列的规范化地址文本,但仅能抽取指定的两种地理实体关系。文献[11]使用人工设计的493种中文模式与网页摘要进行匹配,以获取显式表达(文本中出现关系词)的地理实体关系实例。该方法能识别出多种类型的地理实体关系,但需要预先准备大规模的空间词典和模式库。与文献[11]的方法相同,文献[12]使用234个空间动词建立语法规则,实现了意大利语空间关系抽取。上述的模式匹配方法,其模式发现过程仍依赖于手工劳动,需要领域专家知识;且有限的模式难以适应文本快速增长和变化需求。文献[13]基于自建立的大规模空间关系标注语料,采用序列比对的方法自动生成空间关系句法模式库。该方法提高了模式挖掘的自动化程度,但仍需耗费大量人力构建标注语料库。与之不同,关系抽取的模式发现过程充分利用了海量文本的冗余性,整个模式库的构建过程无须人工干预。利用该方法建立的经典关系抽取系统有Reverb、OLLIE、OpenIE。然而,这些系统仍需由领域专家预先定义词法或句法规则。
为了放松地理实体关系抽取方法对领域专家知识的限制,一些研究者使用监督的机器学习方法从文本中自动抽取地理实体关系:通过大规模的标记数据训练某个分类模型,再对未标记数据自动分配某种预定义的关系类型。该方法的主要障碍是缺乏可获取的地理实体关系标注语料。考虑到存在大量未标注的文本且人工标注语料的成本太高,自动生成大规模标注语料的弱监督学习方法逐步成为研究热点。文献[14]使用在线的酒店点评文本自动构建了地理实体“相邻”关系的标注语料,规模为10.6万个文档。文献[15]使用维基百科自动回标技术,建立了河流与水系的“流入”关系、郊区与城镇的“组成”关系。然而,上述自动构建标注语料的方法仅能建立指定类型的关系标注语料。当建立新类型的关系标注语料时,仍需一定的手工劳动,难以快速适应地理实体关系的多样性。此外,以空间本体为知识库的弱监督学习算法也备受关注。文献[16]通过手动建立空间本体,成功抽取了地理实体之间的拓扑和方位关系。相比自动生成大规模标注语料的方法,空间本体更容易扩展到新类型的地理实体关系抽取;然而该方法不能识别出一对地理实体之间的多种关系。
目前,业界尚未开展开放式地理实体关系抽取无监督机器学习方法研究,而在关系抽取领域已有大量的无监督机器学习研究成果。其中,频率统计[17-18]是一种广泛应用于无监督关系抽取的重要技术,其核心思想是通过统计词语频数反映词语重要性,并选择权值最大的词语作为关系名称。然而,频率统计方法要求表征关系的词语频繁出现,难以适用于稀疏分布的地理实体关系实例。
2 方 法地理实体关系抽取过程包含:数据获取、数据预处理和数学计算,如图 1所示。下文将重点阐述数学计算子过程。

|
| 图 1 地理实体关系抽取流程 Fig. 1 Flowchart of geo-entity relation extraction |
2.1 任务定义
本文研究范围仅限于抽取一个句子中共现的两个地理实体之间的空间关系词语和语义关系词语,且关系词语存在于句中,即显式表达的二元地理实体关系。针对一个句子中共现的两个地理实体(e1,e2);从所在的句中提取词语组成一个语境s,并过滤停用词“了”、“的”等。关键词抽取即是从集合s中选择一个词语k,使得k能表达一种空间关系或者语义关系。
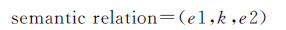 (1)
(1)
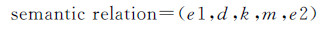 (2)
(2)
式(1)将语义关系实例作为属性表达式,用于描述地理实体指定类型的属性值。式(2)将空间关系实例作为位置表达式,用于描述一个地理实体相对于参考地理实体的空间位置。分析文本发现,空间关系表达习惯于同时使用方位和拓扑词语(“天津东临渤海”),或者同时使用方位、行为和度量词语(“西子湾距高雄市中心车程约20分钟”)。因此,式(2)中d表示方位词语(“东”、“中心”),m表示度量词语(“20分钟”)。
2.2 特征选择本文借鉴实体关系抽取和关键词提取方法,探索自然语言表达的地理实体关系文本在“词性”、“位置”、“长度”和“距离”方面的规律,为下文地理实体关系抽取提供先验知识。
(1) 词性POS(名词、动词、介词或者其他)。
(2) 位置LOC(e1的左边,e1和e2中间,e2的右边)。
(3) 左边有连词或者介词时的位置LCCP(e1的左边,e1和e2中间,e2的右边)。
(4) 到e1的距离DIS(e1)。
(5) 到句尾的距离DIS(e2)。
(6) 长度LEN,以字为单位。
(7)e1到e2的距离DIS(e1,e2),以词语为单位。
考虑到文本数量庞大且构建标注语料的成本太高,本文使用bootstrapping技术[19]分析上述7个特征。bootstrapping的原理是通过随机重采样,利用小样本来推测总体的统计量;当样本规模足够大时,基于样本的统计结果即可代表总体的水平。首先,随机排列句子,利用等间距抽样的方法选择100个句子;然后,手工标注每个句子的关系词语,形成标注语料;最后,从标注语料中随机采样形成一个等规模的新样本。该过程重复多次(10 000次)得到一个大规模的样本集合,统计每个样本中上述7个特征的值,计算出各项特征的均值。
统计结果如表 1、表 2所示,得到如下规律:①15%的句子不存在地理实体关系,超过半数的关系词为名词,余下的为动词和介词;②没有关系词位于e1的左边,大多数都位于e2的右边;③当关系词的左边存在连词或者介词时,94.16%的关系词位于e2的右边;④关系词到e1的距离为1的比例最大;⑤关系词位于句尾的比例最大;⑥关系词远离地理实体e2的概率最高;⑦名词长度至少为2个字,且跨度较大;⑧当存在关系词时,两个地理实体之间的距离不超过6个词语。
| 特征 | 比例 | |||||
| POS | 名词 | 动词 | 介词 | 其他 | 无关系 | |
| 55.97 | 26.92 | 2.01 | 0 | 15 | ||
| LOC | 左 | 中 | 右 | |||
| 0 | 24.89 | 60.11 | ||||
| LEFT (CCP) | 左 | 中 | 右 | |||
| 0 | 5.84 | 94.16 | ||||
| DIS( e1) | 0 | 1 | 2 | 3 | 4 | >4 |
| 0 | 18.92 | 3.99 | 0.99 | 0.99 | 0 | |
| DIS( e2) | 0 | 1 | 2 | 3 | 4 | >4 |
| 47.11 | 2.99 | 3.03 | 1.02 | 1.99 | 3.97 | |
| LEN | 名词 | 动词 | 介词 | 其他 |
| [2,10.94] | [1,2] | [1,1] | 0 | |
| DIS( e1,e2) | [1.13,5.95] |
与现有方法中获取的词法和句法规则不同[20],上述规律不是直接用于模式匹配,而是辅助数据预处理并将在2.3节使用统计学方法将其定量化表达,以指导地理实体关系抽取。同时,这些规律不是某个文本的变换形式,而是真实数据直观反映出的人们对关系表达的普遍认知。考虑到语言的地域、文化和认知差异性,bootstrapping方法针对不同体裁、风格的文本获取规律的取值范围将发生变化。
2.3 关键词提取基于bootstrapping方法得到的统计结果,本文引入词语的词性、位置和距离的重要性,设计关键词提取方法,如式(3)-(6)。针对词语i,wgti表示在词性、位置、距离影响下的重要性。POSi、locationi、distancei分别表示词性、位置、距离重要性。Ii、Ie1、Ie2、Iccp分别表示词语i、地理实体e1和e2、连词或者介词在句中的索引,表示句子长度。对于每一对地理实体(e1,e2),使用式(3)从语境s中选择一个重要程度最高的词语k,作为表达地理实体关系的关键词。公式中数字来源于2.2节的统计结果,如式(4)中0.56表示样本中有56%的关系词是名词。这些数字不是人为设定的固定值,会随着数据变化而变化。
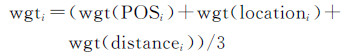 (3)
(3)
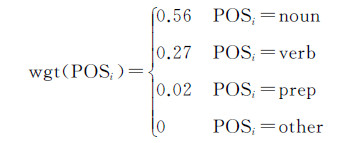 (4)
(4)
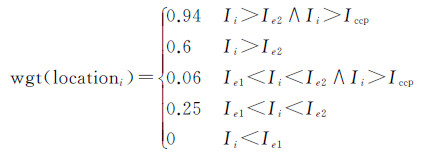 (5)
(5)
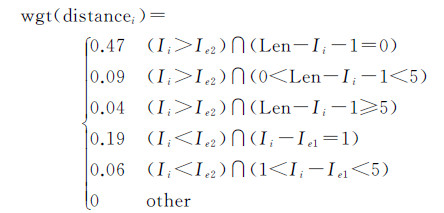 (6)
(6)
将每一对地理实体(e1,e2)和它的关键词k代入式(1)组成语义关系实例(e1,k,e2)。然而,本文仅为一对地理实体提取一个关键词,不能完整地描述空间关系实例(e1,d,k,m,e2)。具体地,方位词语d受到分词结果的影响:若d和拓扑词被划分成一个整体(“东邻”),则提取的关键词既蕴含方位关系又包含拓扑关系;若d和拓扑词被划分成两个部分(“东”和“邻”),则提取的关键词仅表达方位关系。同时,度量词语m通过预定义的规则来识别:①若句中存在数量词(词性为CD),且位于地理实体e2右边x个窗口内(取值为3),则保存该数量词和单位(词性为M)作为度量词m;②默认地关系表达式(1)和(2)中e1是主体,e2是客体,如果关键词k位于e2右边,则将e1设置为客体,e2设置为主体。
3 试 验 3.1 试验数据本文以新浪旅游的中国景点名称作为地理实体的基础地名,在百度百科中逐个获取对应的简介或正文首段,使用Stanford CoreNLP进行数据预处理(分段、分句、分词、词性标注、地理实体识别),构建了地理实体关系抽取的文本集合,数据分布如表 3所示。
| 新浪旅游中国景点 | 属于百度词条的景点 | 百度百科的原始句子 | 预处理后的试验句子 | 地理实体对 |
| 10 032 | 8275 | 114 962 | 17 741 | 18 588 |
3.2 真 值
本文使用bootstrapping技术,基于少量的手工评价结果,自动产生大规模的真值:首先,使用等间距随机采样法选择100个句子(不包括特征选择使用的句子),逐句标注地理实体关系实例;然后,从标注句子中随机采样形成一个等规模的新样本,该过程重复10 000次,共产生10 000个样本,作为评价结果质量的标注语料,每个语料的规模为100个句子。此外,本文将与经典的3种频率统计方法(Frequency、TF-IDF和PPMI)进行质量对比。
3.3 评价指标本文结合地理实体关系抽取任务描述,定义精度和召回率如表 4。Ri表示结果集i,G(unrel)i表示标注语料i中不存在关系的实例,G(rel)i表示标注语料i中存在关系的实例,每个标注语料的精度和召回率计算如式(7),均值计算如式(8)。
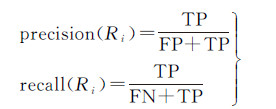 (7)
(7)
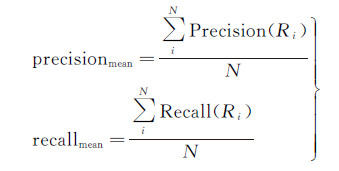 (8)
(8)
| predicted negative | predicted positive | |
| negative cases | TN =|Ri∩G(unrel)i | | FP =|G(unrel)i -Ri∩G(unrel)i| |
| positive cases | FN =|G(rel)i-Ri∩ G(rel)i| | TP =|Ri∩G(rel)i| |
4 结果与讨论
本文针对18 588对地理实体共抽取了27 012个关系实例,一对地理实体可拥有多种关系。4种方法的精度和召回率如图 2所示(本文方法表示为WFS)。试验结果显示,本文方法的精度和召回率分别为80%和87.79%,比其他3种统计方法的均值分别提高了约5%和23%。

|
| 图 2 4种方法的精度和召回率的均值 Fig. 2 Means of precision and recall of four approaches |
表 5展示了百度百科词条“海宁”的文本抽取地理实体关系的结果。其中,斜体表示根据句意表达的逻辑调整元素顺序后的关系实例,黑体表示扩展了度量词后的空间关系实例。本文针对一个句子中共现的两个地理实体仅提取一个关键词。例如表 5,若“东邻”被划分成一个词语,则提取的关系词为“东邻”;否则提取的关系词为“东”。为了避免分词结果不一致导致的信息误判,本文认为上述的两种关系抽取结果都是正确的。
| 文本 | 关系元组 |
|
海宁市位于中国长江三角洲南翼、浙江省北部,东邻海盐县,南濒钱塘江, 与绍兴上虞市、杭州萧山区隔江相望,西接杭州余杭区、江干区下沙, 北连桐乡市、嘉兴秀洲区。东距上海100公里,西接杭州,南濒钱塘江。 1986年撤县设市。海宁市是王国维、徐志摩、金庸、蒋百里等名人的故乡。 气候四季分明,是典型的江南水乡, 素有“鱼米之乡、丝绸之府、才子之乡、文化之邦、皮革之都”的美誉。 |
(浙江省,北部,海宁) |
| (海宁,东,海盐县) | |
| (海宁,南,钱塘江) | |
| (绍兴上虞市,相望,海宁) | |
| (杭州萧山区,相望,海宁) | |
| (海宁,西,杭州余杭区) | |
| (海宁,东,上海,100公里) | |
| (海宁,西,杭州) | |
| (海宁,南,钱塘江) | |
| (海宁,是,江南水乡) |
据统计,试验文本中97.63%的语境存在多个频数最大的词语。此时,TF-IDF和PPMI仅与词语在整个文本集合中的分布有关,将赋予低频词语更大的权值;而Frequency恰好相反,将赋予高频词语更大的权值。因此对于分布稀疏的地理实体关系实例,单纯地依靠频率统计难以判断词语在句中的重要程度。本文基于自然语言描述的词法特征,通过bootstrapping技术自动引入词语的词性、位置和距离的重要性,提取关键词作为描述地理实体关系的线索。对比Frequency、TF-IDF和PPMI 3种频率统计方法,本文方法产生了更高质量的关系实例。同时,本文方法无须领域专家知识和大规模标注语料,不限定地理实体关系的类型,仅需少量的标注语料即可启动算法,能快速适应新领域的地理实体关系抽取需求。
然而,本文抽取的地理实体关系实例中存在两类错误:①不存在关系的地理实体对提取出关系(FP);②存在关系的地理实体对提取出错误的关系(FN)。针对上述两类错误,本文使用bootstrapping技术对结果集中10 000个标注语料进行统计,结果如表 6所示。FP错误可分为4种情况:①是地理实体对之间不存在关系,本文方法仅能通过语境为空或者地理实体之间的距离大于6个词语判断不存在关系,尚未深入到句意理解层次;②是不能识别隐式的地理实体关系,本文的研究范围仅限于明确提及关键词的显式地理实体关系抽取;③和④均是由文本预处理带来的级联错误。FN错误可分为6种情况:①是当关系词语(“进入”)作为谓语且存在多个状语修饰词(“间或”“蜿蜒”),长距离的影响增大了状语修饰词的权值,无法准确提取出谓语关系词;②是当多个地理实体按照行政级别顺次排列(“中国”“云南省”“丽江市”),仅仅依靠词语本身的特征尚不能准确识别出嵌套地理实体之间复杂的空间关系;③是当多个词语组成一个复杂的关系描述,单个关键词语无法概括完整的语义;④-⑥均是由文本预处理带来的级联错误。
| 分类 | 均值 | 编号 | 子类 | 举例 |
| FP | 10.01% | ① | 不存在关系 | 海泉湾/GNE是香港中旅集团继建设深圳华侨城/GNE之后的又一力作 |
| ② | 隐式关系 | 东都/GNE(今河南省洛阳市/GNE) | ||
| ③ | 地理实体分词错误 | 中国造船业→中国/GNE | ||
| ④ | 地理实体类型错误 | 东北/DIR→东北/GNE | ||
| FN | 18% | ① | 状语修饰词过多 | 苏花公路/GNE间或蜿蜒进入平坦河口 三角洲/GNE腹地→(苏花公路,间或,三角洲) |
| ② | 嵌套的地理实体 | 大研古镇/GNE位于中国/GNE西南部云南/GNE的丽江市/GNE→(大研古镇,西南部,丽江市) | ||
| ③ | 关系表达不完整 | 汕尾红场/GNE是中国/GNE第一个红色苏维埃政权诞生的地方→(中国,地方,汕尾红场) | ||
| ④ | 分句错误 | 长白山天池湖北部在吉林省境内是松花江之源→(吉林省,之源,长白山天池湖) | ||
| ⑤ | 分词错误 | 枞阳县/GNE建有中国/GNE第1个野鸭繁殖基地→(中国,基地,枞阳县) | ||
| ⑥ | 词性标注错误 | 阿尼玛卿山/GNE又/v名/q大积石山/GNE→(阿尼玛卿山,又,大积石山) |
综上所述,本文针对显式表达的地理实体关系,仅考虑了词法特征,尚未深入到句法分析和语义理解层次。同时,本文未考虑中文分词、词性标注、地理实体识别、指代消解等环节带来的级联错误,文本预处理的质量有待提高;且本文仅使用百度百科进行试验,语料的规模和多样性有待进一步扩展。此外,本文产生的27 012个关系实例共有9148种关系类型,存在大量语义相似但描述不同的关系,例如“位于”“处于”“在”“地处”“坐落”均表达同一种空间关系。本文研究的关键词提取方法是语义聚类的基础,下一步将研究语义聚类问题,以减少关系实例表达的冗余,为地理实体高动态信息的增量更新提供基础数据。
5 结 论本文研究了开放式地理实体关系抽取中的关键词提取方法。通过bootstrapping技术验证了本文的关键词提取方法在精度和召回率上均优于3种经典的频率统计方法。同时,本文方法无须领域专家知识和大规模标注语料,不限定地理实体关系的类型,具有潜在的领域移植性。在后续的工作中,需要加入不同领域、体裁、规模的文本扩充试验,以验证方法的可移植性;同时需要研究语义聚类技术,以降低地理实体关系实例的冗余性。
| [1] |
陆锋, 张恒才. 大数据与广义GIS[J].武汉大学学报(信息科学版),2014, 39 (6) : 645 –654 .
LU Feng, ZHANG Hengcai. Big Data and Generalized GIS[J]. Geomatics and Information Science of Wuhan University,2014, 39 (6) : 645 –654 . |
| [2] |
刘纪平, 栗斌, 石丽红, 等. 一种本体驱动的地理空间事件相关信息自动检索方法[J].测绘学报,2011, 40 (4) : 502 –508 .
LIU Jiping, LI Bin, SHI Lihong, et al. An Automated Retrieval Method of Geo-spatial Event Information Based on Ontology[J]. Acta Geodaetica et Cartographica Sinica,2011, 40 (4) : 502 –508 . |
| [3] |
张春菊. 面向中文文本的事件时空与属性信息解析方法研究[J].测绘学报,2015, 44 (5) : 590 .DOI:10.11947/j.AGCS.2015.20140657.
ZHANG Chunju. Interpretation of Event Spatio-temporal and Attribute Information in Chinese Text[J]. Acta Geodaetica et Cartographica Sinica,2015, 44 (5) : 590 .DOI:10.11947/j.AGCS.2015.20140657. |
| [4] |
张恒才, 陆锋, 陈洁. 微博客蕴含交通信息的提取[J].中国图象图形学报,2013, 18 (1) : 123 –129 .
ZHANG Hengcai, LU Feng, CHEN Jie. Extracting Traffic Information from Massive Micro-blog Messages[J]. Journal of Image and Graphics,2013, 18 (1) : 123 –129 . |
| [5] | JONES C B, PURVES R S, CLOUGH P D, et al. Modelling Vague Places with Knowledge from the Web[J]. International Journal of Geographical Information Science,2008, 22 (10) : 1045 –1065 . |
| [6] | JONES C B, PURVES R S. Geographical Information Retrieval[J]. International Journal of Geographical Information Science,2008, 22 (3) : 219 –228 . |
| [7] |
赵军, 刘康, 周光有, 等. 开放式文本信息抽取[J].中文信息学报,2011, 25 (6) : 98 –110 .
ZHAO Jun, LIU Kang, ZHOU Guangyou, et al. Open Information Extraction[J]. Journal of Chinese Information Processing,2011, 25 (6) : 98 –110 . |
| [8] |
杨博, 蔡东风, 杨华. 开放式信息抽取研究进展[J].中文信息学报,2014, 28 (4) : 1 –11 .
YANG Bo, CAI Dongfeng, YANG Hua. Progress in Open Information Extraction[J]. Journal of Chinese Information Processing,2014, 28 (4) : 1 –11 . |
| [9] |
张雪英, 张春菊, 朱少楠. 中文文本的地理空间关系标注[J].测绘学报,2012, 41 (3) : 468 –474 .
ZHANG Xueying, ZHANG Chunju, ZHU Shaonan. Annotation for Geographical Spatial Relations in Chinese Text[J]. Acta Geodaetica et Cartographica Sinica,2012, 41 (3) : 468 –474 . |
| [10] | SCHOCKAERT S, SMART P D, ABDELMOTY A I, et al. Mining Topological Relations from the Web[C]//Proceedings of the 19th International Workshop on Database and Expert Systems Application. Turin: IEEE, 2008: 652-656. |
| [11] | CAO Cungen, WANG Shi, JIANG Lin. A Practical Approach to Extracting Names of Geographical Entities and Their Relations from the Web[C]//Proceedings of the 7th International Conference on Knowledge Science, Engineering and Management. Switzerland: Springer, 2014: 210-221. |
| [12] | ELIA A, GUGLIELMO D, MAISTO A, et al. A Linguistic-based Method for Automatically Extracting Spatial Relations from Large Non-structured Data[C]//Proceedings of the 13th International Conference on Algorithms and Architectures for Parallel Processing. Switzerland: Springer, 2013: 193-200. |
| [13] | ZHU Shaonan, ZHANG Xueying, ZHANG Chunju. Syntactic Pattern Recognition of Geospatial Relations Described in Natural Language[C]//Proceedings of the 2010 International Conference on Broadcast Technology and Multimedia Communication. New York: IEEE, 2010: 354-357. |
| [14] | WALLGRüN J O, KLIPPEL A, BALDWIN T. Building a Corpus of Spatial Relational Expressions Extracted from Web Documents[C]//Proceedings of the 8th Workshop on Geographic Information Retrieval. New York: ACM, 2014. |
| [15] | BLESSING A, SCHVTZE H. Fine-grained Geographical Relation Extraction from Wikipedia[C]//Proceedings of the 7th International Conference on Language Resources and Evaluation. Valletta: LREC, 2010. |
| [16] | LOGLISCI C, IENCO D, ROCHE M, et al. Toward Geographic Information Harvesting: Extraction of Spatial Relational Facts from Web Documents[C]//Proceedings of the 2012 IEEE 12th International Conference on Data Mining Workshops. Brussels: IEEE, 2012: 789-796. |
| [17] | MORO A, NAVIGLI R. Integrating Syntactic and Semantic Analysis into the Open Information Extraction Paradigm[C]//Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Beijing: [s.n.], 2013: 2148-2154. |
| [18] | LIU Zhiyuan, CHEN Xinxiong, ZHENG Yabin, et al. Automatic Keyphrase Extraction by Bridging Vocabulary Gap[C]//Proceedings of the 15th Conference on Computational Natural Language Learning. Stroudsburg: Association for Computational Linguistics, 2011: 135-144. |
| [19] | ABNEY S P. Bootstrapping[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. Stroudsburg: Association for Computational Linguistics, 2002: 360-367. |
| [20] |
邓敏, 徐锐, 李志林, 等. 空间查询中自然语言空间关系与度量空间关系的转换方法研究:以面目标为例[J].测绘学报,2009, 38 (6) : 527 –531 .
DENG Min, XU Rui, LI Zhilin, et al. A Spatial-query-driven Transformation between Metric Spatial Relations and Natural Language Spatial Relations: Taking Regions as Example[J]. Acta Geodaetica et Cartographica Sinica,2009, 38 (6) : 527 –531 . |