



随着我国城市化进程的加快,城市地物发生了翻天覆地的变化,特别是道路要素,其变化周期越来越短,变化程度越来越大,使得城市道路数据面临着严峻的更新任务。道路网更新的目的是对道路网中的变化信息进行识别与修改,而同名实体匹配是解决这一问题的关键技术。其基本原理是通过一系列相似度指标识别出不同来源地图数据库中表达现实世界同一地物的地图要素的过程[1]。同名实体匹配是后续数据集成、融合以及更新的基础,具有重要应用意义。据此,国内外研究学者围绕同名道路匹配进行了大量研究。
道路匹配属于线要素匹配,目前国内外学者对线要素匹配方法研究大致分为以下3类:①利用缓冲区增长方法进行匹配[2-4],简单易行,是线要素匹配的常用方法;②利用曲线自身几何特征进行匹配[5-11],主要是通过道路弧段的距离测度直接对道路弧段匹配,或者根据道路节点之间距离远近、拓扑结构相似性等对道路节点匹配,然后节点所对应道路弧段匹配;③综合运用多个评价指标,从整体到局部的策略匹配[12-16],主要运用道路网自身的空间结构特征进行匹配。
上述匹配方法大多从道路自身节点和弧段特征出发进行匹配,而对于道路邻域要素相似性的研究相对较少。而在实际匹配过程中,匹配双方数据间可能存在较大的几何位置偏差。如图 1所示,若是从道路自身节点和弧段特征进行匹配,则A2和B1匹配的可能性比较大,而实际上A1和B1才是一对同名实体。由此可见,若在匹配过程中顾及A1和B1的周边道路空间分布情况,可容易得出正确匹配结果。本文基于该思路,模仿人在读图时通过特征地物和空间关联寻找目标地物的思维过程,提出一种道路网联动匹配方法。该方法的优势在于有效地克服了非系统性位移误差所造成匹配错误,提高了匹配正确率,避免了道路逐个匹配的策略,提高了匹配效率,在数据位移较大、存在位置偏差的情况下具有一定优势。

|
| 图 1 误匹配示例 Fig. 1 Example of error matching |
1 构建道路网联动匹配模型
所谓联动匹配,即通过一个要素匹配带动另一个要素匹配,当一个要素匹配结束时,与该要素关联的其他要素根据关联关系,也随即完成匹配。它的核心思想是把匹配看成一种特征目标寻找、信息关联传递的推理过程。所以联动匹配实现的关键就是道路与道路之间关联关系的构建,其实质就是实现匹配信息在道路网间传递。
下面研究如何构建道路网联动匹配模型。值得注意的是,由于道路网琐碎的离散弧段使得道路空间关系量化表达变得复杂。本文借鉴Stroke技术[17-18]平滑连续的特点,对道路网进行重新组织,使道路的整体连贯性得以保持,更加符合人类的认知习惯。
1.1 道路网Stroke提取及等级划分在生成道路Stroke过程中,对数据进行拓扑处理,去除数据中存在的伪结点。如图 2所示,对拓扑处理后的道路网数据构建Stroke,首先选择一条弧段作为种子弧段,依次遍历与该种子弧段首、末结点关联的其他弧段,依据道路网Stroke的判断标准,判断是否存在与该种子弧段同属一条Stroke的弧段。若存在,则以该弧段作为种子弧段继续寻找其他弧段,依次不断循环,直至找不到满足Stroke构建条件的弧段,由此生成了一条道路。通过对现有Stroke生成算法的分析[19-21],本文依据属性一致性、方向一致性和趋势一致性这3种判断指标,作为关联弧段是否同属一条Stroke的判断标准。

|
| 图 2 道路Stroke构建原理 Fig. 2 Theory of road Stroke construction |
为了构建具有明显层次结构特征的联动匹配模型,需要对道路Stroke进行等级划分。在道路网的建设和规划时,往往按照道路的通行能力或者是用途差异将道路分为不同的等级。在矢量地图中,当道路的属性信息比较完整时,一般按照道路等级将道路分为高速公路、省道、县道、乡道等,在城市中分为主要道路和次要道路。但当道路的属性信息不完整时,只能依靠道路的几何特征和拓扑特征来区分道路等级。
借鉴已有对道路数据等级评价的方法[22-24],本文采取长度和通达性两个指标对道路进行量化等级划分。道路长度在获取上相对比较容易,显然道路越长,表明道路服务的区域就越大,重要性越高。道路通达性是指通过道路网中道路之间的相互连通关系实现道路网所在区域两点之间的通达。该指标通常用道路网络中心度来描述,道路的网络中心度越大,即所处的中心地位越高,说明该道路的通达性越好,从而发挥的作用越大。图 3为某城市道路网数据,对其提取Stroke,并按照长度和通达性两种指标,进行等级评价,共分为10级道路,即选取重要性前10%的道路作为10级道路(最高级),选取重要性前10%~20%的道路作为9级道路,依次类推,如图 3(c)所示,加粗实线为各等级道路示意。

|
| 图 3 城市道路网Stroke提取和等级划分结果 Fig. 3 Results of urban road network Stroke extraction and grade classification |
1.2 道路和道路骨架关联树构建
利用Stroke技术对整个城市道路网进行分类分级后,高等级的道路Stroke,如同一棵树的主干和粗枝,可反映出整个城市的大致形态结构,因此,高等级道路Stroke,也即主要道路,是整个城市的骨架,而那些较低等级的道路Stroke,就像树的细枝和树叶。如此,对整个城市道路网有了层次化的认知,将这种层次化认知模型映射到一个树状结构中,称之为骨架关联树,如图 4所示。在这种层次化认知模型中,每条高等级的道路Stroke可能与多条较低等级的道路Stroke具有关联关系,每条较低等级的道路Stroke可能与更多的更低等级的道路Stroke具有关联关系,因此这种骨架关联树具备以下特性:

|
| 图 4 道路网骨架关联树 Fig. 4 Road network skeleton relation tree |
(1) 相同等级道路Stroke之间是网状关系,不同等级道路Stroke之间形成层次结构关系。
(2) 一条高等级道路Stroke可能具备多个子节点。
(3) 一条低等级道路Stroke可能具备多个根节点。
骨架关联树构建的关键问题是如何找到根节点。本文提出一种基于树状结构索引的骨架关联树构建方法。对于整个城市道路网而言,选取最高等级的一条道路Stroke作为该骨架关联树的根节点,将与该道路相交或相邻的较低等级的道路Stroke作为子节点,之后,对每个子节点按照同样的方法找到各自的子节点,经过这样的索引过程,便构成了一条完整的骨架关联树。为了便于对道路进行存储和读取,本文将数据源1中道路Stroke命名为Sn-i,其中n代表道路等级,i代表该条道路在该等级道路层中的编号。同理,数据源2中的道路Stroke命名为Pm-j。
1.3 道路和道路联动匹配模型构建在图 1所示的示例中,人眼之所以能够判断出道路A1和B1是一对同名实体,是因为人脑对两个目标信息的获取并非是独立的,而是通过对两者的关联信息比较进行的。本文正是基于此,将人脑的这种感知能力通过结构化的方式表示出来,并进行相互关联分析,在模拟人脑这种综合信息的能力的基础上,构建道路网联动匹配模型,为道路网匹配提供新的思路。
联动匹配模型的构建原理如下,通过道路网骨架关联树,可以寻找多源空间数据在层次结构上的整体性和差异性。如图 5所示,归纳、分析数据源A与数据源B中每一条高等级道路Stroke和与其具有关联关系的低等级Stroke在空间数据中的分布状态,通过寻找两数据源结构相似的骨架关联树来构建道路网联动匹配模型,实现道路联动匹配的目的。

|
| 图 5 道路网联动匹配示例 Fig. 5 Example of road network linkage matching |
这种关联关系的构建可以通过图 6的示意性说明较好地阐释其原理。如图 6(a)和图 6(b)所示,选取突出的骨干道路如S10-0和P10-0作为起始匹配对象,对同一区域的数据源A和数据源B分别以S10-0和P10-0为起点建立各自的道路网骨架关联树,使其具有树状结构关系;对两个骨架关联树进行结构相似性比对,找出两数据源道路中结构相似的部分,并将这些结构相似的道路按照等级由高到低的顺序排列,如图 6(c)所示;这些结构相似道路即可构成道路网联动匹配模型,如图 6(d)。其余的不具有结构相似性的部分则是新增或消失的部分,可以在数据更新过程中直接对数据集进行增加或删除等操作。

|
| 图 6 道路网联动匹配模型构建原理 Fig. 6 Construction principle of road network linkage matching model |
2 道路网上下级空间关系相似性计算
如图 7所示,在构建道路网联动匹配模型时,一条高等级Stroke可能与多条低等级Stroke相交或相邻,这不利于匹配信息准确快速的传递,甚至会影响匹配效率。因此引入上下级空间关系相似性对匹配过程进行约束,以突出的骨干道路作为重要定位参考,通过待匹配道路相对于骨干道路在空间关系上的有序性和相似性来引导匹配进程,从而实现道路网联动匹配。

|
| 图 7 骨架关联树多节点示例 Fig. 7 Example of skeleton relation tree with multiple nodes |
当然,本文所说的空间关系是一条道路相对于骨干道路的空间关系(上下级拓扑关系、上下级方向关系、上下级距离关系等),这些关系虽然表达上不严格一致,但也绝不会违背制图规则。由于在构建道路网Stroke时,将同一等级的道路连接为一条Stroke,而这些道路有可能名称不同,因此很难用语义特征来判断相似性情况,故本文中暂不考虑语义相似性。
2.1 道路和道路上下级空间关系相似性计算 2.1.1 道路和道路上下级拓扑相似性计算线要素之间的拓扑关系可以粗略的归纳为相邻(部分重合)、重合、相交(相接)和相离4种关系。参考传统的拓扑关系概念邻域图[25-26],如图 8所示,因为在道路网中相交和相邻的道路关联相似性比较大,故本文将相交和相邻视为邻域内关系,本文所指空间关系相似性主要就是计算邻域内道路间的空间关系相似性。通常将目标道路的邻域道路数量作为其拓扑总数,根据骨架关联树的特点,将拓扑相似性分为上级拓扑相似性和下级拓扑相似性两部分,即以一对同名道路的上一等级邻域道路数量作为上级拓扑总数,以该条道路的下一等级邻域道路数量作为下级拓扑总数。如图 9所示,道路S8-1的道路等级为8,与S8-1相交或相邻的9级道路数量为2,则该条道路的上级拓扑总数为2;与S8-1相交或相邻的7级道路数量为4,那么该条道路的下级拓扑总数为6。

|
| 图 8 线要素间拓扑关系邻域图 Fig. 8 The neighborhood figure of topological relationships between line elements |

|
| 图 9 线要素拓扑总数计算示例 Fig. 9 Total number computation of line elements topology |
按照这种计算方法,两组数据源之间的上下级拓扑相似性可表示为
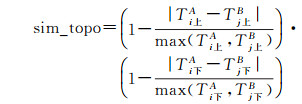 (1)
(1)
式中,Ti上A为数据源A中第i(
方向特征是线要素匹配中的重要判断指标。为了更准确地确定道路间关联关系,本文采用目标道路自身方向和目标道路邻域道路群组方向相结合的方法进行道路方向相似性计算。
2.1.2.1 目标道路自身方向相似性计算Stroke的方向分为整体方向和局部方向,整体方向是指用Stroke首末结点的连线相对于水平轴旋转的角度来近似描述,局部方向可用组成该条Stroke的小弧段的方位角表示。现实中,多源数据由于来源不同,采集方法不同,相互之间在局部细节形态上可能差异较大,当把道路弧段连接成Stroke时,原来的同名道路之间都会存在或多或少的位置偏差,这给Stroke方向计算带来了困难。如图 10所示,两幅不同的数据集中同名Stroke分别为S7-1和P7-1,两者的整体方向分别为θ1和θ2,经过计算,得到θ1=122.78°和θ2=136.67°,两者的差异度为13.89°。这是因为组成S7-1和P7-1的道路弧段个数不同,造成了位置偏差。

|
| 图 10 道路网局部差异情况 Fig. 10 Local difference of road network |
针对上述情况,本文借鉴文献[15]中Stroke方向相似性计算方法,连接道路Stroke的特征点形成新的弧段,将各弧段的相关长度系数作为权值,对各弧段的方位角加权求值,以此作为度量Stroke自身方向的指标。如图 11所示,设组成Stroke的道路弧段总长度为L,第i个道路弧段的长度为Li,则相关长度系数为
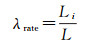 (2)
(2)

|
| 图 11 方向关系相似性量化表达示例 Fig. 11 Example of quantitative expression of direction relation similarity |
将该值作为计算方向均值的权值,得到描述整条道路Stroke方向的计算模型
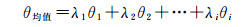 (3)
(3)
式中,θi为为第i条连线与x轴正方向的夹角。依据此度量方法,得出目标道路自身方向相似性的计算公式为
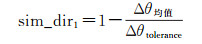 (4)
(4)
式中,Δθ均值为两条Stroke方向均值的差值,即Δθ均值=θ均值1-θ均值2;Δθtolerance为两条待匹配Stroke间的方向均值差异阈值。
2.1.2.2 上下级方向相似性计算若只是从目标道路自身弧段特征出发进行方向相似性计算,那么容易出现图 1所示的误匹配情况。所以本文在单个道路方向度量的基础上引入上下级道路方向相似性计算,以目标道路周边的邻域道路作为重要参考,进行道路群组的方向相似性计算。以图 9中的8级道路S8-1为例,在S8-1邻域内的9级道路有2条,在S8-1邻域内的7级道路有4条,那么S8-1的上下级道路总数为6条,这6条上下级道路就相当于一个道路群组。
道路群组方向相似性的计算方法如下:
首先利用上一节中道路自身方向的计算方法计算单个道路的方向,然后以坐标原点为原点,以一定长度为半径,将线要素的方向关系用离散点表示,并拟合该离散点群的标准差椭圆,即将线群转化为点群计算,如图 12所示。标准差椭圆是用来描述群组目标分布方向偏离的,由经典统计分析学中的样本标准差扩展而来(图 13)。空间统计中的欧氏距离,就相当于经典统计中的标准差。标准差表示观测值对均值的偏离情况,标准距离则表示各点的空间位置对平均中心位置或空间均值的偏离情况[27]。

|
| 图 12 拟合椭圆 Fig. 12 Schematic of fitting ellipse |

|
| 图 13 标准差椭圆 Fig. 13 Standard deviation ellipse |
在离散点集的原始坐标系(XOY)下,假设存在某一方向,所有离散点到该方向的标准差距离最小,那么该方向与原坐标轴的X方向的夹角就是点集的定向方向。将坐标轴进行旋转形成新的坐标系(X′O′Y′),新坐标系的坐标原点为点集中所有点的平均值中点(xmc, ymc)。标准差椭圆的计算方法简述如下:
(1) 坐标变换。对分布在研究区域内的每个点(xi, yi)进行坐标变换xi′=xi-xmc,yi′=yi-ymc
(2) 计算转角θ。根据以下公式计算点群的整体分布方向
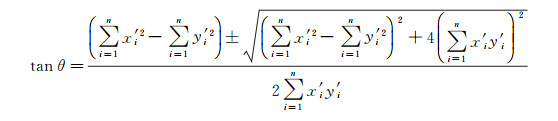 (5)
(5)
(3) 计算沿长轴方向的标准差δx和短轴方向的标准差δy
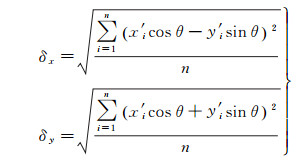 (6)
(6)
有了椭圆中心、转角、长、短轴,就可以确定一个标准差椭圆(图 13)。
对于生成的标准差椭圆,椭圆的长轴方向代表了对应的点群的主要分布方向,所有点到该方向的标准差距离最小。对于标准差椭圆夹角分别为θ1、θ2的两个道路群组进行方向相似性计算,同时对计算结果进行归一化处理,可以取θ的余弦来计算其相似性。具体的相似性计算公式为
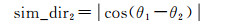 (7)
(7)
常见的线要素距离度量方法有3种:欧氏距离、Hausdorff距离和Fréchet距离。根据人对道路距离的认知习惯,本文采用欧氏距离作为距离度量指标,提出一种顾及上下级关系的距离度量方法。即提取目标道路中心点,计算目标道路中心点与其邻域内上级和下级所有道路的中心点距离,然后对这些距离求和,进行加权求平均值,以此平均值作为目标道路的距离度量值,本文称这样的距离值为平均中心距离值。所以对于数据源A和数据源B中的两条道路,其上下级距离相似度计算公式为
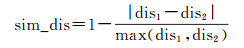 (8)
(8)
式中,dis1、dis2为两个同名道路平均中心距离值。
2.2 道路和道路上下级空间关系总相似性计算以上分别定义了邻域道路空间关系的拓扑、方向和距离相似性,根据Egenhofer和Mark提出的“拓扑关系起主导作用,其他可度量关系起提炼作用”的原则[26],突出拓扑关系在空间关系中的关键作用,在对邻域道路之间空间关系相似性进行整体度量时,对上述3种空间关系相似性分别赋予不同的权值。采用文献[28]中对拓扑、方向以及距离关系的权值设置方法,对以上3种空间关系相似性度量分别赋予不同的权值,即对上下级拓扑相似度、方向相似度和距离相似度,分别赋予0.4、0.3、0.3的权值。所以,邻域道路空间关系总相似度的计算公式为
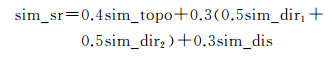 (9)
(9)
道路网联动匹配的特点就是通过一条高等级道路的匹配带动与其具有关联关系的多条低等级道路进行匹配,而要实现准确联动匹配的前提是道路本身的特征相似和其上下级道路空间关系相似保持高度一致性。基于这一原则,假设两数据源中目标道路和参考道路的上级拓扑总数和下级拓扑总数均相等,且上下级空间关系总相似性数值大致相同,如果两者在一定条件下同时成立,证明目标道路组成的道路群组和参考道路组成的道路群组两两互为同名道路。其具体匹配过程如下:
步骤1 添加匹配标记变量。将两数据源中所有未匹配的道路添加匹配标记变量NUL=0,若在匹配过程中有道路匹配成功,则NUL=1。对于NUL=1的道路,就不会再作为待匹配道路参与匹配。
步骤2 选取突出骨干道路作为匹配的起始对象。设数据源A中10级和9级道路集合为A={a1, a2, …, am},数据源B中与其对应的10级和9级道路集合为B={b1, b2, …, bn},将集合A和集合B中的道路运用缓冲区增长法进行匹配,并将匹配成功的道路NUL赋值为1。值得注意的是,若连续选取集合A和集合B中的道路均未匹配成功,那么只有寻求操作员协助标注起始匹配对象。
步骤3 匹配标记变量判断。将数据源A中NUL=0的道路添加到集合S,同理,将数据源B中NUL=0的道路添加到集合V。
步骤4 匹配信息在道路网联动匹配模型间的传递。在集合A中任意选择一条道路ai(i∈0, m),选择集合B中与ai对应的同名道路bj(j∈0, n)。
步骤5 在集合S中选取与ai相交或相邻的低等级(8级或8级以下)道路c;同理,在集合V中选取与bj相交或相邻的低等级(8级或8级以下)道路d。若道路c和道路d是相同等级(grade)道路,那么寻找道路c的上下级道路,组成目标局部道路网络H={a1, a2…ai, c…εi},寻找道路d的上下级道路,组成参考局部道路网络G={b1, b2…bj, d…νj},并转到步骤6。若道路c和道路d不是相同等级道路,重新在集合V中选取与bj相交或相邻的低等级(8级或8级以下)道路d′重复上述步骤,直到没有满足与道路c等级相同的道路为止,这时转到步骤4。
步骤6 上下级空间关系相似性计算。若(H,G)中道路c和道路d的上级拓扑总数和下级拓扑总数都相等,且上下级空间关系总相似性大于设置的阈值。若上述假设成立,转到步骤7。若上述假设不成立,转到步骤8。
步骤7 道路c和道路d互为同名道路,集合H和G中的道路两两之间可能也互为同名道路。对集合H与G中的道路进行缓冲区增长法判断,确定两两同名道路之间的对应关系,转到步骤9。
步骤8 计算((H,G))中道路的上下级空间关系总相似性,若相似性数值大于阈值,则道路c和道路d是一对同名道路,将道路c和道路d的NUL值赋值为1,并转到步骤10;若相似性数值小于阈值,删除集合G中的道路,选取在空间位置上与道路bj相交或相邻的另一条低等级道路d′,并保持道路c不变,转到步骤5。
步骤9 将集合H和G中的道路NUL赋值为1,并选取集合H和G的同名道路作为新的起始对象ai′和bj′,继续上述步骤5的处理,直到这条骨架关联树匹配结束。
步骤10 将该对同名道路NUL赋值为1,并以此为新的起始对象ai′和bj′,继续上述步骤5的处理,直到这条骨架关联树匹配结束。
匹配流程如图 14所示。

|
| 图 14 联动匹配流程 Fig. 14 Flow chart of linkage matching |
3.2 特殊情况处理
道路网十分复杂,具有较强的不确定性,在利用本文方法进行匹配时需要考虑下面两种特殊情况:
3.2.1 道路等级评价时同名道路被划分为不同的道路等级在对道路网进行等级评价时,两幅图中的同名道路可能被划分为不同的等级,由于本文方法只在相同等级的道路集合中搜索关联匹配对象,这就造成了原本存在匹配对象的要素被错误地判断为无匹配对象的情况。
针对这种情况,采用“缓冲区增长匹配”的思路解决。当数据源A中的道路在对应的数据源B中搜索判断后,若无匹配对象,尚不能断定其不存在匹配关系,而要将其加入道路“候选匹配集”中。当联动匹配整体结束后,对缓冲匹配集中的每条道路,重新在道路数据源B中进行整体遍历判断其是否确实不存在匹配对象。若存在道路与之匹配,则将其纳入匹配结果中;若仍无匹配对象,此时确定该道路不存在匹配关系,判断为新增道路。
“缓冲区增长匹配”确保了匹配结果的正确,虽然一定程度上增加了匹配判断总次数,但是这种情况相对很少,因此不会对匹配效率产生较大影响。
3.2.2 无法满足联动匹配模型中道路间关联关系构建条件联动匹配流程图中判断匹配信息传递结束的条件是双方数据中道路的数据的匹配标记变量值同时为1,这是理想的理论情况。实际情况中,如果某区域经历了大面积重建,就会出现部分区域道路不满足构建关联模型的阈值的情况,无法完成匹配信息的传递,其道路匹配标记变量值依然为0。若仍按原流程进行则会出现误匹配或者无匹配情况。针对这类对象,只能将标记值为0的未匹配道路加入新的候选匹配图层,将双方看成是新的数据源,采用“缓冲区增长匹配”方法进行匹配。若此过程后仍存在匹配标识值为0的道路,则将其判定为新增道路。
4 试验与分析 4.1 试验数据及对比试验方法为验证本文方法的有效性和适用性,选择环形放射式、方格网式和混合式3种不同形式的城市道路网数据进行试验。分别选择成都、西安和北京3组不同来源相同比例尺的数据作为上述路网代表进行试验,目的是测试路网形式不同是否会影响联动匹配信息传递,从而检验本文方法的适用性。3种路网形式数据叠加显示效果如图 15(a)、图 16(a)与图 17(a)所示,由图中可以看出,尽管经过了数据预处理和系统误差纠正,两幅图之间仍存在一定的位置偏差。同时,由于文献[16]将每条道路作为一个整体,基于Stroke层次结构模型进行城市道路网匹配,具有一定的时效性和科学性,所以本文选取文献[16]中方法(以下简称为层次结构方法)作对比试验。

|
| 图 15 环形放射式道路数据预处理 Fig. 15 Ring radial road data preprocessing |

|
| 图 16 方格网式道路数据预处理 Fig. 16 Grid type road data preprocessing |

|
| 图 17 混合式道路数据预处理 Fig. 17 Mixed road data preprocessing |
4.2 匹配结果
对不同路网形式的数据构建Stroke并进行等级划分,完成构建Stroke的叠加效果如图 15(b)、图 16(b)、图 17(b)所示。由图中可以看出,环形放射式和混合式道路网构完Stroke后同名道路大多被划分为相同等级,而方格网式道路网构完Stroke后存在较多的同名道路被划分为不同等级的情况,这在匹配过程中就要用到3.2节中特殊情况处理的方法。表 1的统计结果显示经过Stroke提取后道路网数据得以大幅度简化,这有利于提高联动匹配效率。
| 道路类型 | 道路网弧段数量 | Stroke数量 |
| 环形放射式 | 577/585 | 136/140 |
| 方格网式 | 522/513 | 113/114 |
| 混合式 | 1092/1101 | 220/230 |
分别对3组道路类型数据构建骨架关联树,然后按照3.1节所述试验步骤进行空间关系相似性计算,从而使匹配结果得以从高等级道路传递到低等级道路,实现联动匹配。图 18为环形放射式道路数据中一条高等级骨干道路的匹配结果示意。由图中可以看出一条高等级道路带动了数条低等级道路进行匹配,取得很好的匹配结果,有效提高匹配效率。图 19(a)、图 20(a)与图 21(a)分别为本文方法进行匹配得到的结果,图中黑色短线为匹配标识线。同时,对同样数据采用层次结构方法进行试验,图 18(b)、图 19(b)与图 20(b)分别为层次结构方法进行匹配得到的结果。由表 2可知,层次结构方法对于3种不同路网形式道路数据匹配正确率分别为68.33%、69.81%和76.92%,而本文方法匹配正确率均超过75%。

|
| 图 18 一条高等级骨干道路联动匹配结果示例 Fig. 18 Example of the results of a high level backbone road linkage matching |

|
| 图 19 环形放射式路网匹配结果 Fig. 19 Result of ring radial road network |

|
| 图 20 方格网式路网匹配结果 Fig. 20 Result of grid road network matching |

|
| 图 21 混合式路网匹配结果 Fig. 21 Result of mixed road network matching |
| (%) | |||||
| 路网形式 | 匹配方法 | 匹配率 | 未匹配率 | 匹配正确率 | 匹配错误率 |
| 环形放射式(成都) | 本文方法 | 87.50 | 12.50 | 80.67 | 19.33 |
| 层次结构法 | 44.12 | 55.88 | 68.33 | 31.67 | |
| 方格网式(西安) | 本文方法 | 72.57 | 27.43 | 76.83 | 23.17 |
| 层次结构法 | 46.90 | 53.10 | 69.81 | 30.19 | |
| 混合式(北京) | 本文方法 | 81.81 | 18.19 | 83.33 | 16.67 |
| 层次结构法 | 59.09 | 40.91 | 76.92 | 23.08 | |
根据试验结果进行统计,从匹配率与匹配正确率两方面进行试验对比分析。匹配率、匹配正确率是衡量匹配结果质量的重要指标,其中匹配率又称查全率,是指匹配结果中实现匹配的要素个数与同名要素个数的比值;匹配正确率是指匹配结果中正确匹配的要素个数与匹配要素个数的比值。试验结果见表 2。
表 3所示为联动匹配方法、层次结构方法传统缓冲区增长方法匹配时间的统计结果。从中看出,在匹配消耗时间方面,联动匹配方法与层次结构法时间耗时相当,但是与传统缓冲区增长法相比,联动匹配方法大幅减少了匹配时间,缓冲区匹配方法的耗时大约是本文方法的2倍。因此联动匹配方法有效提高了匹配效率。
| s | ||
| 路网形式 | 匹配方法 | 匹配时间 |
| 环形放射式(成都) | 本文方法 | 25.44 |
| 层次结构法 | 23.25 | |
| 缓冲区增长法 | 51.56 | |
| 方格网式(西安) | 本文方法 | 10.43 |
| 层次结构法 | 13.74 | |
| 缓冲区增长法 | 22.29 | |
| 混合式(北京) | 本文方法 | 43.56 |
| 层次结构法 | 44.74 | |
| 缓冲区增长法 | 112.70 | |
4.3 试验分析
对两种算法的匹配结果作如下分析:
(1) 本文方法在避免了全局遍历搜索候选匹配对象的基础上,采取了一条高等级道路匹配结果带动多条与其相关的低等级道路进行匹配的联动匹配策略,从而减少了匹配判断时间,提高了匹配效率。
(2) 本文在道路网进行Stroke提取和等级划分后,利用道路网上下级空间关系相似性构建道路网联动匹配模型,充分发挥骨干道路在匹配过程中定位参考的优势,对于位置偏差较大的道路数据具有较强的适应性,故本文方法得到较好的匹配结果。而文献[16]所述的层次结构方法没有顾及道路邻域要素对匹配结果的影响,所以对于几何位置偏差较大的数据适应性相对较差。
(3) 对于本文方法匹配结果中出现的错误情况,原因在于不同来源的道路数据存在较强的不确定性,同名道路空间特征和几何特征相似度也可能较低,而非同名道路间也可能具有较高的相似度,这也可能造成错误匹配。但是,这种情况出现概率较小,所以本文方法基本能够保证大部分的道路匹配结果的正确性。
通过以上试验对比分析,联动匹配方法在匹配正确率和匹配效率两个方面具有以下特点:
(1) 匹配正确率:①对于存在位置偏差的数据,道路网联动匹配方法充分利用骨干道路在匹配中定位参考的优势,使匹配信息在关联道路之间进行传递,在一定程度上避免了几何位置偏差对匹配结果的影响,有效提高了匹配正确率;②对于不存在明显位置偏差的匹配数据,由于联动匹配缩小了候选匹配集的数据搜索范围,能够减少周边道路的干扰,从而提高匹配正确率。
(2) 匹配效率。联动匹配的特点就是通过一条高等级道路匹配带动与其具有关联关系的多条低等级道路进行匹配,大幅减少了匹配判断次数,使得在匹配判断总次数方面此方法远远少于整体遍历式匹配方法。因此本文方法能够减少匹配时间、提高匹配效率。
(3) 适用范围。联动匹配在3种不同形式的路网中均有较好的匹配效果,不会受到道路形式的影响,因此,联动匹配适用于多种形态的路网。
5 结论本文模仿人在读图时通过特征地物和空间关联寻找目标地物的思维过程,将匹配看作是一种特征目标寻找、信息关联传递的推理过程。运用Stroke技术将复杂道路网进行重新组织和等级划分,在匹配过程中以上下级空间关系相似性为约束条件,以相邻道路作为定位参考,构造具有明显层次特性的道路网联动匹配模型,最后,以突出的骨干道路作为起始匹配对象,实现了匹配信息在道路之间的传递,达到了联动匹配的目的。与Stroke层次结构方法和传统的缓冲区匹配方法的试验对比验证了本文方法在效率和准确率方面的优势。尤其对于存在明显几何位置偏差的数据,本文方法具有较强的适应性。
进一步研究的难点是:本文目前只针对相同或相近比例尺道路网进行了试验和对比分析。下一步研究的方向是探寻将该算法应用于一对多和多对多匹配情况。
| [1] | QUDDUS M A, OCHIENG W Y, NOLAND R B. Map Matching Algorithms for Intelligent Transport Systems Applications[C]//Proceedings of the 13th World Congress on Intelligent Transport Systems and Services. London: ITRD, 2006. |
| [2] | WALTER V, FRITSCH D. Matching Spatial Data Sets: A Statistical Approach[J]. International Journal of Geographical Information Science, 1999, 13(5): 445–473. DOI:10.1080/136588199241157 |
| [3] | MANTEL D, LIPECK U. Matching Cartographic Objects in Spatial Databases[C]//Proceedings of the ISPRS Congress, Commission 4. Istanbul, Turkey: ISPRS, 2004. |
| [4] | ZHANG Meng, MENG Liqiu. An Iterative Road-matching Approach for the Integration of Postal Data[J]. Computers, Environment and Urban Systems, 2007, 31(5): 597–615. DOI:10.1016/j.compenvurbsys.2007.08.008 |
| [5] | GABAY Y, DOYTSHER Y. Adjustment of Line Maps[C]//Proceedings of the GIS/LIS'94. Phoenix, Arizona:[s.n.], 1994: 191-199. |
| [6] | MUSTIÈRE S. Results of Experiments on Automated Matching of Networks at Different Scales[C]//Proceedings of the ISPRS Workshop:Multiple Representation and Interoperability of Spatial Data. Hannover, Germany: ISPRS, 2006. |
| [7] | MUSTIÈRE S, DEVOGELE T. Matching Networks with Different Levels of Detail[J]. GeoInformatica, 2008, 12(4): 435–453. DOI:10.1007/s10707-007-0040-1 |
| [8] | DENG Min, LI Zhilin, CHEN Xiaoyong. Extended Hausdorff Distance for Spatial Objects in GIS[J]. International Journal of Geographical Information Science, 2007, 21(4): 459–475. DOI:10.1080/13658810601073315 |
| [9] | ZHANG Meng, SHI Wei, MENG Liqiu. A Generic Matching Algorithm for Line Networks of Different Resolutions[C]//Proceedings of the 8th ICA Workshop on Generalisation and Multiple Representation. Coruña, Spain:[s.n.], 2005. |
| [10] | 陈玉敏, 龚健雅, 史文中. 多尺度道路网的距离匹配算法研究[J]. 测绘学报, 2007, 36(1): 84–90. CHEN Yumin, GONG Jianya, SHI Wenzhong. A Distance-based Matching Algorithm for Multi-scale Road Networks[J]. Acta Geodaetica et Cartographica Sinica, 2007, 36(1): 84–90. DOI:10.3321/j.issn:1001-1595.2007.01.015 |
| [11] | ZHANG M. Methods and Implementations of Road-network Matching[D]. Munich, Germany: Technical University of Munich, 2009: 47-94. |
| [12] | 童小华, 邓愫愫, 史文中. 基于概率的地图实体匹配方法[J]. 测绘学报, 2007, 36(2): 210–217. TONG Xiaohua, DENG Susu, SHI Wenzhong. A Probabilistic Theory-based Matching Method[J]. Acta Geodaetica et Cartographica Sinica, 2007, 36(2): 210–217. DOI:10.3321/j.issn:1001-1595.2007.02.017 |
| [13] | 赵东保, 盛业华. 全局寻优的矢量道路网自动匹配方法研究[J]. 测绘学报, 2010, 39(4): 416–421. ZHAO Dongbao, SHENG Yehua. Research on Automatic Matching of Vector Road Networks Based on Global Optimization[J]. Acta Geodaetica et Cartographica Sinica, 2010, 39(4): 416–421. |
| [14] | 张云菲, 杨必胜, 栾学晨. 利用概率松弛法的城市路网自动匹配[J]. 测绘学报, 2012, 41(6): 933–939. ZHANG Yunfei, YANG Bisheng, LUAN Xuechen. Automated Matching Urban Road Networks Using Probabilistic Relaxation[J]. Acta Geodaetica et Cartographica Sinica, 2012, 41(6): 933–939. |
| [15] | 刘海龙, 钱海忠, 王骁, 等. 采用层次分析法的道路网整体匹配方法[J]. 武汉大学学报(信息科学版), 2015, 40(5): 644–651. LIU Hailong, QIAN Haizhong, WANG Xiao, et al. Road Networks Global Matching Method Using Analytical Hierarchy Process[J]. Geomatics and Information Science of Wuhan University, 2015, 40(5): 644–651. |
| [16] | 刘海龙, 钱海忠, 黄智深, 等. 采用Stroke层次结构模型的道路网匹配方法[J]. 测绘科学技术学报, 2013, 30(6): 647–651. LIU Hailong, QIAN Haizhong, HUANG Zhishen, et al. Road Network Matching Method with Stroke-hierarchical Model[J]. Journal of Geomatics Science and Technology, 2013, 30(6): 647–651. |
| [17] | THOMSON R C, RICHARDSON D E. The "Good Continuation" Principle of Perceptual Organization Applied to the Generalization of Road Networks[C]//Proceedings of the 19th International Cartographic Conference. Ottawa, Canada:[s.n.], 1999: 1215-1223. |
| [18] | THOMSON R C. The Stroke Concept in Geographic Network Generalization and Analysis[C]//Proceedings of the 12th International Symposium on Spatial Data Handling. Vienna, Austria:[s.n.], 2006: 681-697. |
| [19] | ANG Y H, LI Z, ONG S H. Image Retrieval Based on Multidimensional Feature Properties[C]//Proceedings of the SPIE 2420, Storage and Retrieval for Image and Video Databases III. San Jose, CA: SPIE, 1995: 47-57. |
| [20] | 翟仁健.基于全局一致性评价的多尺度矢量空间数据匹配方法研究[D].郑州:信息工程大学, 2011: 31-36. ZHAI Renjian. Research on Automated Matching Methods for Multi-scale Vector Spatial Data Based on Global Consistency Evaluation[D]. Zhengzhou: Information Engineering University, 2011: 31-36. |
| [21] | 钱海忠, 张钊, 翟银凤, 等. 特征识别、Stroke与极化变换结合的道路网选取[J]. 测绘科学技术学报, 2010, 27(5): 371–374, 378. QIAN Haizhong, ZHANG Zhao, ZHAI Yinfeng, et al. Road Selection Method Based on Character Recognition, Stroke and Polarization Transformation[J]. Journal of Geomatics Science and Technology, 2010, 27(5): 371–374, 378. |
| [22] | 钱海忠, 武芳, 朱鲲鹏, 等. 一种基于降维技术的街区综合方法[J]. 测绘学报, 2007, 36(1): 102–107, 118. QIAN Haizhong, WU Fang, ZHU Kunpeng, et al. A Generalization Method of Street Block Based on Dimension-reducing Technique[J]. Acta Geodaetica et Cartographica Sinica, 2007, 36(1): 102–107, 118. |
| [23] | 何海威, 钱海忠, 刘海龙, 等. 道路网层次骨架控制的道路选取方法[J]. 测绘学报, 2015, 44(4): 453–461. HE Haiwei, QIAN Haizhong, LIU Hailong, et al. Road Network Selection Based on Road Hierarchical Structure Control[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(4): 453–461. DOI:10.11947/j.AGCS.2015.20130787 |
| [24] | 杨敏, 艾廷华, 周启. 顾及道路目标Stroke特征保持的路网自动综合方法[J]. 测绘学报, 2013, 42(4): 581–587, 594. YANG Min, AI Tinghua, ZHOU Qi. A Method of Road Network Generalization Considering Stroke Properties of Road Object[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(4): 581–587, 594. |
| [25] | EGENHOFER M J, FRANZOSA R D. Point-set Topological Spatial Relations[J]. International Journal of Geographical Information Systems, 1991, 5(2): 161–174. DOI:10.1080/02693799108927841 |
| [26] | EGENHOFER M J, MARK D M. Naive Geography[M]//FRANK A U, KUHN W. Spatial Information Theory:A Theoretical Basis for GIS. Berlin: Springer, 1995: 1-15. |
| [27] | 刘涛, 杨树文, 李轶鲲, 等. 空间线群目标方向相似度计算模型[J]. 测绘科学, 2013, 38(1): 156–159. LIU Tao, YANG Shuwen, LI Yikun, et al. Direction Similarity Calculation Model of Spatial Line Groups[J]. Science of Surveying and Mapping, 2013, 38(1): 156–159. |
| [28] | 刘涛.空间群(组)目标相似关系及计算模型研究[D].武汉:武汉大学, 2011: 45-57. LIU Tao. Similarity of Spatial Group Objects[D]. Wuhan: Wuhan University, 2011: 45-57. http://cdmd.cnki.com.cn/Article/CDMD-10486-1012267714.htm |