



2. 南京信息工程大学信息与控制学院, 江苏 南京 210044 ;
3. 江苏省大气环境与装备技术协同创新中心, 江苏 南京 210044 ;
4. 南京信息工程大学大气遥感学院, 江苏 南京 210044 ;
5. 南京信息工程大学计算机与软件学院, 江苏 南京 210044
2. School of Information & Control, Nanjing University of Information Science & Technology, Nanjing 210044, China ;
3. ${affiliationVo.addressStrEn} ;
4. Jiangsu Collaborative Innovation Center on Atmospheric Environment and Equipment Technology, Nanjing 210044, China ;
5. School of Atmospheric Physics, Nanjing University of Information Science & Technology, Nanjing 210044, China
积雪是多个地球科学领域的关键影响因素。在气象与气候学领域,积雪是响应全球气候变化的敏感指标,此外,由于积雪对太阳辐射具有极高的反射率,雪盖显著影响了地表辐射的收支平衡,进而通过一系列反馈机制深刻影响全球气候变化与局地天气过程[1]。在水文学领域,积雪形成的融雪径流对于区域水文过程具有重要影响,季节性积雪也是中纬度地区主要淡水来源之一[2-4]。青藏高原拥有北半球中纬度地区海拔最高、范围最广的稳定积雪区域,青藏高原的积雪是亚欧大陆上多条重要河流的源头,因此对青藏高原积雪分布的准确监测,是研究全球气候变化、局地天气过程、水文循环、水资源管理、雪灾预警等重大课题的必要前提[5-7]。
基于卫星遥感技术的积雪监测方法因其时空分辨率高、监测范围广等优势,成为当代积雪监测的主流方法[8-9]。已有的积雪遥感监测方法普遍以归一化差分积雪指数(NDSI)[10]作为积雪判识的主要依据。NDSI依赖于雪盖与无雪地表在可见光与近红外波段的反射率差异,然而部分种类的云与积雪在可见光与近红外波段上的光谱特征非常相似,因此仅凭NDSI无法有效区分云与雪盖,解决这一问题通常需要根据积雪表面与云顶的温度差异,通过红外波段的光谱信息进一步区分云雪[11]。然而在实际应用过程中发现,云顶与积雪表面的温度都易受海拔、地形、气温等因素影响,难以通过人工统计与分析的方式确定温度阈值来区分云雪。这一现象在地形复杂多变、地势起伏剧烈、海拔极高的青藏高原地区尤其明显[12]。青藏高原平均海拔在4km以上,且有大量海拔超过6km的高寒山区,山区地表温度随海拔攀升而快速下降。此外,即使在相同海拔带,不同坡向区域的地表温度也差异巨大。这使得青藏高原的云雪判识问题成为一个与海拔、地形、地表覆盖类型等信息耦合的复杂非线性问题。已有研究表明,目前国际主流的卫星遥感积雪产品在青藏高原地区的积雪误判、漏判率都显著高于其他地区[13]。
深度学习是机器学习领域一个新兴的研究热点,近年来在计算机视觉、语音识别等领域取得了良好成绩。同时,随着卫星遥感数据的多元化和海量化,遥感大数据时代已经到来[14],而深度学习的一大优势在于它能有效应对高维、海量数据进行模式识别与分类,因此深度学习方法可作为处理遥感大数据分析与挖掘问题的有效手段,也正适用于高原山区多光谱遥感积雪判识问题。
文献[15]提出的深度置信网络(deep belief network,DBN)被认为是第一种深度学习架构,随后又出现了多种经典的深度学习架构,这些架构按训练方式的不同大致可分为两类[16]:①有监督深度学习架构,如深度卷积神经网络(convolutional neural networks,CNN)[17],循环神经网络(recurrent neural networks,RNN)[18]等;②无监督或半监督深度学习架构,如前文所述的深度置信网络DBN,基于受限玻尔兹曼机的深度玻尔兹曼机(deep boltzmann machines,DBM)[19],以及层叠去噪自编码器(stacked denoising auto-encoders,SDAE)[20-21]等。有监督深度学习模型通常适用于能提供大量有标签训练样本用于训练的任务,如面向目标检测任务的CNN类网络Fast R-CNN[22],以及面向自然语义理解的RNN类网络LSTM[23]等。而有监督深度学习并不适用于青藏高原地区的遥感积雪判识任务,这是由于该任务所需的样本标签通常来源于地面气象站的每日积雪观测数据,但在地广人稀、地形复杂的青藏高原地区,地面气象站数量稀少、分布稀疏,因此无法供足够多的真实客观且具有空间代表性的标签样本用于有监督训练。而如果使用无监督或半监督深度学习架构,大量遥感数据则可提供足够的无标签训练样本用于无监督预训练,只需要在最后的全局微调阶段使用少量带标签样本进行有监督学习。因此,本文选择无监督或半监督类型的深度学习架构用于青藏高原的遥感积雪判识。进一步而言,受当地基础设施条件的限制,地面气象站提供的样本标签无法保证100%的客观准确,并且卫星遥感数据中也偶尔出现缺测或异常值,因此与DBN和DBM比较,对输入数据中的噪声干扰更具稳健性的SDAE更适合本文任务。
因此,本文选择基于SDAE的深度学习方法对包含多光谱卫星遥感与地理信息的遥感大数据进行特征提取与分类识别,从而达到准确判识青藏高原积雪的目的,主要流程为:构建与训练基于SDAE的深度学习模型,将多光谱卫星遥感与地理信息数据作为输入,通过大量无标签样本对网络进行逐层贪婪预训练,再通过有监督训练对网络进行全局微调,训练完成后的网络即可有效辨识青藏高原遥感图像中的云、积雪以及无雪地表,从而绘制出青藏高原积雪分布图。本文方法的技术流程图如图 1所示。

|
| 图 1 技术流程 Fig. 1 Flow chart of method |
1 研究区域与数据来源 1.1 研究区域概况
青藏高原是全球平均海拔最高的高原,有“世界屋脊”和“世界第三极”之称,平均海拔在4km以上,中南部的喜马拉雅山脉有多个山峰超过8km。青藏高原西起帕米尔高原,东至横断山脉,南至喜马拉雅山脉南缘,北起昆仑山至祁连山北侧,总面积近300万km2。受地形、地貌和大气环流的影响,该区域气候复杂多样,主要为高寒气候:冬季严寒,夏季温暖,全年温差小,日温差大。青藏高原区域降水量变化较大且分布不均,总体上,降水量与气温大致都是自东南向西北递减[24]。
1.2 数据来源 1.2.1 多光谱卫星遥感数据本文采用国家卫星气象中心提供的风云三号A星(FY-3A)所搭载的可见光红外扫描辐射计(VIRR)的多光谱遥感资料FY-3A/VIRR作为主要数据来源。FY-3A/VIRR拥有10个光谱通道,其中第1、7、8、9通道为可见光波段,第2、6、10通道为近红外波段,第3、4、5通道为热红外波段,星下点空间分辨率为1.1km,FY-3A/VIRR各通道光谱信息参考文献[25]。
1.2.2 地理信息数据地理信息数据包括数字高程数据、坡度与坡向数据、地表覆盖类型数据。本文采用GTOPO30(Global 30 Arc-Second Elevation)作为高程数据,青藏高原区域数字高程及地面气象观测站分布如图 2所示。坡度与坡向数据由高程数据计算得到,通过高程、坡向以及坡度数据可以反映该区域的地势特征。地表覆盖类型数据源自国家基础地理信息中心发布的全球30m分辨率地表覆盖遥感制图(GlobalLand30),包括耕地、森林、草地、灌木地、湿地、水体、苔原、人造地表、裸地、冰川和永久积雪共10种地表覆盖类型。

|
| 图 2 青藏高原区域数字高程及地面气象观测站分布 Fig. 2 QT Plateau digital elevation and meteorological stations |
1.2.3 现有遥感积雪产品
本文选择美国国家雪冰数据中心(NSIDC)提供的MODIS逐日积雪产品MOD10A1和MYD10A1数据,以及中国气象局卫星气象中心提供的基于FY-3A卫星多传感器融合的FY-3A/MULSS每日雪盖产品,用于深度学习模型无标签样本的交叉筛选,以及与本文方法结果的对比和验证。所选数据时间范围为2011年1月1日至2013年12月31日。
1.2.4 地面实测雪深数据地面气象站实测雪深数据来源于中国气象数据网(data.cma.cn)提供的每日雪深资料集。本文选取使用了青藏高原范围内106个站点,时段为2011年至2013年。每日雪深大于2cm则认为当天该气象站所在位置有积雪,否则为无雪,以此作为本文的标签样本与对比验证的客观参考标准。
2 研究方法 2.1 多光谱遥感数据预处理FY-3A/VIRR数据预处理主要分为可见光与近红外通道数据定标、热红外通道数据定标、太阳天顶角订正、几何校正、图像拼接和裁剪。预处理流程如图 3所示。

|
| 图 3 遥感数据预处理流程 Fig. 3 Multispectral remote sensing data pre-processing |
可见光与近红外通道数据定标是指将原始光谱数据转化为反射率数据。热红外通道数据定标包括星上线性定标、辐亮度非线性订正、等效黑体亮温计算,用于将原始光谱数据转化为亮度温度值。对于极轨卫星而言,其拍摄的卫星图像中各像元不同的空间位置导致各像元所处位置的太阳高度角也各不相同,因此需要通过太阳高度角订正,将不同空间位置的反射率修正为在统一太阳直射角度下的反射率值。几何校正采用地理位置查找表法(geographic lookup table,GLT)进行投影变换,利用FY-3A/VIRR数据自带的经纬度数据生成地理位置查找表,然后根据该表将原图像数据投影转换为0.01°等经纬度图像。最终通过图像拼接与裁剪,得到青藏高原区域的多光谱遥感数据。
2.2 多光谱遥感与地理信息融合的积雪判识方法多光谱卫星遥感资料的数据规模巨大,不同波段的光谱信息与多种地理信息要素之间有着复杂的非线性关系,因此本文构建与训练一个基于SDAE的深度学习网络模型对多光谱遥感数据与地理信息数据进行特征表达与分类。
2.2.1 层叠去噪自动编码网络原理层叠自动编码器是当今主流深度学习架构之一。自动编码器(auto-encoder,AE)是该架构的基本组成单元。本质上,AE是一种单隐层神经网络,但是AE的输出层并不用于输出分类或拟合结果,而是要求输出尽可能与输入相同。AE网络的迭代训练过程如图 4所示,输入信号由编码器转化为特征编码,再通过解码器转化为重构信号,然后计算重构信号与输入信号的误差,并将误差逆传播,通过调节AE网络各神经元间连接的权值使误差下降。通过控制隐藏层神经元数量,或对隐藏层的编码加入限制条件,可以使AE学习到对输入数据的特殊表达方式:如果隐藏层的单元数量小于输入层,则AE能实现对输入数据的降维表达;如果隐藏层单元数量大于输入层,并加入稀疏性限制,那么AE能实现对输入数据的稀疏表达。值得一提的是,这一训练过程是无监督的,并不需要预先知道训练样本的分类标签,而这对于缺乏足够多的地面观测记录来制作含标签训练样本的青藏高原区域,无监督训练的优势显得尤为重要。

|
| 图 4 自动编码器学习过程 Fig. 4 Training process of AE |
设AE网络用于训练的样本数据集为{x(1),x(2),…,x(K)},该样本集由K个n维向量x∈[0,1]n×1构成,输入向量x由输入层传播至隐藏层,转化为m维特征向量h∈Rm×1,该过程被称为编码,如下所示
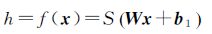 (1)
(1)
特征向量由隐藏层传播到输出层,得到n维输出数据(也就是重构数据)${\hat{x}}$∈[0,1]n×1,该过程被称为解码,如下所示
 (2)
(2)
式(1)和式(2)中,W∈Rm×n 为输入层与隐藏层间所有连接的权值矩阵;W
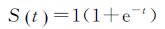 (3)
(3)
式中,e为自然常数。
AE通过寻找一组最优参数矩阵θ*={W*,b1*,b2*}来使损失函数L(W,b1,b2)最小化,如式(4)所示
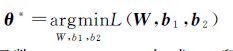 (4)
(4)
式中,损失函数L(W,b1,b2)如式(5)所示
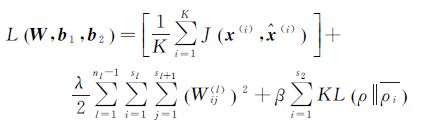 (5)
(5)
式中,等号右侧第1项为一次训练过程中所有训练样本的输入与输出的误差总和;x(i)与$\hat{x}$(i)分别表示第i个样本的输入向量与重构向量,J(x(i),$\hat{x}$(i))表示x(i)与$\hat{x}$(i)间的均方差,如式(6)所示
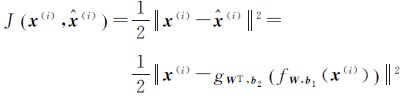 (6)
(6)
式(5)等号右侧第2项为正则化约束项,用于防止训练过拟合,其中λ为权重系数,nl为网络的层数(AE网络中nl=3),sl为第l层的神经元数量,由于AE是3层网络结构,因此l={1,2,3}。Wij(l)表示第l层第i个单元与l+1层第j个单元间的连接权重值,由于AE中隐藏层与输出层间的权值矩阵,是输入层与隐藏层间权值矩阵的转置,因此Wij=Wij(1)=Wji(2)。
式(5)等号右侧第3项为稀疏性约束项,其中β为该项权重,b1,i为隐藏层偏置b1的第i项,第s2为AE网络的第2层,也就是隐藏层的神经元数量,ρ是由经验值设定的期望激活率,一般为较小值。其中KL$\left( \rho \left\| {{{\bar{\rho }}}_{i}} \right. \right)$表示AE隐藏层第i个单元的平均激活率与期望激活率之间的KL散度,如式(7)所示
 (7)
(7)
式中,ρi为隐藏层第i个神经元的平均激活率,由式(8)求得
 (8)
(8)
该稀疏性约束项的目标是让平均激活率ρi尽可能接近期望激活率ρ,一般ρ取较小值,即表明该项的存在是为了使隐藏层被激活的神经元尽可能的少,以使隐藏层获得对输入信号稀疏表达的能力。
AE网络将损失函数L(W,b1,b2)最小化的训练过程,是通过误差逆传播与梯度下降法实现的,AE网络的迭代寻优过程如下。
步骤1:随机初始化所有网络参数W、b1、b2。
步骤2:计算前向传播过程中所有神经元的输入与输出值,计算方法如式(9)与式(10)所示
 (9)
(9)
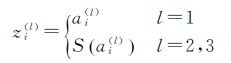 (10)
(10)
式(9)与式(10)分别表示AE各层各单元的输入值与输出值,其中xi(n)表示训练样本向量x(n)的第i个分量;ai(l)、zi(l)分别表示AE网络第l层第i个单元的输入值与输出值,bl,j表示第l层与第l+1层间偏置向量bl的第j个分量。
步骤3:计算当前网络状态下的损失函数L(W,b1,b2),判断损失函数是否达到期望的最小值,如果是,则完成AE网络训练,当前W,b1,b2即为训练所得最优参数;如果不是,则继续下一步。
步骤4:计算网络输出层所有单元的输出残差δk(3),以及隐藏层各神经元的残差δk(2),如式(11)、式(12)所示
 (11)
(11)
 (12)
(12)
在所得残差基础上,使用梯度下降法将残差逆传播,更新网络参数W、b1、b2,如式(13)所示
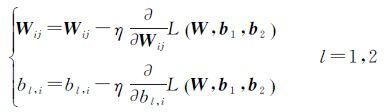 (13)
(13)
式中,η为更新步长;$\frac{\partial }{\partial {{W}_{ij}}}L\left( W,{{b}_{1}},{{b}_{2}} \right)$、$\frac{\partial }{\partial {{b}_{l,i}}}L\left( W,{{b}_{1}},{{b}_{2}} \right)$可通过式(14)计算得到
 (14)
(14)
式中,
 (15)
(15)
步骤5:完成本次迭代,返回执行步骤2。
多个自动编码器层叠级联就构成层叠自编码网络(SAE),以上一级AE隐藏层所输出的特征向量作为下一级AE隐藏层的输入,并只有当上一层训练达到要求的情况下才开始对下一层进行训练,以这种被称为“贪婪逐层训练”的方式对整个SAE网络进行训练,SAE的网络结构如图 5所示。

|
| 图 5 层叠去噪自动编码模型逐层训练过程 Fig. 5 Pre-training process of SDAE |
层叠去噪自编码网络(SDAE)是对SAE的有效改进,为使SAE学习到的特征表达更具稳健性,SDAE会以一定的概率分布,随机的在训练样本中加入噪声(随机将各隐藏层单元的输入置零)。由于AE的训练机制要求输出数据尽量近似被噪声污染前的输入数据,这迫使SDAE自主学习如何去除输入数据中的噪声干扰。最终,SDAE将学会对输入数据噪声干扰更稳健的特征表达,从而增强SDAE处理实际问题的泛化能力。
2.2.2 训练样本制备 2.2.2.1 无监督训练样本制备预处理后的多光谱遥感数据以多层图像叠加的形式保存,各种地理信息数据也是以二维矩阵的形式存在,因此需要将原始数据转化为SDAE输入数据所需的数据结构,本文训练样本数据集预处理过程如图 6所示。

|
| 图 6 训练样本数据集制备过程 Fig. 6 The preparation process of training samples |
具体过程为:首先将多光谱遥感数据与多种地理信息数据在地理空间上配准一致,并重采样为相同的空间分辨率,设重采样后的青藏高原地区遥感图像与地理信息数据的尺寸都为m×n,所有通道的光谱图像共计l1=10层,地理信息数据为l2=4层,将所有数据叠在一起,形成一个m行n列,共l=l1+l2=14层的三维矩阵。以该三维矩阵的第i行第j列的所有l层数据作为一个输入数据样本,其中i={1,2,…,m},j=1,2,…,n。总共得到k=m×n个样本,由于SDAE网络只能处理[0,1]数值范围区间内的样本,因此还需要将样本数据归一化至0,1区间内,最终得到所需的样本数据集。
2.2.2.2 有监督训练样本筛选与制备对于积雪判识问题,若在地面气象站分布密集的地区,通常将地面雪深观测记录作为样本标签,然而青藏高原区域的地面气象站分布密度极低,且分布不均,青藏高原西北部甚至有数万平方千米的高寒无人区至今没有气象观测记录。因此,在地面雪深观测记录提供的含标签训练样本数量不足的情况下,本文采用多种卫星遥感积雪产品(MOD10A1、MYD10A1以及FY-3A/MULSS)交叉验证的方法来筛选样本,以增加含标签样本数量。
首先对3种积雪产品作一致性检验,如果同一日的积雪产品在同一像元位置处的判识结果一致,则该像元处的样本及判识结果即被筛选出作为候选含标签样本。已有研究表明,MOD10A1与MYD10A1在青藏高原区域的年平均分类准确率都可达90%以上,FY-3A/MULSS积雪产品的年平均分类准确率也可达80%以上,因此3种积雪产品在同一位置作出相同的错误判断的概率相当低。必须指出的是,该筛选方法并不能保证所有样本标签是百分之百客观正确的,然而SDAE网络本身对少量标签污染具有一定稳健性,并且SDAE隐藏层的稀疏表达机制也有助于降低错误样本标签的干扰。因此在训练样本足够多的情况下,少数的错误标签样本对积雪判识网络的性能固然会造成一定负面影响,但与本文方法对积雪判识准确性的整体提升相比,该负面影响完全在可承受范围内。
2.2.3 SADE网络构建与预训练针对不同的任务目标,SDAE网络的结构也各有不同。为使SDAE网络学习到多光谱遥感数据与地理信息间的复杂非线性关系,本文设计的SDAE网络采用三隐藏层结构,并使第1隐藏层的单元数量大幅高于输入数据维数,然后逐层减少单元数量。输入数据通过第1隐藏层被投影到更高维的空间,然后通过后续隐藏层达到特征提取与降维的目的。本文方法中,输入数据维数为linput=14,其中含FY-3A/VIRR数据共10个波段的光谱数据,以及由海拔、坡度、坡向、地表覆盖类型组成的4个地理信息要素。SDAE网络第1隐藏层单元数量为l1=80,第2隐藏层l2=10,第3隐藏层l3=3。即14维的输入向量先升维并稀疏编码为80维的特征向量,然后降维表达为10维,最终输出3维的特征向量。
深度学习网络的参数设置是由具体的网络结构、应用需求,以及硬件计算资源等因素综合决定的。本文针对实际应用目标进行大量的调参试验,尽量在两对互相对立的训练目标中取得平衡:①既要尽量提高对硬件计算资源的利用率,又要确保计算规模不超过硬件负担极限,以至训练进程崩溃;②既要尽量提高训练结果的准确率,又要避免训练的耗时过长。由于训练样本的数据量极大,计算资源有限,每次调参试验短则数小时,长则数天,且各参数之间互相影响,因此在有限时间内将所有参数调至最优并不现实,只需把握到大致合适的参数取值范围,即可达到期望的训练效果。
最终确定本文SDAE网络的主要参数为:学习率为0.5,正则化约束项权值系数为0.0003,稀疏性惩罚项的期望激活率为0.05,隐含层丢失率为0.1,输入数据加噪率为0.05。其中,学习率越大,单次迭代的训练耗时越短,但学习率过大则会引发代价函数振荡,导致误差无法收敛;反之,学习率过小则会使训练误差收敛过慢,使网络陷入局部最优难以自拔。通过多次尝试发现,本文应用目标下的学习率大于2或小于0.1都会导致训练误差难以收敛,取0.5则能既兼顾效率又保证误差收敛(合理范围内的其他值亦可训练成功,只是训练准确率与训练耗时会发生微小变动)。其他参数使用类似方式得到,约束项权值系数与稀疏性惩罚项期望激活率主要用于防止训练过拟合,然而在具备海量训练样本用于预训练的情况下不易出现过拟合,因此只需取很小的值。而隐含层丢失率与输入数据加噪率主要用于增强网络对输入数据噪声干扰的稳健性,从而提高网络的泛化能力,设置过大同样会导致训练误差无法收敛,本文试验中发现该组参数分别设置为0.1与0.05已接近极限值,超过该值易导致训练失败,但是基于网络抗干扰能力越强越好的原则,本文取上述极限值。通过以上参数设置建立网络后,即可采用逐层贪婪训练的方式对整个网络进行预训练,从而使网络能对多光谱遥感数据与地理信息数据进行有效的特征表达,使提取到的特征更易于后续的分类识别。
2.2.4 有监督全局微调经无监督预训练后的SDAE网络已具备良好的表达多光谱信息与地理信息间非线性关系的能力,这可有效避免传统BP神经网络因随机初始化而易陷入局部最优的缺陷,再通过有标签训练样本对网络进行有监督全局微调与分类训练,就可将每个输入样本分为云、雪以及无雪地表3种类别。最终的分类网络结构如图 7所示。

|
| 图 7 SDAE积雪判识网络模型 Fig. 7 The architecture of SDAE network for snow recognition |
本文采用Sotfmax分类器对特征向量进行分类识别,假设输入数据x,对应标签为y,针对每一个类别j估算的每一种分类结果出现的概率为p(y=j|x),这需要一个假设函数把输入数据转化为一个k维向量,来估计k个类别的概率值,并且向量元素和为1。假设函数hθ(x)的具体形式可由式(17)得到
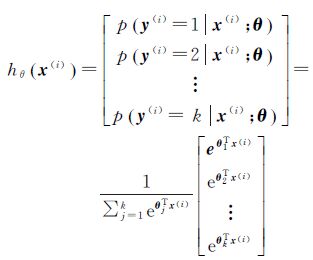 (17)
(17)
式中,θ1、θ2、…、θk∈Rn+1是模型的参数;Softmax分类器的代价函数J(θ)可由式(18)得到
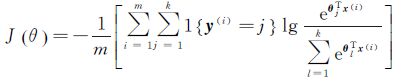 (18)
(18)
式中,1{·}是一个指示性函数,即当大括号中的值为真时,该函数的结果就为1,否则其结果就为0。对于代价函数J(θ)使用梯度下降法迭代求最小,通过该迭代训练过程,该网络能有效地将输入数据进行分类,通过将输出结果重排列与可视化即可得到青藏高原积雪分布图。
3 试验结果与分析为验证本文方法的可靠性,设计试验将2011年与2012年青藏高原地区FY-3A/VIRR数据以及相关地理信息数据用于SDAE网络训练,提取出2000万个无标签训练样本用于无监督训练,并以青藏高原106个气象站在这两年间记录的5万多个每日积雪观测数据(已剔除占总量近20%的缺测、无效填充值以及低置信度观测记录)。为了增加网络的泛化能力,通过3.2.4 节所述的方法从已有积雪产品中提取更多含标签样本,最终将有标签训练样本扩充至100万个。用于深度学习网络训练的硬件设备为:Intel Xeon E5-2650 v2 CPU,双CPU,每个CPU含8核心,共16个计算核心;内存32GB;显卡为Nvidia GTX970,4GB显存。本次试验所用训练样本总数达千万级,无监督训练的迭代次数达400次,有监督全局微调的训练次数达200次,总训练耗时长达26h 45min。虽然训练耗时较长,但训练完毕的分类网络处理青藏高原一天的遥感数据(经预处理后)只需不到2s即可得到分类结果。
以2013年青藏高原地区FY-3A/VIRR数据与地理信息数据作为测试集,通过本文方法制得该年积雪产品,命名为FY-3A/DL。最终FY-3A/DL与MOD10A1、MYD10A1、FY-3A/MULSS由地面气象站实测雪深数据验证,得到各自的分类精度以及各分类目标覆盖率。在验证过程中,由于无法得知在积雪产品识别为云的区域,其云层之下是否有雪,因此在普遍采用地面站验证方法中,通常不用云覆盖下地面站数据验证精度;而如果某天整个青藏高原区域云量过多,即超过60%的地面气象站被云遮蔽,则其余无云站点的验证结果不具足够的空间代表性,因此当天的精度数据不纳入统计。此外,通过分析青藏高原地区的地面气象资料可知,当地夏季(6~8月)极少观测到降雪,即使部分高寒山区在夏可能发生短时降雪,但发生概率很低,且因气温较高而难形成过夜的积雪,这段时期下文称为非积雪季;当地降雪主要发生在每年1~5月、9~12月,下文称为积雪季。
图 8给出2013年在青藏高原地区本文方法与多种积雪产品经地面站数据验证后得到的周平均分类精度曲线对比。可见所有积雪产品的分类精度都呈现非积雪季较高,而在积雪季较低的形态,进一步分析发现由于青藏高原在非积雪季很少出现大范围、长时间的降雪过程,青藏高原在非积雪季依然存在的积雪为高海拔山区的常年积雪,雪盖范围相对稳定,因此在这段时期传统方法能很好处理,深度学习方法并没有明显优势。2013年4种积雪产品的年均精度符合图 8的周平均精度走势对比:本文方法年平均精度最高,达93.96%,略高于MOD10A1的93.55%与MYD10A1的93.83%,显著高于使用相同卫星数据源的FY-3A/MULSS(90.51%),证明本文方法能够将国产风云卫星数据发挥出超过美国MODIS卫星数据的积雪检测水平。

|
| 图 8 青藏高原地区2013年本文方法与多种雪产品周平均分类精度对比 Fig. 8 Weekly average accuracy curves of various snow cover products over the QT Plateau in 2013 |
值得注意的是,从图 8直观上看,本文方法在积雪季的分类精度与MOD10A1、MYD10A1相近,而在非积雪季则低于MOD10A1,然而年均精度却显示MOD10A1在是三者中最低的,这是因为在精度验证规则中,高云量天数的精度并不纳入周平均与年平均精度统计,而在每年云量持续较高的6—8月,周平均精度只统计各周云量较少的少数几天数据,而年均精度则统计全年所有符合统计标准的天数,这导致非积雪季对年平均精度的贡献明显小于积雪季,因此虽然在非积雪季MOD10A1的周平均精度高于其他产品,其年均精度却略低于MYD10A1与本文方法。
本文方法与多种积雪产品的实际效果对比如图 9所示。图 9(a)为2013年2月9日青藏高原区域的卫星遥感彩色合成图像,可见当天青藏高原地区云量较高,遥感积雪产品易出现大量云雪误判。图 9(b)、图 9(c)、图 9(d)、图 9(e)分别为MOD10A1、MYD10A1、FY-3A/MULSS以及本文方法的积雪产品效果,经地面观测数据验证,本文方法当天的误判率最低(16.39%),大幅低于FY-3A/MULSS(29.85%),低于MYD10A1(21.62%)以及MOD10A1(18.18%)。此外,经大量人工检验后发现遥感积雪产品与人眼直接观察感受到的云量相比普遍偏高,但研究过程中发现,事实上云量的高低并不影响积雪分类精度统计,主要因为在普遍施行的积雪产品精度统计方法中,被云遮蔽的气象站不参与验证。这带来一个现实问题:常规方法在晴空无云条件下的积雪判识精度极高,而在云雪难分的区域,只要都判断为云,则无论这个判断是否正确,都不会影响当天的积雪分类精度。因此在统计意义上,如果要获得较高的分类精度,只需将所有云雪难辨的像元都判为云即可,但这样就失去了科学意义。因此,为了评价分类精度相当的两种积雪产品哪种积雪检出率更高,本文在将分类精度作为首要指标的前提下,将云覆盖率与积雪覆盖率作为考察实际分类效果的次级指标:仅当两种积雪产品在分类精度非常接近的情况下,云量较少的那种积雪产品才被认为比较接近真实情况;如果两种积雪产品分类精度差距较大,则云覆盖率失去比较意义。图 9的实际分类效果的对比显示,本文方法分类精度最高,且云覆盖率35.56%也是所有积雪产品中最低,进一步比较可知,当天的MOD10A1与MYD10A1产品误判率较低,但是云覆盖率过高;FY-3A/MULSS产品当天的误判率成为所有方法中最高,其云覆盖率虽低也毫无意义。

|
| 图 9 青藏高原2013年2月9日多种积雪产品效果对比 Fig. 9 Snow cover images over the QT Plateau on February 9,2013 |
图 10为2013年青藏高原地区本文方法与其他积雪产品各种类别的周平均覆盖率曲线对比。图 10(a)为云的周平均覆盖率曲线对比,可见本文方法的云覆盖率最低,MOD10A1最高。图 10(b)为无雪地物的周平均覆盖率曲线对比,本文方法与FY-3A/MULSS非常接近,MOD10A1最低。图 10(c)为积雪覆盖率的周平均覆盖率曲线对比,本文方法的积雪覆盖率最高,略高于FY-3A/MULSS,MOD10A1最低。

|
| 图 10 青藏高原地区2013年本文方法与多种雪产品周平均覆盖率对比 Fig. 10 Weekly mean coverage rate comparison between various snow products over the QT Plateau in 2013 |
表 1给出本文方法与MYD10A1、MOD10A1、FY-3A/MULSS的年均分类精度以及各分类目标的年均覆盖率对比。可见本文方法分类精度大幅优于使用相同卫星遥感数据的FY-3A/MULSS,并略高于MYD10A1与MOD10A1。此外,本文方法的年均云覆盖率最低,FY-3A/MULSS产品云覆盖率虽比MYD10A1低13.71%,然而FY-3A/MULSS的分类正确率最低,这意味着FY-3A/MULSS虽然去除了大量的云,但也因此将大量云像元误判为积雪。本文方法的年均云覆盖率为35.01%,在所有积雪产品中最低,可见本文方法在确保分类精度不下降的前提下,尽可能降低了云的覆盖率。
| 积雪产品 | 年均精度评价 | 年均覆盖率 | |||||
| 分类正确率 | 漏测误差 | 多测误差 | 云 | 积雪 | 无雪地物 | ||
| MYD10A1 | 93.83 | 5.59 | 0.58 | 51.98 | 3.84 | 44.17 | |
| MOD10A1 | 93.55 | 5.93 | 0.52 | 43.16 | 5.05 | 51.79 | |
| FY3A/MULSS | 90.51 | 6.48 | 3.01 | 38.27 | 7.74 | 53.99 | |
| 本文方法 | 93.96 | 5.06 | 0.98 | 35.01 | 8.47 | 56.51 | |
4 结 论
通过构建与训练一个SDAE深度学习网络实现对青藏高原地区的多光谱遥感图像与多要素地理信息的融合与特征提取,并用于自动分类识别,最终绘制出青藏高原积雪分布图,与传统的基于NDSI的遥感反演方法相比,该方法能更好地适应目标区域复杂的地形与地理特点。试验验证表明,该方法所得积雪产品在分类精度上相比使用相同卫星数据源的FY3A/MULSS积雪产品有大幅提升,并略微超过国际主流的积雪产品MOD10A1与MYD10A1;在去云效果上,本文方法的云覆盖率最低,积雪覆盖率最高。以上结果足以证明该方法的有效性与优越性。然而,本文方法也有不少可改进之处:①通过精度对比发现本文方法在夏季效果不如传统方法,下一步将根据青藏高原气候特征,训练季节性的积雪判识深度网络,这些季节性深度网络将更好表达积雪与云层在不同季节下的光谱特征差异,组合使用这些季节性网络可进一步提高积雪产品整体的分类精度;②本文方法目前仅针对青藏高原地区,因此地区适用性不足,下一步将实现把本文方法扩展应用到其他区域,使深度网络能学习各种不同地形特征下的积雪信息;③仅使用FY-3A/VIRR作为唯一的卫星遥感多光谱数据,数据支撑不足,目前已开展基于MODIS多光谱遥感数据的深度学习积雪检测的研究,其分类结果与MODIS积雪产品的精度相对比,能更好地论证深度学习方法对于解决遥感大数据问题的有效性和适用性。
| [1] | YANG Kun, WU Hui, QIN Jun, et al. Recent Climate Changes over the Tibetan Plateau and Their Impacts on Energy and Water Cycle:A Review[J]. Global and Planetary Change , 2014, 112 : 79 –91. DOI:10.1016/j.gloplacha.2013.12.001 |
| [2] | DIETZ A J, KUENZER C, GESSNER U, et al. Remote Sensing of Snow-A Review of Available Methods[J]. International Journal of Remote Sensing , 2012, 33 (13) : 4094 –4134. DOI:10.1080/01431161.2011.640964 |
| [3] | KLEIN A G, HALL D K, NOLIN A W. Development of A Prototype Snow Albedo Algorithm for the NASA MODIS Instrument[C]//Proceedings of the 57th Eastern Snow Conference. Syracuse, New York:[s.n.], 2000:15-17. |
| [4] | JAIN S K, GOSWAMI A, SARAF A K. Accuracy Assessment of MODIS, NOAA and IRS Data in Snow Cover Mapping under Himalayan Conditions[J]. International Journal of Remote Sensing , 2008, 29 (20) : 5863 –5878. DOI:10.1080/01431160801908129 |
| [5] | ZHOU Xiuji, ZHAO Ping, CHEN Junming, et al. Impacts of Thermodynamic Processes over the Tibetan Plateau on the Northern Hemispheric Climate[J]. Science in China Series D:Earth Sciences , 2009, 52 (11) : 1679 –1693. DOI:10.1007/s11430-009-0194-9 |
| [6] | HUANG Jie, KANGS Shichang, ZHANG Qiangong, et al. Spatial Distribution and Magnification Processes of Mercury in Snow from High-Elevation Glaciers in the Tibetan Plateau[J]. Atmospheric Environment , 2012, 46 : 140 –146. DOI:10.1016/j.atmosenv.2011.10.008 |
| [7] | 王叶堂, 何勇, 侯书贵. 2000-2005年青藏高原积雪时空变化分析[J]. 冰川冻土 , 2007, 29 (6) : 855–861. WANG Yetang, HE Yong, HOU Shugui. Analysis of the Temporal and Spatial Variations of Snow Cover over the Tibetan Plateau Based on MODIS[J]. Journal of Glaciology and Geocryology , 2007, 29 (6) : 855 –861. |
| [8] | 都伟冰, 李均力, 包安明, 等. 高山冰川多时相多角度遥感信息提取方法[J]. 测绘学报 , 2015, 44 (1) : 59–66. DU Weibing, LI Junli, BAO Anming, et al. Information Extraction Method of Alpine Glaciers with Multitemporal and Multiangle Remote Sensing[J]. Acta Geodaetica et Cartographica Sinica , 2015, 44 (1) : 59 –66. DOI:10.11947/j.AGCS.2015.20130514 |
| [9] | 李震, 施建成. 高光谱遥感积雪制图算法及验证[J]. 测绘学报 , 2001, 30 (1) : 67–73. LI Zhen, SHI Jiancheng. Snow Mapping Algorithm Development and Validation Using Hyperspectral Data[J]. Acta Geodaetica et Cartographica Sinica , 2001, 30 (1) : 67 –73. DOI:10.3321/j.issn:1001-1595.2001.01.013 |
| [10] | HALL D K, RIGGS G A, SALOMONSON V V, et al. MODIS Snow-Cover Products[J]. Remote Sensing of Environment , 2002, 83 (1-2) : 181 –194. DOI:10.1016/S0034-4257(02)00095-0 |
| [11] | RIGGS G A, HALL D K. Reduction of Cloud Obscuration in the MODIS Snow Data Product[C]//Proceedings of the 60th Eastern Snow Conference. Sherbrooke, Québec:[s.n.], 2003:205-212. |
| [12] | YANG Juntao, JIANG Lingmei, MÉNARD C B, et al. Evaluation of Snow Products over the Tibetan Plateau[J]. Hydrological Processes , 2015, 29 (15) : 3247 –3260. DOI:10.1002/hyp.v29.15 |
| [13] | 刘洵, 金鑫, 柯长青. 中国稳定积雪区IMS雪冰产品精度评价[J]. 冰川冻土 , 2014, 36 (3) : 500–507. LIU Xun, JIN Xin, KE Changqing. Accuracy Evaluation of the IMS Snow and Ice Products in Stable Snow Covers Regions in China[J]. Journal of Glaciology and Geocryology , 2014, 36 (3) : 500 –507. |
| [14] | 李德仁, 张良培, 夏桂松. 遥感大数据自动分析与数据挖掘[J]. 测绘学报 , 2014, 43 (12) : 1211–1216. LI Deren, ZHANG Liangpei, XIA Guisong. Automatic Analysis and Mining of Remote Sensing Big Data[J]. Acta Geodaetica et Cartographica Sinica , 2014, 43 (12) : 1211 –1216. DOI:10.13485/j.cnki.11-2089.2014.0187 |
| [15] | HINTON G, OSINDERO S, TEH Y W. A Fast Learning Algorithm for Deep Belief Nets[J]. Neural Computation , 2006, 18 (7) : 1527 –1554. DOI:10.1162/neco.2006.18.7.1527 |
| [16] | 郭丽丽, 丁世飞. 深度学习研究进展[J]. 计算机科学 , 2015, 42 (5) : 28–33. GUO Lili, DING Shifei. Research Progress on Deep Learning[J]. Computer Science , 2015, 42 (5) : 28 –33. |
| [17] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]//Advances in Neural Information Processing Systems. Red Hook, NY:Curran Associates, 2012:1097-1105. |
| [18] | MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent Neural Network Based Language Model[C]//Proceedings of INTERSPEECH. Lyon, France:ISCA, 2010:1045-1048. |
| [19] | SALAKHUTDINOV R, HINTON G E. Deep Boltzmann Machines[J]. Journal of Machine Learning Research , 2009, 5 (2) : 448 –455. |
| [20] | VINCENT P, LAROCHELLE H, BENGIO Y, et al. Extracting and Composing Robust Features with Denoising Autoencoders[C]//Proceedings of the 25th International Conference on Machine Learning. New York:ACM Press, 2008:1096-1103. |
| [21] | VINCENT P, LAROCHELLE H, LAJOIE I, et al. Stacked Denoising Autoencoders:Learning Useful Representations in a Deep Network with a Local Denoising Criterion[J]. Journal of Machine Learning Research , 2010, 11 : 3371 –3408. |
| [22] | GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile:IEEE, 2015:1440-1448. |
| [23] | SUTSKEVER I, VINYALS O, LE Q V. Sequence to Sequence Learning with Neural Networks[C]//Advances in Neural Information Processing Systems. 2014, 4:3104-3112. |
| [24] | 秦小静, 孙建, 陈涛. 青藏高原温度与降水的时空变化研究[J]. 成都大学学报(自然科学版) , 2015, 34 (2) : 191–195. QIN Xiaojing, SUN Jian, CHEN Tao. Study on Spatiotemporal Variation of Temperature and Precipitation in Qinghai-Tibetan Plateau from 1974 to 2013[J]. Journal of Chengdu University (Natural Science Edition) , 2015, 34 (2) : 191 –195. |
| [25] | 杨军, 董超华, 卢乃锰, 等. 中国新一代极轨气象卫星——风云三号[J]. 气象学报 , 2009, 67 (4) : 501–509. YANG Jun, DONG Chaohua, LU Neimeng, et al. FY-3A:the New Generation Polar-Orbiting Meteorological Satellite of China[J]. Acta Meteorologica Sinica , 2009, 67 (4) : 501 –509. |