



1 引 言
高光谱遥感是20世纪后期遥感技术领域内一项重大发展,它以众多窄且连续的光谱通道,获取大量具有完整光谱信息的感兴趣地物图像数据,为地物识别提供了方便[1, 2]。传统的高光谱影像分类方法主要有以支持向量机[3, 4]为代表的监督分类方法以及以模糊聚类法[5]为代表的非监督分类方法。对于监督分类方法,若要得到效果较好的分类模型,需要对大量的标记样本进行训练,但是对高光谱遥感图像获取类别标记数据,是一项耗时耗力、成本高昂的工作[6];对于非监督分类方法,无须使用标记样本,但缺乏先验知识,无法保证聚类后类别与地物类别之间的正确对应。
在这种情况下,基于半监督学习的高光谱影像分类方法引起了研究者的广泛关注[7, 8, 9]。它的基本思想是基于数据分布的某种假设,综合利用标记与未标记数据建立高性能学习器,一定程度上弥补了监督学习与非监督学习的不足。常用的半监督分类算法有生成式模型算法[10]、直推式支持向量机方法[11]、自训练方法[12]和基于图的方法[13, 14]。文献[10]将光谱分解概念用于多项式逻辑回归半监督分类器中,提出新的遥感数据解译方法,成功运用于高光谱影像分类;文献[11]将一种与时间相关的加权策略引进直推式支持向量机算法,减小次最优模型带来的影响,使病态高光谱影像分类问题得到有效解决;文献[13]提出基于图的半监督高光谱影像分类方法,首先构造一个由标记数据和未标记数据作为顶点、以数据间相似性作为边的图,依据权值大的相连数据具有较高的相似性而分类,在高光谱影像分类问题中得到了有效运用。虽然半监督学习已被成功应用于高光谱影像分类,但它仍然存在两点不足:①现有基于半监督学习的高光谱影像分类方法大多只利用了影像的光谱信息,而较少关注影像中地物目标的空间结构特征;②它们所用的标记数据是随机选取的,如若选取不当,将会得到与数据集不相匹配的假设而导致学习性能下降。
针对以上问题,本文提出主动学习与图的半监督相结合的高光谱影像分类方法,方法流程如图 1所示,其主要思想是:首先将像素光谱信息与其邻域内像素特征相结合,提出一种旋转不变的空-谱特征提取算法,以弥补单独利用谱域信息进行半监督学习的不足;然后依据best-versus-second best(BvSB)[15]排序准则设计主动学习算法用于选取分类模糊度较大样本进行人工标记,以保证初始训练模型的精度;最后采用图的半监督模型实现标记与未标记样本的结合,在较少标记样本可用情况下,保证未标记样本的充分利用,以改善分类效果。试验结果表明,本文方法可以得到高效、稳定的高光谱影像分类结果。

|
| 图 1 本文分类方法流程图 Fig. 1 Flowchart of the proposed classification scheme |
由于高光谱影像维数高、波段间相关性强,易导致数据出现冗余、维数灾难等问题,首先利用PCA[16](principal component analysis)对影像进行特征降维,然后提出一种旋转不变特性的空-谱特征提取方法,将影像的空域和谱域特征结合起来,以弥补单独利用谱域信息进行后续半监督学习的不足。
假定降维之后的高光谱影像I包含d个波段,则I中任意像素x0的旋转不变空-谱特征可表示为
式中,f0为像素x0的光谱向量;f1、f2、…、fn×n-1为像素x0的n×n邻域内各个像素的光谱向量;函数sort()用于将这n×n-1个像素的光谱向量按照它们的第一个元素从小到大的顺序进行重组。尽管这种排序方法忽略了x0邻域内像素的位置信息,但它仍然保留了原有像素的灰度分布信息(类似直方图表达),显然无论局部影像怎样旋转,与其对应的特征Z是不变的。接着,将矩阵X的各行按先后顺序堆叠,从而将其转换成一个1维的行向量F0,形成对像素x0的空-谱特征表达。此外,本文对空-谱特征值进行了“零均值单位方差”归一化处理。3×3大小的影像块中空-谱特征的提取过程如图 2所示。
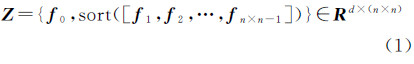

|
| 图 2 空-谱特征提取图 Fig. 2 Extraction of spatio-spectral features |
传统分类方法中标记样本都是随机选取,如若选取不当,可能得到与数据集不相匹配的假设而导致学习性能下降,故本文提出采用主动学习[17, 18]思想来构造标记样本集,即根据当前小标记样本集去训练模型,预测所有未标记样本,并按照BvSB准则将其排序,从中选择出分类最具模糊性样本,并将以该样本像元为中心的影像块返回给用户,用户依据影像块内容给予目标像素正确的类别标记,再将样本及其标注置入训练集重新训练新的分类器,整个过程循环多次,直至分类器的某种指标达到预设值或循环次数达到预设值[19]。如此构造的标记样本集,比随机选取样本更能准确表达数据的分布情况,更有利于分类器的边界构造,因此能够达到更好的分类效果。
BvSB是一种样本不确定性衡量准则,它以样本后验类别概率中两个最大可能类别的概率值之差作为样本不确定性的评价指标,两个最大可能类别概率的差值越小,则分类器的置信度越低。BvSB准则降低了较大无关类别概率值的影响、与类别数目无关,且更直接地评估类间关系混合性。基于BvSB的训练样本集构造具体过程如下。
(1) 初始每类随机选取t个样本并人工给予标记,记为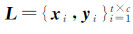 ,其余未标记样本记为
,其余未标记样本记为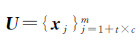 ,c为类别数目,m为影像I中所有像素的数目。
,c为类别数目,m为影像I中所有像素的数目。
(2) 对当前训练样本集L进行训练,得到SVM模型。
(3) 计算U中每一个样本xj分为各类的可能后验概率p=[pj,1,pj,2,…,pj,c],并计算xj的最大、次最大类别概率值之差Δp,据BvSB准则排序所有未标记样本U,从中选择Us个最具不确定性的样本S,并交由操作者进行标注S={xk,yk}Usk=1(注:U中样本选择与类别无关,不按类别均匀选取)。
(4) 将S加入L中,即L=L∪S;同时从U中移除S,即U=U\S。
(5) 依据最新L和U样本集,执行步骤(2)—步骤(4),直至循环次数达到预设值,结束循环。
最终得到最新的标记样本集L与剩余未标记样本集U。
3.2 主动学习与图的半监督相结合的高光谱影像分类为减少标记样本使用,避免未标记样本资源浪费,本文采用标记与未标记样本相结合的图的半监督分类模型。其原理是用图来模拟数据的低维流形分布,然后根据标签传播算法[20],类别标记信息在图上由标记数据传递到临近的未标记数据。该数据图的顶点由所有标记和未标记数据点构成,两个数据点之间连线边的权重大小代表了这两个数据点的相似性程度。笔者将主动选择所构造的最新标记样本集L与影像全体未标记样本集T组合,即X=[L;T]={x1,x2,…,xl,xl+1,...,xl+u},l、u分别为影像I中最新标记样本数目与剩余未标记样本数目,并构造与之对应的标记矩阵Y。假设有3种地物类别,那么Y的行向量可能是1,0,0、0,1,0、0,0,1或0,0,0的任何一种。具体的分类算法如下。
(1) 按照两两样本间均有边相连接的构图方式形成图G,采用欧氏距离度量样本点之间的距离以及高斯径向基核函数(RBF)赋权值公式,给图G的边赋权值
式中,σ为高斯核宽,取值区间为[10-3,103]。为避免样本自相关,需将权阵W对角线上元素化为0。
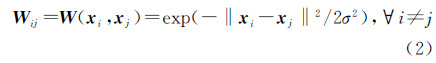
(2) 为使算法快速收敛,进一步对权阵W进行如下形式的标准化处理
(3) 计算分类函数
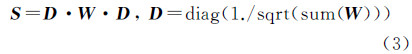
式中,α是[0,1]之间的参数,调节样本邻域信息与初始标记Y所占比重。F为m×c的矩阵,Fij为样本点xi被分为第j类标记的可能性大小,即argmaxj≤cFij就是样本点xi的最终标记信息。 4 试验结果与分析
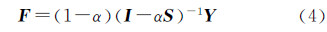
在Matlab R2011b平台下,以3组高光谱影像数据集来验证本文方法的有效性,试验从总精度OA、Kappa系数方面进行量化分析,且每一OA值和Kappa值均采用10次试验结果的平均值。
4.1 试验数据数据1:Pavia University数据(以下简称PaviaU数据),为ROSIS高光谱传感器系统在意大利南部的Pavia市的Pavia University上空拍摄的,数据大小为610像素×340像素,除去噪声波段,图像包含有103个连续波段,空间分辨率为1.3m,该地区共包含9种地物,各类地物真实标记如图 3(a)所示。

|
| 图 3 PaviaU分类试验图 Fig. 3 Claasification graph of PaviaU |
数据2:Pavia Center数据(以下简称PaviaC数据),为PaviaU的同源影像,数据大小为1096像素×715像素,除去噪声波段,图像共包含有102个光谱波段,分辨率为1.3m。该地区也包含9种地物,各类地物真实标记如图 4(a)所示。

|
| 图 4 PaviaC分类试验图 Fig. 4 Claasification graph of PaviaC |
数据3:Indian Pines数据,为AVIRIS传感器系统在美国印第安纳州西北部的Indian Pines测试站上空拍摄获取,数据大小为145像素×145像素,除去噪声波段,图像包含有200个光谱波段,分辨率为20m。由于网上提供的某些地物类别的已知标记数据过少,弃之而对该地区按9种地物类型分类处理[13],各类地物真实标记如图 5(a)所示。

|
| 图 5 Indian Pines分类试验图 Fig. 5 Claasification graph of Indian Pines |
这3个数据均是网上的公共数据,并提供了大量已标记好的样本。为了对本文算法进行验证,将这些已标记好的样本分成两部分进行试验设置,即3.1节中的起初少量的标记样本L和起初未标记样本U,因此可通过得到从U中选择的目标像元在原始影像中的位置,得到像元的真实标记;标记样本集构造之后,将其与剩余未标记样本集U组合用于图的半监督分类。同时,由于起初的标记样本较少,训练出来的模型不准确,进而导致样本分类的后验概率置信度不高,因此,主动选择过程中每次迭代选取的样本数目不能太多,而如若迭代次数过多,则会增加计算负荷。基于这两点考虑,本文将循环次数选定为18次,在每一循环中选取15个目标样本。
4.2 主动选择样本、随机选择样本的图的半监督与SVM方法比较将本文方法(active learning with graph-based semi-supervised method,AL+Semi-supervise)与随机选择样本的图的半监督方法(randomly-selective graph-based semi-supervised method,RS+Semi-supervise)、主动选择样本SVM(active learning with SVM,AL+SVM)及随机选择样本SVM (randomly-selective SVM,RS+SVM)等3种算法作比较。随机选择样本时,选取450个样本(即50个/类,共9种地物类别)作为标记样本;主动选择样本时,起初每类随机选取20个样本作为标记样本,据此训练得到SVM模型,并预测未标记样本可能被分为各类的后验概率,依据BvSB准则选择15个最大与次最大类别概率差最小的样本并给予人工标注,并将它们加入到标记样本集中,同时从未标记样本中剔除,然后重新训练模型、做预测及选择样本,该过程循环18次,最终同样选择450个样本。对于算法中涉及的σ和α两个参数,试验中分别取值为3和0.99。
PaviaU试验 4种不同方法的分类结果见表 1,视觉对比效果如图 3所示。从表 1可以看出,首先,旋转不变的空谱特征极大地改善了分类效果,较光谱特征的分类精度产生巨大提升。随着空间窗口尺寸的增加,各类方法的分类精度在不断提升,说明PaviaU影像存在大量连续的光谱同质性区域,但由于窗口过大会引起计算负荷急剧增加,故本文没有继续增加窗口试验;其次,半监督方法比监督方法的分类结果要好:在不同尺寸的空间窗口下,RS+Semi-supervise方法比RS+SVM方法的分类总精度高2.44%~8.29%,AL+Semi-supervise比AL+SVM总精度高2.52%~4.99%,可见未标记样本的引入提高了分类效果;然后,AL+Semi-supervise比RS+Semi-supervise方法分类总精度高1.55%~5.55%,AL+SVM比RS+SVM分类总精度高4.16%~5.47%,可知主动学习不仅可以改善监督分类算法,而且能使半监督分类方法有很大提升;最后,本文方法将主动学习算法与图的半监督方法有效结合,产生了高精度、稳定的高光谱影像分类结果。从图 3也可以看出,本文方法的分类效果较好。
| 方法 | 光谱特征 | 空-谱特征(窗口大小) | ||||||
| 3 | 5 | 7 | ||||||
| OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | |
| RS+SVM | 70.64 | 63.54 | 80.62 | 75.21 | 86.63 | 82.67 | 88.08 | 85.03 |
| AL+SVM | 81.40 | 74.95 | 86.08 | 81.61 | 90.79 | 87.82 | 93.59 | 91.54 |
| RS+Semi-supervise | 74.47 | 67.69 | 83.06 | 78.04 | 93.63 | 91.61 | 96.37 | 95.21 |
| AL+Semi-supervise | 85.54 | 80.69 | 88.61 | 84.66 | 95.78 | 94.41 | 97.92 | 97.34 |
PaviaC试验 4种不同方法的分类结果见表 2,其视觉对比效果如图 4所示。
| 方法 | 光谱特征 | 空-谱特征(窗口大小) | ||||||
| 3 | 5 | 7 | ||||||
| OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | |
| RS+SVM | 94.83 | 92.72 | 97.48 | 96.43 | 98.23 | 97.50 | 98.17 | 97.42 |
| AL+SVM | 97.35 | 96.24 | 98.21 | 97.46 | 98.89 | 98.38 | 99.10 | 98.73 |
| RS+Semi-supervise | 95.63 | 93.84 | 97.48 | 96.51 | 98.21 | 97.46 | 98.33 | 97.70 |
| AL+Semi-supervise | 96.62 | 95.21 | 98.34 | 97.60 | 98.83 | 98.34 | 99.15 | 98.79 |
由表 2可以看出,4种分类方法对PaviaC影像的分类效果都很好,分类总精度都达到97%以上,由此可以说明,PaviaC影像的光谱可区分性极高(表中第一列数据也说明了该问题),对分类方法的要求较低。尽管如此,还是可以看出,能得到与PaviaU数据相同的结论:旋转不变空间特征的引入,改善了仅含光谱特征的分类效果,同时,随着窗口的不断增加,各种方法的分类总精度呈上升趋势,说明该影像存在大量连续的光谱同质性区域,同样为避免计算负荷过大,没有继续增加窗口试验;其次,RS+Semi-supervise比RS+SVM方法精度略高、AL+Semi-supervise比AL+SVM方法效果略好,可见未标记样本的引入提高了分类效果,同样条件下的半监督方法比监督方法分类效果好;然后,可以看出主动学习算法对PaviaC影像同样有效,它使得SVM分类总精度提升了0.66~0.93%,使图的半监督算法总精度提升了0.62~0.86%,由于该影像自身辨识度较高的光谱特性,使得主动选择样本的效果不太明显,但较明显的是在空间窗口为7时,AL+SVM和AL+Semi-supervise算法的总精度达到99%以上,而其他方法均没有;最后,相比较之下,本文算法比其他3种方法还是展现出了一定的优势,分类总精度最高。各种方法的分类效果如图 4所示,由于它们的分类总精度都较高,所以视觉对比效果不明显。
Indian Pines试验 4种不同方法的分类结果见表 3,其视觉对比效果如图 5所示。
| 方法 | 光谱特征 | 空-谱特征(窗口大小) | ||||||
| 3 | 5 | 7 | ||||||
| OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | |
| RS+SVM | 63.94 | 58.21 | 69.26 | 64.57 | 76.56 | 72.73 | 80.59 | 77.39 |
| AL+SVM | 69.07 | 63.40 | 74.25 | 69.67 | 81.99 | 78.73 | 86.43 | 84.04 |
| RS+Semi-supervise | 64.91 | 59.27 | 76.07 | 71.89 | 85.80 | 83.40 | 88.34 | 86.36 |
| AL+Semi-supervise | 69.40 | 63.70 | 78.65 | 74.81 | 87.58 | 85.36 | 91.05 | 89.45 |
由表 3可知,与PaviaU、PaviaC相比,该数据的分类精度都不高,光谱特征的分类精度最高仅为69.40%,原因是该数据地面作物极为相似,地物交叉较为严重,光谱可辨识度较低。随着空间窗口尺寸的不断增加,各种方法的分类精度均得以提升12%左右,说明该数据存在光谱同质性区域,同时也证实了旋转不变空谱特征表达的有效性;RS+Semi-supervise比RS+SVM总精度高5.43%~6.81%,AL+Semi-supervise比AL+SVM总精度高4.40%~5.59%,可见引入未标记样本的半监督方法比监督方法分类结果明显要好;AL+SVM比RS+SVM分类总精度高4.99%~5.84%,AL+Semi-supervise比RS+Semi-supervise方法分类总精度高1.78%~2.71%,可见主动学习的引入极大地改善了分类效果,尤其是在窗口为7时,AL+Semi-supervise的分类总精度和Kappa精度分别达到91.05%和89.45%,而其他方法分类总精度均未能超过90%;由图 5也可以看出,本文方法的分类效果最好。
4.3 样本数目的选择与讨论3幅影像中,每类别选取10、20、30、40、50、60个样本的基于空-谱特征的图的半监督分类结果见表 4。可见,随着每类样本数目增多,分类精度在不断提升,在每类50个样本时,各数据分类精度分别达到95%、98%及88%以上,已满足分类需要,且当每类60个样本时,分类精度仅小幅度提升,但计算负荷却大大增加。因此,试验中每类样本选择50个。3组试验的主动学习构造的训练集的样本个数,以及其后用于图的半监督的未标记样本数目,见表 5。
| 每类样本数目 | PaviaU | PaviaC | Indian Pines | |||
| OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | OA/(%) | Kappa系数 | |
| 10 | 89.23 | 86.03 | 94.17 | 93.84 | 76.99 | 73.19 |
| 20 | 91.52 | 87.92 | 95.71 | 94.00 | 79.88 | 76.36 |
| 30 | 93.96 | 91.82 | 96.12 | 95.35 | 86.14 | 83.79 |
| 40 | 94.54 | 93.95 | 97.85 | 96.58 | 87.31 | 85.11 |
| 50 | 96.37 | 95.21 | 98.33 | 97.70 | 88.34 | 86.36 |
| 60 | 96.54 | 95.57 | 98.56 | 97.73 | 88.80 | 86.87 |
| 影像 | PaviaU | PaviaC | Indian Pines |
| 标记样本个数 | 450 | 450 | 450 |
| 未标记样本U中样本个数 | 40922 | 146304 | 8601 |
本文针对高光谱影像分类,提出了一种主动学习与图的半监督相结合的方法。试验表明该方法取得了较好的高光谱影像分类结果。本文方法的优点为:①空-谱特征提取算法简单而有效,且特征具有旋转不变性;②结合主动学习BvSB准则构造标记样本集,选择类别边界的样本予以标定,从而有利于分类器的边界构造,提高模型准确性;③半监督分类器,在较少标记样本可用情况下,通过引入易获取的未标记样本,可改善分类效果,避免资源浪费。本文方法仍存在待改善之处,可考虑更多的主动学习算法,并尝试其他半监督分类方法,以期用更少的标记样本、更少的人工参与,达到更为理想的分类效果。
| [1] | PENN B S. Using Simulated Annealing to Obtain Optimal Linear End-member Mixtures of Hyperspectral Data[J]. Computers & Geosciences, 2002, 28(7): 809-817. |
| [2] | RICHARDS J A. Remote Sensing Digital Image Analysis[M]. Berlin: Springer, 1999. |
| [3] | LI Hui, WANG Yunpeng, LI Yan, et al. Unmixing of Remote Sensing Images Based on Support Vector Machines and Pairwise Coupling[J]. Acta Geodaetica et Cartographica Sinica, 2009, 38(4): 318-323. (李慧, 王云鹏, 李岩, 等. 基于SVM和PWC的遥感影像混合像元分解[J]. 测绘学报, 2009, 38(4): 318-323.) |
| [4] | JIN Jing, ZOU Zhengrong, TAO Chao. Compressed Texton Based High Resolution Remote Sensing Image Classification[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(5): 493-499. (金晶, 邹峥嵘, 陶超. 高分辨率遥感影像的压缩纹理元分类[J]. 测绘学报, 2014, 43(5): 493-499.) |
| [5] | GUO Xiujuan, YUAN Yue, FAN Xiaoou. Analysis and Application of Fuzzy Clustering Algorithm[J]. Journal of Jilin Institute of Architecture & Civil Engineering, 2009, 26(4): 79-81. (郭秀娟, 袁月, 范小鸥. 模糊聚类算法分析及应用[J]. 吉林建筑工程学院学报, 2009, 26(4): 79-81.) |
| [6] | BOVOLO F, BRUZZONE L, CARLIN L. A Novel Technique for Subpixel Image Classification Based on Support Vector Machine[J]. IEEE Transactions on Image Processing, 2010, 19(11): 2983-2999. |
| [7] | ZHU X J. Semi-supervised Learning Literature Survey[OL/EB]. Wisconsin: University of Wisconsin, 2008.[2013-11-23]. http://pages.cs.wisc.edu/-jerryzhu/research/ssl/semireview.html. |
| [8] | TUIA D, CAMPS-VALLS G. Semisupervised Remote Sensing Image Classification with Cluster Kernels[J]. IEEE Transactions on Geoscience and Remote Sensing Letters, 2009, 6(2): 224-228. |
| [9] | LIU Xiaofang, HE Binbin, LI Xiaowen. Classification for Beijing-1 Micro-satellite's Multispectral Image Based on Semi-supervised Kernel FCM Algotithm[J]. Acta Geodaetica et Cartographica Sinica, 2011, 40(3): 301-306. (刘小芳, 何彬彬, 李小文. 基于半监督核模糊c-均值算法的北京一号小卫星多光谱图像分类[J]. 测绘学报, 2011, 40(3): 301-306.) |
| [10] | DOPIDO I, LI J, PLAZA A, et al. Semi-supervised Classification of Hyperspectral Data Using Spectral Unmixing Concepts[C]//Proceedings of the 2012 Tyrrhenian Workshop on Advances in Radar and Remote Sensing. Naples: IEEE, 2012: 353-358. |
| [11] | BRUZZONE L, CHI M, MARCONCINI M. A Novel Transductive SVM for Semisupervised Classification of Remote-sensing Images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2006, 44(11): 3363-3373. |
| [12] | DÓPIDO I, LI J, MARPU P R, et al. Semisupervised Self-learning for Hyperspectral Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 51(7): 4032-4044. |
| [13] | CAMPS-VALLS G, BANDOS MARSHEVA T, ZHOU D. Semi-supervised Graph-based Hyperspectral Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2007, 45(10): 3044-3054. |
| [14] | GU Y F, FENG K. L1-graph Semisupervised Learning for Hyperspectral Image Classification[C]//Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium. Munich: IEEE, 2012: 1401-1404. |
| [15] | JOSHI A J, PORIKLI F, PAPANIKOLOPOULOS N. Multi-class Active Learning for Image Classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Miami, FL: IEEE, 2009: 2372-2379. |
| [16] | HOTELLING H. Analysis of A Complex of Statistical Variables into Principal Components[J]. Journal of Educational Psychology, 1933, 24(6): 417-441. |
| [17] | TUIA D, VOLPI M, COPA L, et al. A Survey of Active Learning Algorithms for Supervised Remote Sensing Image Classification[J]. IEEE Journal of Selected Topics in Signal Processing, 2011, 5(3): 606-617. |
| [18] | CRAWFORD M M, TUIA D, YANG H L. Active Learning: Any Value for Classification of Remotely Sensed Data?[J]. Proceedings of the IEEE, 2013, 101(3): 593-608. |
| [19] | LONG Jun, YIN Jianping, ZHU En, et al. An Active Learning Algorithm by Selecting the Most Possibly Wrong-Predicted Instances[J]. Journal of Computer Research and Development, 2008, 45(3): 472-478. (龙军, 殷建平, 祝恩, 等. 选取最大可能预测错误样例的主动学习算法[J]. 计算机研究与发展, 2008, 45(3): 472-478.) |
| [20] | LAN Yuandong. Research on Theory, Algorithms and Application of Graph-based Semi-supervised Learning[D]. Guangzhou: South China University of Technology, 2012. (兰远东. 基于图的半监督学习理论、算法及应用研究[D]. 广州: 华南理工大学, 2012.) |