


2. 河南理工大学 测绘与国土信息工程学院,河南 焦作 454000;
3. 信息工程大学 测绘与科学技术博士后流动站, 河南 郑州 450052
2. School of Surveying and Land Information Engineering, Henan Polytechnic University, Jiaozuo 454000, China;
3. Postdoctoral Research Center of Surveying and Mapping, PLA Information Engineering University, Zhengzhou 450052, China
随着“数字城市地理空间框架建设”战略的推广,数字地名建设及研究已经成为学术界的热点。尤其随着网络技术的迅速发展及人们对基于位置服务需求的快速增长,地名已经成为普通民众获取信息的重要地理参考。因此,如何从海量的地理信息资源中快速、准确检索所需信息,已成为地名研究中的重要课题。准确高效的地名匹配算法是实现以地名为参考的信息检索、排序、数据挖掘等功能的关键,更是空间数据库中要素匹配的重要研究内容。
地名匹配算法目前主要分为三大类:①将地名视为字符串,从字面相似度的角度研究地名匹配程度,包括全字匹配方法、字符串匹配度函数法、基于SQL通配符的汉字匹配方法和基于全文检索技术的查询方法、模糊查询及以字母代替汉字等方法[1, 2, 3],该类方法提供了较好的查询效率,但由于将地名作为普通字符串处理,忽略了其符号和语义特性,难以保证较高的准确率;②从空间或几何角度研究地名或地理要素匹配[4, 5, 6],该类方法是以距离、面积、大小、位置及形状等空间和几何特性为依据构建相似度模型,为多源空间数据集成和更新提供基础,该类方法易受数据存储方式、空间数据精度、数据格式、数据库存取效率等影响,其通用性和应用范围受到较大限制,由于涉及大量几何运算,执行效率相对较低;③从地名语义特征角度研究地名表达和查询方法[7, 8, 9, 10, 11],该类方法从本质性上比较地名间的关系,结果具有较好的可靠性,但由于缺乏统一规范的标准地名本体,影响了该方法在实际中的应用。
针对上述3类地名匹配算法存在的不足,考虑到地名组成形式的复杂性,本文面向规范汉语地名提出了一种顾及通名语义的地名复合相似度匹配算法。该算法顾及了规范汉语地名独特的构词方式[12]及地名通名对地名的指义性[13, 14],除考虑专名字面特性外,将地名通名语义知识作为地名匹配的重要参考,结合认知习惯,利用动态加权法求取地名复合相似度指标,从而提高地名匹配的召回率和准确率。
2 顾及通名语义的汉语地名复合相似度算法模型规范汉语地名一般由专名和通名两部分构成。本文提出分别求取两地名的专名和通名相似度值,再根据两者所占的权重计算两地名的复合相似度值,用公式(1)表示。模型中的专名相似度和通名相似度分别采用字面相似度和语义相似度方法求解
式中,a、b表示两个规范地名;a1、b1分别为a、b的专名;a2、b2分别为a、b的通名;sim_lit(a1,b1)为a1、b1的字面相似度值;sim_sem(a2,b2)为a2、b2的语义相似度值;sim(a,b)为地名复合相似度值,三者均为0到1的数,数值越大表示相似度越大,0表示完全不同,1表示二者为同一对象。Plit为专名相似度的权重(Plit∈[0, 1]);Psem则为通名相似度权重(Psem∈[0, 1]),二者满足Plit+Psem=1。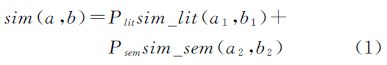
权重设置遵循以下认知思想:当通名语义相似度高时,认为二者表达的是相近的地理实体,地名相似度主要由专名相似度表达;反之,说明两地名表达的是相异的地理实体,专名相似度可靠性随之降低。由此可见,专名相似度和通名相似度的权重是动态变化的,据此本文提出了动态确权方法——首先为地名定性,考察其语义关系,再由语义相似度决定其专名相似度的权重。
本文提出的地名相似度值的计算方法(式(1))满足如下要求:
(1) 任何概念与其自身的语义相似度为1。
(2) 所有地名通名均为同根概念节点,故sim_sem均为大于0的值。
(3) 若sim_sem为无穷小,则Plit接近0,专名可靠性最低,此时两通名表示完全不同的两种地理实体或现象,在不考虑转义通名的情况下,认为二者不可能为同一地名。
(4) 若sim_sem=1,则Plit为1,此时两地名通名为同一概念,只需比较专名的相似度。
(5) 若sim_sem=1且sim_lit=1,则两地名的复合相似度值为1,二者为同一地名。
(6) 若sim_lit=0,此时表示个体的标志符完全不同,基本可排除同一地名的可能。
根据上文权重设置思想和计算要求,本文提出建立Plit与sim_sem的分段连续单值递增函数关系,如下式
式中,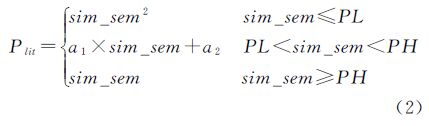
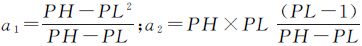 。函数图形如图 1。
。函数图形如图 1。

|
| 图 1 专名相似度权重与语义相似度的函数关系 Fig. 1 Function between similarity weight of the special names and semantic similarity |
该函数中PL和PH为分界点,当通名相似度小于PL时,两地名语义相差较远,专名可信度急剧降低,取sim_sem2为专名相似度值权重;当通名相似度大于PH时认为两地名语义相近,专名相似度较为可靠,以sim_sem作为专名相似度值权重;PL和PH(PL<sim_sem<PH)之间的区域专名可信度介于上述两种情况,权重关系以连接两端点的直线函数表示。PL和PH的设置可以根据专家经验设置初值,并利用大样本数据进行检验、修改,以适应不用的应用环境。
3 汉字地名专名相似度专名用于指示地理实体专有属性,由于其用词广泛,目前尚缺少统一的汉字语义库及比较标准,本文简化其语义比较过程,将其作为字符串,在进行专名比对时仅考虑其字面特性。编辑距离法是较为常用的字面相似度求解方法,用以计算从原字符串转换到目标字符串串所需要的最少的字符插入、删除和替换的编辑次数。本文采用该方法计算地名专名相似度,首先从两个字符串的一端开始比较,记录已经比较过的子串编辑操作,然后得到下一个字符位置时的编辑操作。汉语地名专名比较时以汉字为基本处理单位,对于两个汉语字符串X=x1x2x3…xn,Y=y1y2y3…ym,其中xi(i∈[1,n]),yi(i∈[1,m])均为汉字字符。汉字编辑距离计算中,编辑操作代价的值是[0, 1]之间的非负数,可以根据需要预先设置不同的值。本文选取0和1两个值,并规定:当汉字xi=yj(i=1,2,…,n;j=1,2,…,m)时,替换的代价为0;否则所有编辑操作代价都是1。
设Ed(a1,b1)为专名a1、b1的编辑距离,则构造地名专名相似度模型如下式
式中,max(a1,b1)表示汉语字符串a1、b1最大长度(以汉字为单位)。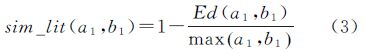
例如“河南理工大学”和“河南大学”的专名“河南理工”及“河南”的最小编辑距离为Ed=2,最大长度为4,根据式(3)可得专名相似度为0.5。
4 汉语地名通名语义相似度地名匹配时除考虑地名专名的字面相似度外,还应考虑地名之间的语义相似度。与传统的以词形为切入点、字符匹配算法相比,语义相似度计算是对源和目标词语在概念层面上的相似度的度量,需要考虑词语所在的语境和语义等信息。
本体因其能准确描述概念及其之间的内在联系,已经成为语义相似度的研究基础。完整的地名本体涉及概念、关系、实例、公理、规则等内容,涵盖广泛,包含实例的地名本体数据量庞大,涉及空间概念及关系时则更加复杂,其基本内涵、构建方法、存储模式、检索方式等尚没有成熟理论和统一的技术。因此,本文提出基于地名分类标准,依据通名与地名类型的紧密关系,建立仅涉及简单层次关系的轻量级地名本体——地名通名语义知识库,用于支持地名语义相似度判断。
4.1 地名通名语义知识库地名通名是地名所代表的地理实体或现象的类型、隶属关系、形态和性质的规定称呼,用来区分地理实体性质类别[15]。由于地名用词不规范及各种历史原因,同一通名可能表示多种地理实体类型。对此,本文取地名的主要含义进行表达,暂不考虑近义通名、转义通名等情况[13, 14, 15, 16]。
为充分利用地名中的通名语义知识,通过搜集整理大量地名专著、文献及开源资料对常用地名通名进行统计,依据《地名分类与类别代码编制规则(GB/T18521—2001)》建立了规范汉语地名通名语义知识库,并使其成为一个轻量级的上层地名本体[16]。该本体中的地名通名主要依据通名所反映地理实体的最基本、最稳定的属性对地名进行分类,建立基于上下位关系(“IS-A”)的通名本体框架。本文建立的通名语义知识库片段如图 2所示,箭头表示“IS-A”关系。

|
| 图 2 地名通名知识库片段 Fig. 2 Excerpt from knowledge base for general names for places |
基于本体的语义相似度算法主要包括概念信息量法、语义距离法、基于属性的语义相似度及混合式语义相似度等方法[17, 18]。概念信息量法以信息论和概率统计为基础,需进行大量文集统计工作,不适宜于通名语义的计算;由于缺少对地名通名的严格属性定义,基于属性的相似度判断同样不适合通名语义计算。因此,本文采用基于概念层次结构的语义距离法计算地名通名之间的语义相似度。
基本假设如下:两概念的语义距离越大,其相似度越低,反之相似度越高[17, 18]。设通名a2和b2分别对应通名语义知识库中的概念(要素类别)con1和con2,记sim_sem(con1,con2)为二者的语义相似度,根据通名与概念的关系可知sim_sem(a2,b2)=sim_sem(con1,con2)。
设Dist(con1,con2)为本体中两概念的最短语义距离,则语义相似度与语义距离之间的存在如下关系:
(1) 当Dist(con1,con2)为0时,sim_sem(con1,con2)为1,表示两概念完全相同。
(2) 当Dist(con1,con2)为无穷大时,sim_sem(con1,con2)为0,表示两概念完全不相似或不相关。
用公式表示如下式
式中,d为调节因子,可根据专家意见或由指定语义距离的概念之间的相似度反演得到。例如,设定某本体中最短距离为1的概念间的语义相似度为0.96,代入上式,可求出d的参考值为24。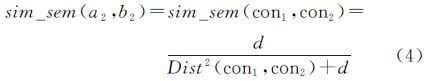
基于语义距离的通名语义相似度算法中,影响语义的主要因子有:概念深度,概念密度,关系类型,关联强度和概念属性等[18, 19, 20, 21, 22]。根据当前通名知识库的内容和结构特点,本文主要考虑前三者对语义相似度的影响。
4.2.1 概念深度概念深度指概念节点与根节点的最短路径中包括的边数。概念深度对语义相似度的影响基于以下思想:以“IS-A”关系建立的本体概念树中,每一概念是其上位概念的细化,越到下层,概念所指的对象越具体,内涵越丰富。同等语义距离下,两个概念节点的深度越大,相似度越高,反之相似度越低;相反,同等语义距离下二者的概念层次差越小,则二者的语义相似度越高,反之相似度越低。
定义Dep(con)为概念con的深度;设root为根节点,令其深度为1,即Dep(root)=1。
任意非根节点概念con的深度Dep(con)=Dep(Parent(con))+1,其中Parent(con)为con的直接上位概念节点。
Dep(tree)为本体树的深度,Dep(tree)=max(Dep(coni)),(i=1,2,…,n),其中n为概念的总数,coni为本体中的任意概念。
因此,概念深度对语义相似度影响因子的计算如式(5),且满足Ps∈(0,1]
4.2.2 概念密度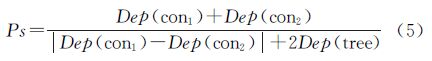
本体层次中,局部区域概念密度越大,说明该区域概念细化程度越大,该处概念分类越具体,在其他因素相同的条件下,直接概念子节点间的语义相似度就越高。
定义Child(con)为概念con所包含的直接子节点的个数;Child(tree)为本体树中各概念节点中子节点数的最大值。
设两个概念con1和con2最近共同祖先为cona,其直接子节点的个数为Child(cona);则概念密度对语义相似度影响因子计算如式(6),且满足Pm∈(0,1]
4.2.3 关系类型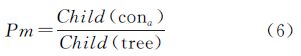
本体中概念通过各种关系联系在一起,不同关系类型对概念语义相似度的影响也有所不同。如上下位的“同义关系”所表征的语义相似度应大于“整体-部分”关系所表征的语义相似度。在关系类型不多的情况下,可采用专家打分的方法来确定关系类型的语义强度。设Pr为关系强度,则Pr∈(0,1]。
4.2.4 改进的语义相似度算法综合了上述影响因素的地名通名语义相似度算法为
式中,α、β、γ、δ为调节因子,且满足α+β+γ+δ=1。由于语义距离在相似度计算中占主导地位,其他因子起辅助作用,所以α的权重相对较大,而β、γ、δ的权重相对较小。该语义相似度模型中权重大小的设置,除遵循上述原则外,可采用与用户交互或大样本数据进行训练的方法对初始权重进行修正,以满足不同上下文应用环境的要求。 5 地名复合相似度匹配综合评价与实例分析 5.1 地名复合相似度匹配综合评价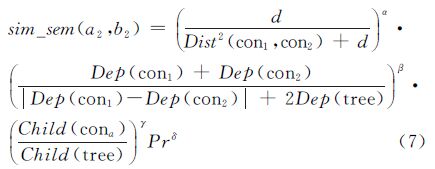
基于上文的匹配算法模型,本文进一步提出了该算法的计算策略及地名关系的综合评价方法,其技术流程如图 3。该计算流程采用阈值过滤被检索对象,逐步排除非目标对象,缩小目标范围。基本过程如下:①对地名进行预处理,剔除非法字符,保证地名用词和构成的完整性;②将地名与通名库进行比对,遵循右侧优先,长度优先等原则,确定地名通名,进而将地名分解为专名和通名两部分;③计算通名相似度,其结果可以对两地名性质进行判断,根据阈值决定是否需要进入下一步专名相似度的判断;④比较专名字面相似度,根据阈值决定是否进入复合相似度计算;⑤根据上述通名和专名相似度值结合动态权重函数求取地名复合相似度值,并对大于阈值的地名进行排序,得到匹配结果。综合考虑上述流程产生的单项和复合指标,可以较为全面地把握地名的性质及它们之间的关系。由于复合相似度的范围为0~1的正数,数值越高相似度越高,即越可能为同一地名;数值越接近0则说明二者的相似度越小,不是同一地名的可能性越大。上述阈值的大小会直接影响算法的效果,其设定通常先根据经验设定初值,再利用样本进行检验和迭代,逐步接近最优值。

|
| 图 3 地名相似度匹配流程 Fig. 3 Matching process for similarity of place names |
将上述阈值1、阈值2、阈值3均设置为0.5,以下表 1中“华北水利水电学院”、“华北水利水电大学”为例说明复合相似度比对过程如下:分离二者的专名和通名,分别得到专名“华北水利水电”和“华北水利水电”及通名“学院”和“大学”;求“学院”、“大学”的语义相似度为0.8,大于0.5;于是进行专名相似性的比较,得到专名相似度为1,大于0.5;再进行复合相似度求取,其值为0.96,大于0.5,且较接近于1,因此认为二者很可能为同一地名。
5.2 试验分析本文利用河南省某地名数据库对上述算法及流程进行了检验,试验结果证明了该算法的合理性和有效性。
5.2.1 数据来源本文以河南省某地名数据库随机抽取的3000条地名记录作为试验数据。这些数据覆盖了全省范围,其中无通名地名147条,无专名地名1条,不规范地名412条,同区域(县级)重复地名322条,不同区域重复地名541条。试验使用《地名分类与类别代码编制规则(GB/T18521—2001)》作为构建通名知识库的基本框架,并利用试验地名数据库的通名对其进行扩充,作为本次试验语义比较的基础。利用两个同样的地名记录集合,进行相互匹配试验,以验证匹配效果。由于试验数据并非完全的规范地名,为保证试验的有效性,试验对无通名的地名仅进行了专名相似度求解,对部分不规范地名进行了预处理。本文仅从规范地名角度研究地名关系,不考虑地名实际的空间位置关系,因此仅将上述重复地名作为相同地名处理,而不作进一步空间关系的辨析。
5.2.2 试验结果与分析本文建立的通名知识库中仅考虑了通名间的上下位关系(未考虑其他关系类型),因此设Pr=1。试验时,将式(2)、式(3)、式(7)代入式(1),并根据专家经验及随机抽取的300条样本数据利用迭代算法对参数进行优化,最终设PL=0.4,PH=0.6,u=24,α=0.8,β=γ=0.1。表 1分别求取了典型地名对的“通名相似度”、“专名相似度”、“复合相似度”、纯基于字符串的“字面相似度”。
| 地 名 对 | 概念 距离 | Dep(con1) | Dep(con2) | Child(cona) | 通 名 相似度 | 专 名 相似度 | 复 合 相似度 | 字 面 相似度 |
| 确山县 | 确山 | 8 | 5 | 5 | 2 | 0.30 | 0.50 | 0.32 | 0.67 |
| 东风渠公园 | 东风渠 | 6 | 5 | 5 | 8 | 0.47 | 0.66 | 0.53 | 0.60 |
| 河南理工大学 | 河南大学 | 0 | — | — | — | 1.00 | 0.50 | 0.50 | 0.67 |
| 郑州市 | 焦作市 | 0 | — | — | — | 1.00 | 0.00 | 0.00 | 0.33 |
| 河南省 | 焦作市 | 4 | 5 | 5 | 8 | 0.65 | 0.00 | 0.23 | 0.00 |
| 华北水利 水电学院 | 华北水利 水电大学 | 2 | 6 | 6 | 3 | 0.80 | 1.00 | 0.96 | 0.75 |
(1) “确山县”和“确山”,从规范地名来看二者语义上差别很大,前者是“行政区划”,后者是“自然地名”,复合相似度指标借助语义知识库进行判断,结果为0.32,较接近人的认知的判断,而字面相似度0.67不能很好地反映这种关系;“东风渠公园”和“东风渠”与此情况类似。
(2) “河南理工大学”和“河南大学”,为同类型地名,复合相似度匹配算法在通名相同的情况下,以专名相似度代替复合相似度,结果为0.5,降低了二者为同一地名的可信度,较符合实际;其字面相似度为0.67,表明二者是同一地名的可靠性较高,与实际情况不相符。
(3) “郑州市”和“焦作市”的情况与(2)类似,通名相同,专名完全不同,复合相似度指标为0,否定了二者同一地名的可能性。
(4) “河南省”和“焦作市”,通名具有较高的相似度说明二者在性质上有相似之处;专名相似度为0,则从符号角度否定了二者的同一性,其复合相似度仅为0.23,基本可以判断不是同一地名;各指标值符合认知习惯。
(5) “华北水利水电学院”与“华北水利水电大学”,为同类型高等本科院校,且专名相同,为同一所大学可能性极大,复合相似度指0.96印证了这一点;纯字面相似度则忽略了“学院”和“大学”的语义,相似度仅为0.75,不能很好地反映二者的同一性。
上述典型地名实例充分说明了本文提出的地名复合相似度指标具有较高的地名辨析能力。由试验结果可以看出,基于本文算法及策略实现的匹配程序查全率为99.08%,查准率为98.55%,达到了预期目标,而且该算法更接近人的认知习惯,提高了规范地名的匹配准确率,为地名关系判断提供了科学依据。从数据误差分析上看,地名不规范是影响算法有效性的主要因素,今后应进一步加强非规范地名的处理方法研究。
6 结 论本文将规范地名分解为专名和通名,利用编辑距离法和改进的语义距离法分别求取专名和通名的单项相似度,再利用动态加权方法求得地名复合相似度指标,并提出了基于该模型的地名匹配策略和流程,采用阈值过滤非目标对象,增强了地名匹配算法的理论完备性和有效性。主要创新有两点:① 建立基于地名分类的地名通名语义知识库,并在该库支持下,从地名性质入手,逐步确定地名之间的关系;② 模拟认知习惯,根据地名通名语义相似度动态确定各单项相似度指标的权重。试验结果验证了该方法的科学性和可靠性,提高了无约束规范地名的匹配准确率,为地名参照的查询系统提供了有效的检索方法,为地名本体的应用提供了新思路。该算法中的语义关系仅考虑了通名间的“IS-A”关系,不能全面反映地名间语义关系,今后将重点研究地名本体中其他关系类型尤其是空间关系对地名相似度的影响以及其他地名形式的匹配算法。
| [1] | ZENG Wen, YAN Junxia. Design and Application of an Urban GIS Place Name Location Tool [J]. Journal of Earth Science,2006,31(9):725-728.(曾文,鄢军霞.城市GIS地名定位工具的设计及应用[J].地球科学:中国地质大学学报,2006,31(9):725-728.) |
| [2] | YU Jianfeng, WANG Guangxia,WAN Gang. Implement of Geographical Name Retrieval Based on Fuzzy Bopomofo [J]. Journal of Geomatics Science and Technology,2008,25(2):120-123.(於建峰,王光霞,万刚.基于汉字模糊音的地名查询方法设计与实现[J].测绘科学技术学报,2008,25(2):120-123.) |
| [3] | LIAO Yilan, WANG Jinfeng, MA Jiaqi, et al. Place Name Data Matching Based on BPM-BM Algorithm[J].Bulletin of Surveying and Mapping, 2008(6):22-25. (廖一兰,王劲峰,马家奇,等.基于BPM-BM算法的地名数据匹配[J].测绘通报,2008(6):22-25.) |
| [4] | TONG Xiaohua, DENG Susu, SHI Wenzhong. A Probabilistic Theory Based Matching Method[J]. Acta Geodaetica et Cartographica Sinaca, 2007,36(2):210-217. (童小华, 邓愫愫, 史文中. 基于概率的地图实体匹配方法[J] .测绘学报, 2007, 36(2): 210-217.) |
| [5] | HAO Yanling, TANG Wenjing, ZHAO Yuxin, et al. Areal Feature Matching Algorithm Based on Spatial Similarity[J]. Acta Geodaetica et Cartographica Sinaca, 2008, 37(4):501-506.(郝燕,唐文静,赵玉新,等.基于空间相似性的面实体匹配算法研究[J].测绘学报,2008,37(4):501-506.) |
| [6] | AN Xiaoya, SUN Qun, XIAO Qiang, et al. A Shape Multilevel Description Method and Application in Measuring Geometry Similarity of Multi-scale Spatial Data[J]. Acta Geodaetica et Cartographica Sinica, 2011,40(4):495-502.(安晓亚,孙群,肖强,等.一种形状多级描述方法及在多尺度空间数据几何相似性度量中的应用[J].测绘学报,2011,40(4):495-502.) |
| [7] | LIU Yu, ZHANG Yi, TIAN Yuan, et al. On General Place Names and the Associated Ontology[J].Geography and Geo-Information Science,2007,23(6):1-7.(刘瑜,张毅,田原,等.广义地名及其本体研究[J].地理与地理信息科学,2007,23(6):1-7.) |
| [8] | CHENG Gang, DU Qingyun. Construction and Application of Ontologies in Location-based Services[J]. Journal of Liaoning Technical University:Natural Science,2009,28(5): 708-711. (程 钢,杜清运.基于位置服务中的本体构建及应用[J]. 辽宁工程技术大学学报:自然科学版,2009,28(5): 708-711.) |
| [9] | LI Shuxia, AN Min, LI Hongwei, et al. Design of the Ontology of Place Based on Commonsense Spatial Cognition[J]. Journal of Geomatics Science and Technology,2011,28(6):450-453.(李淑霞,安敏,李宏伟,等.常识空间认知研究与地名本体设计[J].测绘科学技术学报,2011,28(6):450-453.) |
| [10] | JANOWICZ K,KESSLER C. The Role of Ontology in Improving Gazetteer Interaction[J].International Journal of Geographical Information Science,2008,22(10):1129-1157. |
| [11] | JI Xiaoyan, ZHOU Min. A Study of Processing Technique of Place Name Data in Construction of Global Basic Geographic Base Map Database [J]. Bulletin of Surveying and Mapping, 2006(7):45-48.(季晓燕,周敏. 全球基础地理底图数据库建设中对地名数据处理技术的探讨[J]. 测绘通报, 2006(7):45-48.) |
| [12] | BENNETT B, AGARWAL P. Semantic Categories Underlying the Meaning of Place[C]//Proceedings of the 8th International Conference on Spatial Information Theory (COSIT 2007). Melbourne:[s.n.], 2007. |
| [13] | ZHANG Chunju, ZHANG Xueying, JI Leijing, et al. Relation Mapping between Generic Terms of Place Names and Geographical Feature Types [J]. Geomatics and Information Science of Wuhan University, 2011,36(7):857-861.(张春菊,张雪英,吉蕾静,等.地名通名与地理要素类型的关系映射[J].武汉大学学报:信息科学版,2011,36(7):857-861.) |
| [14] | CHU Yaping, YIN Junke, SUN Donghu. The Toponymy Essentials[M]. 2nd ed. Beijing: Surveying and Mapping Press, 2009.(褚亚平,尹钧科,孙冬虎.地名学基础教程[M].第2版.北京:测绘出版社,2009.) |
| [15] | WANG Jitong. Norms for General Chinese Place Name[J]. China Place Name,2002(3):20-23.(王际桐.中国汉语地名通名的规范[J].中国地名,2002(3):20-23.) |
| [16] | Ministry of Civil Affairs of the Peoples Republic of China. Rules for Classification of Geographical Names and Code Representation GB/T18521-2001 [S].Beijing:China Biaozhun Press,2002.(中华人民共和国民政部.地名分类与类别代码编制规则GB/T18521-2001[S].北京:中国标准出版社,2002.) |
| [17] | CHENG Gang,LU Xiaoping, GE Xiaosan, et al. Data Fusion Method for Digital Gazetteer[C]//Proceedings of 18th International Conference. Beijing:[s.n.],2010. |
| [18] | HUANG Shiguo, GENG Guohua. The Survey on Semantic Similarity Metric [J]. Computer Applications and Software,2008,25(2):37-39.(黄世国,耿国华.语义相似性测度方法研究综述[J].计算机应用与软件,2008,25(2):37-39.) |
| [19] | SUN Haixia, QIAN Qing, CHENG Ying. Review of Ontology-based Semantic Similarity Measuring [J].New Technology of Library and Information Service,2010(1):51-56.(孙海霞,钱庆,成颖.基于本体的语义相似度计算方法研究综述[J].现代图书情报技术,2010(1):51-56.) |
| [20] | LIU Jingfang, ZOU Ping, ZHANG Pengzhu, et al. Research on an Improved Algorithm of Concept Semantic Similarity Based on Ontology[J].Journal of Wuhan University of Technology ,2010,32(20):112-127.(刘景方,邹平,张朋柱,等.一种改进的本体概念语义相似度算法研究[J].武汉理工大学学报,2010,32(20):112-127.) |
| [21] | JIANG Hua. Research on Concept Semantic Similarity Computation Based on Ontology [J]. Computer Applications and Software,2009,26(7):143-145.(姜华.一种基于本体的概念语义相似度计算研究[J].计算机应用与软件,2009,26(7):143-145.) |