



2. 北京建筑大学 现代城市测绘国家测绘地理信息局重点实验室,北京100044
2. Key Laboratory for Urban Geomatics of National Administration of Surveying, Mapping and Geoinformation, Beijing University of Civil Engineering and Architecture, Beijing 100044, China
1 引 言
机载LiDAR能快速获取大面积高密度、高精度的三维点云数据,被广泛用于数字城市、 数字地面模型获取、海岸线探测等领域。三维点云数据解析及分类对场景理解及后续的兴趣目标建模有重要的意义,因此点云分类成为目前的一个研究热点。一般采用两种方法对点云进行分类:① 定义特定规则对目标进行提取[1, 2, 3];② 用机器学习的方法进行点云监督分类[4, 5, 6]。现阶段点云分类研究的主要内容包括:城市场景分类[6, 7, 8],建筑物提取[3, 9]以及自然物体提取[10]等。
利用机载LiDAR测量的点云数据进行分类具有一定的复杂性,如缺乏直接表达物体表面的语义信息(例如纹理和结构),空间三维点云数据本身具有不连续性、不规则性,以及地物形态的多样性等。特别当地面起伏较大,或有高程阶跃时,现有的方法使用归一化的高程值作为特征[11],不能很好地区分地面;或者需要用地形滤波的方法先确定地面信息,再对其他类别进行区分[12]。因此本文主要从两个方面对点云分类进行研究:① 筛选计算简单,且能代表待分类物体的有效特征,使用特征选择的方法对分类无效特征进行剔除;② 对现有分类算法进行优化,使分类速度及精度得到提高。本文研究目标为较复杂场景中的地物自动分类,场景中类别包括:建筑物、植被、地面(包括起伏及阶跃地面)、电力塔、电力线等。
2 分类方法 2.1 点云数据预处理机载激光点云粗差点主要有低点、飞点、孤立点等,粗差点剔除有利于提高后续的分类效果。常用的粗差剔除方法为:首先建立点云的高程直方图,设置阈值对分布在直方图最高及最低尾部值的点(低点、飞点)进行剔除;然后比较点与其周围点的高差,当高差大于一定的值时,其为孤立点[16]。本文利用Terrasolid进行粗差点剔除。
2.2 点云分类关键特征定义点云分类场景较为复杂,目标多样,如:对于地面类别,不仅有平地、坡地,还有阶跃类型的地面(梯田等)。这要求所定义的特征要更加细致和准确,能有效区分每一种类别。特征值的计算通常需要连同三维邻域内的其他点一起统计和分析,因此,特征的定义需要考虑邻域的形状和大小。
2.2.1 邻域设定点云特征计算需要考虑三维空间邻域的其他点。本文定义了3种方式划分点云邻域:① 以待分类点为中心的球体邻域vs;② 以待分类点为中心的垂直圆柱体邻域vc;③ 对整个数据集采用2D格网划分的格网邻域vg。邻域vs用于统计待分类点局部范围内点分布,有利于统计同一类物体的点云分布情况。邻域vc、vg对待分类点空间垂直分布(垂直剖面相关特征等)及相邻空间点分布(阶跃指数)进行统计,有利于统计待分类物体同其他类别物体的关联关系。
2.2.2 特征定义(1)阶跃指数(Is)
非地面点通常高于其周围地面点,且局部地形点高程变化较少,基于此,本文设计了阶跃指数特征。如果待分类点在各个方向上比周围的点高一定的阈值TH,此点是非地面点的概率较大。为了便于特征值计算,将待分类点云数据划分为格网,统计待分类点在所有方向上同周围点的高差。实际计算过程中,主要对8个方向进行了统计。
如图 1所示,图中格网灰度值代表格网最低高程值,从待分类点所在的中心网格开始,依次比较每个方向上相邻网格的最低高程差,当前一个网格的最低高程值比后一个网格的最低高程值小于一定的阈值TH,且此方向的长度小于阈值TL,则认为该方向为阶跃方向。阶跃指数(Is)是所有8个方向中阶跃方向的数目。由于此特征计算需要考虑8个方向,在边缘格网处计算不稳定;在机载大范围点云测量及工程应用中,数据获取一般有一定的冗余,可以弥补此缺陷。

|
| 图 1 阶跃指数特征计算示意图 Fig. 1 Step-off index computing method |
(2)高程相关的特征
这一类特征包括多个内容:球状邻域vs和垂直圆柱体邻域vc内所有点的高程方差(δzs,δzc)、最大值最小值之差(Δzs,Δzc);归一化的高程值(Nz),即待分类点与其2D格网中最低值的差值。
(3)协方差矩阵相关特征
计算球状邻域vs内点云三维坐标的协方差矩阵,此矩阵可以被视为表示球状邻域内点分布信息的三维结构张量。各向异性(Aλ)、线性(Lλ)、平面性(Pλ)、球度性(Sλ)是协方差矩阵的数学特征,这些特征描述了点云局部空间分布特性[17]。
(4)回波相关特征
点云一般记录有多次回波,不同的地物对应的回波次数有所差异,可以结合待分类点球状邻域vs内不同回波点所占比例提取出:建筑物回波(Be)、地面回波(Ge)、线回波(Le)、植被回波(Te)等特征[12]。
(5)回波强度相关特征
不同材质的物体点云回波强度不同,因此,本文统计了球状邻域vs内所有点的回波强度均值(Ia)用于区分不同地物。
(6)霍夫变换特征(Ht)
霍夫变换能提取出线状物体,在本文研究的分类场景中可以帮助区分电力线。将球状邻域vs内所有点投影到xy平面上,进行霍夫变化后,探测出角度极值θmax,结合其附近的值,计算通过该角度极值区域的点的比例,称为霍夫变换特征[12]。
(7)密度相关特征
本文定义点密度(Pd)为球状邻域vs内单位体积点数量;不同类型的物体点密度不同,地面和建筑物表面点密度最高,植被的点密度比电力线的密度高等。同时,定义密度比率(Dr)为球状邻域vs内点的数目同柱状邻域vc内点的数目的一定比率[12]。
(8)面相关特征
将球状邻域vs内所有点拟合成一个平面,计算邻域内所有点到此平面的距离的方差,此特征为平面指数(PI)。地面和建筑物顶面平面指数较小,而植被平面指数较大。由于屋顶类型不仅有平面屋顶,还有人字形屋顶等;在人字形屋脊上,平面指数可能失效。针对这一特点,本文同时引入了表面指数(SI)。表面指数是待分类点格网邻域vg内所有点的平面指数的平均值。
(9)投影相关特征
将球状邻域vs内所有点投影到一定的平面上,计算其投影面积:对投影平面进行一定大小的格网划分,当格网内有投影点时,此格网为非空格网,投影面积为非空格网的数目。本文主要选取两种投影方式,xy平面和与xy平面垂直的平面。xy投影面积(Pa)是以xy平面为投影平面计算得到的特征。地面及屋顶xy投影面积较大,而电力线xy投影面积较小。由于与xy垂直的平面有无穷多个,本文按照一定的角度间隔遍历一定数量的平面,取具有最小投影面积的平面;此平面的投影面积为z方向的最小投影面积(Pb)。使用z方向的最小投影面积(Pb),植被有较大值,地面及屋顶投影面积次之,而电力线投影面积最小。
(10)垂直剖面相关特征
对垂直柱体邻域vc在z方向上划分为等距离分段,可以提取出垂直剖面的特征[12];一般植被、电力塔在垂直剖面上的占有多个分割,且分割具有连续性,而电力线等在垂直剖面上只有少量的非空分割。当垂直剖面某一分割内有点时,称此分割非空。非空分割数目(Nnb)是待分类点所在垂直柱体邻域上所有非空分割的数目。同时,可以计算最大连续非空分割数目(Non)和最大连续空分割数目(Noff)。
2.3 JointBoost分类方法优化本文借鉴了目标跟踪中在线特征选择[18]的思想,结合空间地物关联性及JointBoost算法提出了一种序列化的点云分类及特征降维方法。文中采用的上下文相关思想用于对基于局部特征分类器(JointBoost)的判别规则进行改进,降低特征使用量。上下文相关的分类器,如条件随机场能对点云进行有效分类[6],但是由于这类分类器计算复杂度高,需要较强的计算性能,对于大范围的机载点云数据的快速甚至是实时分类有一定的影响,因此本文未采用。
2.3.1 空间相关性提取场景中的地物在空间分布上存在连续性和规律性,如:地面下面不可能有植被,植被上不可能有建筑物等。本文引入了空间相关性的贝叶斯模型,此模型通过对待分类点类别的先验概率及其周围已分类点的类别的似然性进行统计计算待分类点的后验概率
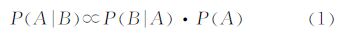
式中,A是待分类点的类别;B是周围点的类别;P(A)是待分类点类别为A的先验概率;P(B|A)是假定待分类点类别为A时,周围点类别为B的似然性;P(A|B)为待分类点类别为A的后验概率。先验概率和似然性通过对已分类的训练数据统计得到,并且可以在分类过程中通过对已分类数据统计进行更新。为了统计的精确性,将似然性分为3部分(见图 2所示)
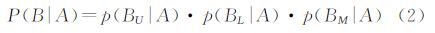
式中,P(Bu|A),P(BL|A)和P(BM|A)分别是周围点在待分类点上部,下部及中部的似然性。

|
| 图 2 空间相关性提取方式示意图 Fig. 2 The method of spatial correlation extraction |
JointBoost分类器是一类增强快速学习算法规则,是传统Boost分类规则的多类别扩展[13],其使用特征的方式简单,可以通过对弱分类器的增减实现对特征的不同使用[14, 15]。
JointBoost分类器的输入是待分类对象的特征向量z,输出是对待分类对象每一个可能类别l∈C(C是待分类对象所有可能类别的集合)的概率值函数
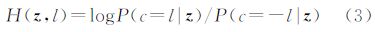
分类器H(z,l)由M个弱分类器组成
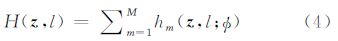
当H(z,l)>0时,P(c=l|z)>P(c=-l|z),即把特征向量z代表的待分类物体分为l类。
每一个弱分类器依据特征向量z的第f维分量值zf对可能的类别l进行评分,具体见下式
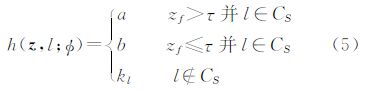
弱分类器在训练阶段依据损失函数最小化的原则对φ参数(包括CS、f、a、b、kl)进行选择及计算。具体训练方法参看文献[13]。
2.3.2.1 特征排序当要判定待分类对象的类别是否为l类时,需要对此类相关的特征进行重要性排序。
对分类器训练完成后,依据每个弱分类器对应的类别集合CS,可以从所有训练得到的弱分类器集合中确定l类相关的弱分类器子集合Hl。对特定类别l相关的每一维向量zf,计算涉及的弱分类器最小值的和
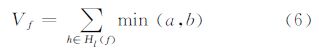
式中,Hl(f)代表与特征zf以及类别l相关的所有弱分类器子集合;a、b定义见公式(5) 。由于在强分类器判决中,与类别l和特征zf相关的弱分类器子集合计算的值不可能小于此最小值,因此可以用此值对类别l相关的特征进行排序,在分类过程优先采用数值较大的特征。采用此排序方式,可能采用较少的特征满足类别的判断条件,提前终止类别判断。
2.3.2.2 判决结构序列化对待分类对象的可能类别概率进行计算及对特定类别的特征进行排序后,使用下述序列化的判决结构,对原始的判决方式进行改进。具体算法为:
(1) 基于空间相关性提取对待分类点类别概率进行计算,排序后的可能类别依次为c1,c2,…,cN,设置所有类别的判据为0:H(ci)=0,i=1,2,…,N。
(2)依次取第ci类别,i=1,2,…,N。
(a) 选取和类别ci无关的弱分类器,设置H(ci):=H(ci)+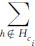 kci。
kci。
(b) 依据特征排序准则,对类别ci相关的T维特征进行排序,获得排序后的特征序列:zi1,zi2,…,ziT。
(c) 依次取排序后的第m维特征zm,m=i1,i2,…,iT。
(i) 选择和类别ci以及特征zm相关的弱分类器集合Hci(m)。
(ii) 对强分类器的数值进行更新

(iii) 选取所有和类别ci相关,且未使用的特征弱分类器集合Hci(m+1:iT),如果
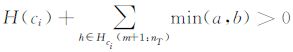
设置待判定点的类别为 ci ,并且停止(2)迭代。
序列化判断过程中,判断待分类对象类别是否为某一类l时,将所有弱分类分成3部分:第1部分为和类别l无关的弱分类器组合,统计kl值;第2部分为类别l相关,已使用特征的弱分类组合,按照原始相关的弱分类计算相应的值;第3部分为类别l相关,未使用特征的弱分类组合,计算弱分类器中a、b的最小值。当H(ci)>0时,依据公式(3)可以判断P(c=ci|z)>P(c=-ci|z),即可将待分类对象判定为ci类。
在利用地物的空间关联关系,对待分类对象类别进行有效预测的基础上,采用优化的判决结构进行分类,不需要提取所有类别相关的特征,可以达到特征降维从而减少特征计算时间的目的。
3 试验和分析本文使用的试验数据为电力应用激光扫描数据,点云密度为70/m2。为了验证算法的有效性,从原始数据中选取两个数据集合:训练集和测试集;训练集大小约为100万点,测试集大小约为500万点。目标类别为地面、植被、建筑物、电力塔、电力线。首先,从训练集中随机选取每个类别4000个样本集用于对JointBoost分类器进行训练;剩余的训练数据作为验证集对分类器的参数(弱分类器数量)及邻域大小进行分析及选取[19]。训练好的分类器可以用于对测试集进行分类验证。试验环境采用Intel I3处理器3.1 GHz主频,4 GB内存的计算机。
3.1 空间相关性提取通过对训练数据分析计算可知,本文所选区域空间中地面、植被、建筑物、电力线、电力塔的先验概率值从高到低依次降低。同时对不同物体的似然性进行统计。图 3所示为已知待分类点为植被时,位于其上部、中部、下部物体分别为某一类别的似然性概率;可以看出植被上部为植被的概率值最高,中部为植被的概率值次之,植被下部为地面也具有较高的概率,属于其他类型的概率值较小。

|
| 图 3 植被空间似然性统计量 Fig. 3 Spatial likelihood statistic value of vegetation |
由于JointBoost需要多次弱分类器迭代,经过分析,本组试验选取弱分类器数量为100,对原始JointBoost分类器和序列化的JointBoost分类器特征使用量及分类时间进行比较。图 4为准确率(基于弱分类器数量) 同原始JointBoost分类器及序列化的JointBoost 分类器使用特征维数的关系图;其中,序列化的JointBoost分类器显示的为对象分 类平均使用的特征维数。

|
| 图 4 JointBoost和序列化的JointBoost分类器特征使用维数示意图 Fig. 4 Comparison of number of features needed to achieve the same performance while using JointBoost and serialized JointBoost |
使用序列化的JointBoost分类算法和原始的分类算法相比,达到同样的分类精度,序列化的JointBoost基本上只需要一半数量的特征(图 4)。点云特征计算过程中需要大量三维点分析和统计处理,比较耗时。使用原始JointBoost分类器对约500万点的测试区域进行分类,需要时间为10 h 20 min左右。当使用序列化的JointBoost分类器,由于特征计算量较小,计算时间也降为原始分类器的3/5左右。
在试验中,JointBoost分类器选择的特征按重要程度(弱分类器数量)依次为Nz、Is、PI、Ia、Aλ、Δzc、δsz、Be、Lλ、Le、Ht、Pb、Pλ、SI、Non、Nnb、Dr、Pd、Te、Ge。
使用JointBoost分类器对每一对象分类需要对上述选择的所有特征进行计算,而使用本文提出的序列化的JointBoost对特定的对象进行分类时,相关对象的次要的特征计算可以省略,图 5显示了特征的平均使用率,可以看出,较不重要的特征使用率较少。图 5横轴对应于上述选择的特征,依照重要程度顺序排列。

|
| 图 5 序列化JointBoost特征使用率分析 Fig. 5 The analysis of features’ utilization rate using serialized JointBoost |
特征邻域大小对分类准确率高低有较重要的作用,因此需要对特征邻域大小进行定量分析。在分析过程中,选球状、柱状邻域直径与格网大小一致;对不同的邻域大小与分类精度的关系进行了统计。分析可知当邻域大小为2~3 m时,分类效果最佳。本组试验最终采用2.5 m的邻域大小对数据进行分类。
3.2.2 正确率分析图 6及表 1展示了测试数据的分类结果,分类精度达到了较高的93.53%。同时,区域中有很多误分点:① 某些电力塔点分布不稳定,被分成了电力线及植被;② 由于较浓密、顶部平整的植被同建筑物顶部具有相同的特性,某些植被点被分为了建筑物;③ 某些低矮的植被点因为高程较低被分为地面点;④ 某些建筑物边缘的点由于跳跃较大,被分成了植被等。

|
| 图 6 测试集(400 m×170 m 约500万点)分类结果 Fig. 6 Classification result of test data set (400 m×170 m around 5 000 000 points) |
| 地 面 | 植 被 | 建筑物 | 电力线 | 电力塔 | 准确率 | |
| 地 面 | 2 490 620 | 107 729 | 29 126 | 37 | 23 | 0.947 9 |
| 植 被 | 50 828 | 1 625 008 | 12 025 | 5 013 | 1 346 | 0.959 1 |
| 建筑物 | 57 153 | 38 106 | 439 252 | 1 527 | 11 | 0.819 4 |
| 电力线 | 135 | 13 061 | 2 769 | 85 775 | 1 328 | 0.832 2 |
| 电力塔 | 271 | 758 | 402 | 509 | 17 865 | 0.902 0 |
| 查全率 | 0.958 3 | 0.910 5 | 0.908 3 | 0.923 7 | 0.868 4 |
为了验证本文提出的方法的有效性,同点云处理商业软件Terrasolid的分类结果进行对比。Terrasolid点云分类是依据特定的规则对不同类别的点云进行逐步分类,前一类别的分类结果如果有分类错误会对后续类别的分类结果照成一定的影响。本文使用Terrasolid依次对点云中地面、建筑物、植被、电力线进行了提取,由于Terrasolid中未有电力塔提取的功能,故电力塔点被完全错分为了其他类别。表 2为采用Terrasolid对数据分类的混淆矩阵。
| 地 面 | 植 被 | 建筑物 | 电力线 | 电力塔 | 准确率 | |
| 未分类 | 41 888 | 401 216 | 14 099 | 15 722 | 314 | |
| 地 面 | 2 041 507 | 9 735 | 46 044 | 16 | 58 | 0.973 4 |
| 植 被 | 498 548 | 1 340 428 | 33 982 | 26 319 | 7 722 | 0.581 0 |
| 建筑物 | 17 064 | 33 271 | 389 449 | 607 | 78 | 0.884 2 |
| 电力线 | 0 | 12 | 0 | 50 197 | 12 401 | 0.801 7 |
| 电力塔 | 0 | 0 | 0 | 0 | 0 | 0 |
| 查全率 | 0.785 5 | 0.751 1 | 0.805 4 | 0.540 6 | 0 |
本文在点云数据预处理的基础上,首先基于点云的几何、强度、回波等特性归纳提取了26维点云分类特征。同时,提出了一种序列化的JointBoost分类算法,该方法结合地物的空间相关性,在保证原始分类器精度的前提下,能有效地减少分类过程中使用的特征量。本文的研究能有助于较复杂的三维场景的全自动处理。采用多种特征进行统计学习实现复杂场景点云自动分类是一条技术上最为可能的途径。此外,本文所用的方法能一次同时得到地形、建筑物、植被等目标,不需要预先提取地形,能有效避免传统方法因地形提取错误而引起的后续分类错误。
点云分类研究对于后续的目标(建筑物、植被、电力塔等)建模及三维虚拟城市具有建立重大意义。但是,复杂场景的点云分类研究是一项复杂、有挑战的任务,还需在分类方法、提高分类精度及实时化方面进行更加深入研究。特征在分类过程中至关重要,特征是否能完整的代表待分类物体,仍然是一个值得研究的问题。深度学习是一种检测原始数据和特征之间关系的规则[20],若能将其应用到点云分类领域,将能提高分类的精度及可靠性。另外,点云缺乏纹理信息,若融合图像信息进行分类应该能提高点云的分类精度,这些将是接下来研究的目标。
| [1] | MONGUS D, ALIK B. Parameter-free Ground Filtering of LiDAR Data for Automatic DTM Generation[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2012, 67(1):1-12. |
| [2] | YANG Bisheng, WEI Zheng, LI Qingquan, et al. A Classification-oriented Method of Feature Image Generation for Vehicle-borne Laser Scanning Point Clouds[J]. Acta Geodaetica et Cartographica Sinica, 2010, 39(5): 540-545.(杨必胜, 魏征, 李清泉, 等. 面向车载激光扫描点云快速分类的点云特征图像生成方法[J]. 测绘学报, 2010, 39(5): 540-545.) |
| [3] | HUANG Xianfeng,GUNHO S,WANG Xiao,et al. Roof Detection Using LiDAR Data Based on Points’Normal with Weight [J]. Geomatics and Information Science of Wuhan University, 2009, 34(1) : 24-27. (黄先锋, GUNHO S, 王潇, 等. 基于带权点方向量的LiDAR数据屋顶检测方法[J] . 武汉大学学报: 信息科学版, 2009, 34(1) : 24-27.) |
| [4] | MUNOZ D, BAGNELL J A, et al. Contextual Classification with Functional Max-Margin Markov Networks[C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Miami:IEEE, 2009:975-982. |
| [5] | ZHANG J X, LIN X G. Object-based Classification of Urban Airborne LiDAR Point Clouds with Multiple Echoes using SVM[C]//Proceedings of ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences. Melbourne:[s.n.], 2012: 248-253. |
| [6] | NIEMEYER J, WEGNER J D, MALLET C, et al. Conditional Random Fields for Urban Scene Classification with Full Waveform LiDAR Data[M].Photogrammetric Image Analysis. Berlin:Springer, 2011: 233-244. |
| [7] | CHEHATA N, GUO L. Airborne LiDAR Feature Selection for Urban Classification Using Random Forests [C] // Proceedings of Laser Scanning 2009. Paris :IAPRS, 1999: 207-212. |
| [8] | MALLET C, BRETAR F. Relevance Assessment of Full-waveform LiDAR Data for Urban Area Classification[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2011, 66(6): 71-84. |
| [9] | HUANG Xianfeng, SOHN G. A Competition Based Roof Detection Algorithm from Airborne LiDAR Data[J]. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2008, 37(3): 319-324. |
| [10] | WAGNER W, HOLLAUS M. 3D Vegetation Mapping Using Small-footprint Full-waveform Airborne Laser Scanners[J]. International Journal of Remote Sensing, 2008, 29(5): 1433-1452. |
| [11] | LODHA S K, FITZPATRICK D M, et al. Aerial LiDAR Data Classification Using Expectation-Maximization[C]// Proceedings of the SPIE Conference on Vision Geometry.[S.l.]:SPIE, 2007: 1-11. |
| [12] | KIM H B, SOHN G. 3D Classification of Power-line Scene from Airborne Laser Scanning Data Using Random Forests[C] // Proceedings of IAPRS.Saint-Mande:[s.n.], 2010: 207-212. |
| [13] | TORRALBA A, MURPHY K P. Sharing Visual Features for Multiclass and Multi-view Object Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 19(5): 854-869. |
| [14] | FRIEDMAN J, HASTIE T. Additive Logistic Regression: A Statistical View of Boosting[J]. The Annals of Statistics, 2000, 28(1): 337-407. |
| [15] | BISHOP C.Pattern Recognition and Machine Learning[M]. New York:Springer, 2006: 657-663. |
| [16] | SILVN-CRDENAS J L, WANG L. A Multi-resolution Approach for Filtering LiDAR Altimetry Data [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2006, 61(1): 11-22. |
| [17] | GROSS H, THOENNESSEN U. Extraction of Lines from Laser Point Clouds[J]. International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences, 2006, 36 (3): 86-91. |
| [18] | COLLINS R T, LIU Y. Online Selection of Discriminative Tracking Features[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2005, 27(10): 1631-1643. |
| [19] | KALOGERAKIS E, HERTZMANN A, SINGH K. Learning 3D Mesh Segmentation and Labeling[J]. ACM Transactions on Graphics, 2010, 29(3): 102-114. |
| [20] | HINTON G E, SALAKHUTDINOV R R. Reducing the Dimensionality of Data with Neural Networks[J]. Science, 2006, 313(5786): 504-507. |