


1 概 述
近年来,随着对地观测技术的飞速发展,光学遥感卫星数据源迅速增加,影像分辨率大幅提高,需要处理的数据量快速增长:以GeoEye、Pleiades、WorldView、资源三号等为代表的国内外高分辨率光学卫星的单景影像数据量最大已达到GB级,整轨数据量通常可以达到上百GB。处理这些大规模遥感数据所需的计算量呈指数级增长。传统的光学卫星数据处理架构和算法主要考虑数据处理的质量和精度,并未顾及计算效率,已无法满足在应急应用领域中对海量数据光学卫星遥感影像的快速处理要求,以CPU和GPU协同处理为代表的高性能处理架构和并行处理算法逐渐成为卫星数据处理领域新的研究热点。
正射校正是光学卫星遥感影像用于灾害防治、抢险救灾等具体应用的关键处理环节,也是整个遥感数据处理过程中计算最密集、耗时最长的步骤之一[1]。对高分辨率、大幅宽的影像进行正射校正耗时很长,已成为制约整个光学卫星数据处理快速完成的瓶颈。近年来,随着半导体技术的飞速发展,图形处理单元(graphics processing unit,GPU)的计算性能以超过摩尔定律的速度不断提高,已成为当前计算机系统中具备高性能处理能力的部件[2, 3]。光学卫星遥感影像正射校正算法计算量密集,且具有先天并行性,非常适合于在GPU上进行处理。
目前,国内外相关学者和研究机构对在GPU上进行正射(几何)校正开展了一定的研究,使用GPU提高大数据遥感影像的正射(几何)校正效率逐渐成为共识。著名的影像处理软件PCI Geomatics在2009年4月发行了Pro-Lines GeoImaging Server系统,该系统使用GPU并行计算技术对遥感影像进行几何校正,获得了较高的加速比[4];文献[5]通过研究正射校正等遥感数据处理算法在GPU硬件上的映射方法,实现了对航拍数据的高效处理,从而为在轨实时灾害监测提供支持。在国内,文献[6]以仿射变换几何校正方法为例介绍了在GPU上进行几何校正的方法,较传统的几何校正算法加速2~3倍;文献[7]在保证影像正射纠正精度的基础上测试基于GPU的数字影像正射纠正的速率,证明了基于GPU的数字影像正射纠正的性能相对于CPU有较大的提高,算法加速比达到3~5倍。由于设计和实现较为简单,并未顾及GPU性能优化策略,上述校正方法并没有完全发挥GPU的计算性能。文献[4]搭建了CPU-GPU协同并行计算平台并完成了正射纠正的CPU-GPU协同处理和性能优化,利用GeForce 9500 GT显卡对大小为6000像素×6000像素的全色影像进行多项式纠正对比试验,证明GPU处理效率明显优于CPU处理效率,最邻近内插和双线性内插的最终加速比分别为8.45倍和10.91倍[4],但由于使用的GPU芯片较老,并未涉及针对当前主流的基于Fermi架构的GPU进行性能优化的理论和方法。
如何将正射校正算法的各个步骤合理映射到CPU和GPU上进行处理,并针对当前主流GPU的架构特点对映射到GPU上的步骤进行性能优化,是提高基于CPU和GPU协同处理的正射校正算法效率的关键。本文采用当前主流的基于Fermi架构的GPU,针对CPU和GPU协同处理架构的特点,系统地探讨基于CPU和GPU协同处理的光学卫星遥感影像正射校正方法,以充分利用CPU和GPU协同处理架构的计算性能。
2 原理及方法 2.1 CPU和GPU协同处理原理自2001年以来,由于具有单指令多数据流的处理能力,GPU被广泛应用于各种图形图像处理算法中,如影像匹配、并行形态学端元提取、SAR模拟等[2, 8, 9, 10, 11]。利用GPU的并行性能够为海量图像数据的高效处理提供帮助。2007年,NVIDIA公司提出了统一设备计算架构(compute unified device architecture,CUDA)。该架构将GPU作为CPU的协处理器,采用了与标准C语言完全兼容的开发环境,促进了GPU通用计算的发展[11, 12]。
CUDA的基本思想是尽量地开发线程级并行,这些线程能够在硬件中被动态地调度和执行。如图 1所示,CUDA将GPU看作一个由若干个线程块组成的线程网格,每个线程块内部又包含若干个线程,线程是GPU上最小的硬件执行单位。在具体执行时,线程被组织成线程块并以线程块为单位进行调度执行[13]。存储层次性访问是CUDA的另一个重要特点。如图 2所示,在CUDA架构中,GPU的存储空间被划分为不同的层次,包括全局存储器,共享存储器,寄存器、常数存储器等,这些存储器的大小和访问速度各不相同,在具体应用中可依据实际需要设计数据存取模式[14]。

|
| 图 1 GPU内部线程组织方式 Fig. 1 Thread organization pattern in GPU |

|
| 图 2 GPU内部存储层次性访问结构 Fig. 2 Hierarchical memory access pattern in GPU |
CPU和GPU协同处理技术是指将CPU作为控制端和串行程序执行端,负责数据传输、初始化和启动GPU,执行并行程度不高、计算量不大的程序;GPU作为超大规模数据协处理器,接受CPU的调度,执行计算量大、并行程度高、可以被高度线程化的程序[15, 16]。CPU和GPU各司其职、相互协作,高效快速地完成整个数据处理任务。
2.2 基于CPU和GPU协同处理的正射校正方法光学卫星遥感影像正射校正是指按照一定的数学模型,并引入DEM等参考数据共同消除原始卫星影像中的各种畸变,获取一幅符合某种地图投影要求的新影像。其基本任务是实现两个二维图像间的几何变换[4]。在正射校正的过程中,必须首先确定纠正变换模型,有理多项式(rational polynomial coefficients,RPC)模型是目前使用较为广泛的纠正变换模型。作为广义的新型遥感卫星传感器成像模型,RPC模型是一种能获得和卫星遥感影像严格成像模型近似一致精度、形式简单的概括模型,当给定适当数量的控制信息时,可以获得很高的拟合精度[17, 18, 19]。根据映射关系的不同,正射校正方案可分为两种,分别称为直接法方案和间接法方案[20]。由于直接法不能直接得到校正结果影像上的每个点的灰度值,需要利用灰度值分配的思路来简化处理流程以达到和间接法同等规模的计算复杂度,因此在GPU上容易出现严重的存储器写访问冲突和数据不一致等问题,降低GPU的计算效率[5]。采用基于输出影像进行任务划分的间接法校正方案则不存在上述问题。该方法计算过程简单,可以直接得到校正结果影像上每个点的灰度值,比较容易映射到GPU上进行处理。因此,本文采用具有先天并行性的间接法方案作为校正方案,保证GPU的计算效率,并采用RPC模型作为纠正变换函数的模型,保证校正后的影像具有较高的几何精度。
选定校正方案和纠正变换函数模型后,接下来需要进行任务划分和映射。间接法校正方案的主要步骤包括:构造RPC模型,计算地面点坐标,将地面点坐标和DEM代入RPC模型反算像点坐标,灰度内插和赋值[20]。由于RPC模型参数解算需反复迭代进行,不具有并行性,且该步骤计算量较小,在整个正射校正过程中只需要计算一次,因此映射至CPU进行处理。地面点坐标和像点坐标计算、灰度内插和赋值需要逐像素进行,计算量大、耦合程度高,因此映射至GPU进行处理。
如图 1所示,由于硬件限制,GPU将线程按照线程块和线程网格的形式组织。因此,在GPU上进行正射校正的基本策略为“层次性分块”,即将整幅校正后虚拟影像作为“一层块”,与一个GPU线程网格对应;再将整幅影像进行逻辑切割,形成“二层逻辑块”,每一个“二层逻辑块”与一个GPU线程块对应,且大小与GPU线程块的大小保持一致,以保证线程块中线程对“二层逻辑块”中的每一个像素都进行处理,如图 3所示。

|
| 图 3 GPU层次性分块策略 Fig. 3 Hierarchical tiling strategy in GPU |
采用“层次性分块”策略后,基于CPU和GPU协同处理的光学卫星遥感影像正射校正方法流程如图 4所示。说明如下:
(1)准备好待校正影像和对应的DEM数据,在CPU上构造RPC模型,并将RPC模型、待校正影像和DEM数据拷贝至GPU全局存储器中。
(2)设置GPU线程块大小,并根据校正后影像大小确定线程块数量。
(3)GPU线程块内线程按索引号计算对应的地面点坐标和像点坐标,并进行灰度内插和赋值。
(4)将校正后影像拷贝回主机内存中。
2.3 基于配置选择和存储层次性访问的方法优化2.2节所述方法仅为基本实现,并未考虑利用配置选择和存储层次性访问策略提高方法的执行效率。本节对GPU线程块进行配置选择,并利用GPU常数存储器上的cache以及Fermi架构GPU特有的二级片上缓存,提高方法的计算访存比和执行效率。

|
| 图 4 基于CPU和GPU协同处理的光学卫星遥感影像正射校正流程 Fig. 4 The CPU-GPU co-processing orthographic rectification flow for optical satellite imagery |
在Fermi架构系列的GPU中,线程块被映射到流式多处理器中调度执行。在满足如下3个准则时,流式多处理器的调度性能达到最优[13]。
准则1:线程块中线程数小于1024。
准则2:流式多处理器中线程块数量小于8。
准则3:流式多处理器中线程数等于1536。
图 5列出了当线程块大小(线程块中线程数)变化时,流式多处理器中线程块数量和线程数量的变化情况。

|
| 图 5 线程块大小变化时流式多处理器中线程块和线程数量的变化情况 Fig. 5 The relationship between block and thread numbers in a stream multiprocessor and thread numbers in a block |
从图 5可知,当GPU线程块大小为256和512时,流式多处理器中线程块数量分别为6个和3个,在这两种情况下,流式多处理器中的线程数都达到1536个,同时满足准则1、准则2和准则3,调度性能达到最优。因此,对执行正射校正算法的GPU线程块进行配置选择优化,将其大小设置为256或512,可以提高流式多处理器的调度性能,从而提高算法的执行效率。
除全局存储器外,GPU上还有一个64 KB的常数存储器。该存储器存储空间小,且为只读存储器,但由于设计有8 KB的cache,因此在满足特定的访问模式时,访存速度明显优于全局存储器。在2.2节所述算法中,RPC模型参数较少,且计算完成后不再改变,满足常数存储器对存储空间和数据只读的要求;此外,在通过地面点坐标计算像点坐标时,同步执行的所有线程在同一时刻将访问同一个RPC参数,因此,当第一个线程访问常数存储器获得RPC参数并将其载入到cache后,后面的所有线程都可直接命中cache,如图 6所示。因此,将RPC模型参数放入常数存储器中,可以提高算法的计算访存比,从而提高算法的执行效率。

|
| 图 6 常数存储器中RPC参数的命中情况 Fig. 6 RPC parameters hit analysis in const memory |
除全局存储器和常数存储器外,Fermi架构的GPU在每一组处理核心中放置了64 KB的片上缓存,作为共享缓存和一级cache使用。此外,在片上缓存和全局存储器之间还放置了768 KB的二级cache。二级cache为系统级cache,由GPU硬件负责数据调度和缓存;片上缓存则可根据需要柔性重组,通过动态调整共享存储器和一级cache的大小,可以提高算法和程序的执行效率。本文使用间接法方案对光学卫星遥感影像进行正射校正,虽然每个线程块对应校正后虚拟影像的二层逻辑块为规则块,但该虚拟影像二层逻辑块对应的输入影像块并不为规则块,在单程序多数据流程序设计中,将边界动态变化的、不规则的输入影像块载入到共享存储器中存在困难。由于Fermi架构GPU可动态调整片上缓存,因此本算法在共享存储器不可用时,将更多的片上缓存(48 KB)分配给一级cache,如图 7所示。由于相邻线程进行灰度内插时读取的输入影像像素间隔不大,如果将更多的片上缓存分配给一级cache,缓存更多的待校正影像,可以增加线程块灰度内插时命中一级cache的几率。

|
| 图 7 动态调整片上缓存后 GPU存储结构 Fig. 7 GPU Memory structure after dynamic reallocation |
2012年1月9日,我国首颗高精度民用立体测绘卫星“资源三号”成功发射升空。该卫星搭载一台高分辨率下视全色延时积分成像(TDI CCD)相机,两台前视、后视全色TDI CCD相机和一台下视多光谱相机。其中下视全色相机地面分辨率为2.1 m,采用16 bit量化,标准景影像大小为24 520像素×24 575像素,数据量较大(约1.12 GB),具有较好的代表性。为验证所述算法的正确性和性能,本文对资源三号卫星下视全色影像进行基于CPU和GPU协同处理的正射校正。试验环境中CPU型号为Intel Xeon E5650,含6颗计算核心,主频2.66 GHZ;GPU选择当前主流的基于Fermi架构的NVIDIA Tesla M2050,含448颗计算核心,全局存储器大小3 GB,常数存储器和片上缓存大小都为64 KB,峰值浮点计算性能为448 Gflops;主机内存大小为24 GB。
如表 1所示,本文首先测得在试验环境的CPU上对资源三号卫星下视标准景影像(校正前数据量1.12 GB,校正后数据量1.49 GB)进行RPC参数解算的时间,以及分别使用逐点正射校正算法、中国资源卫星应用中心产品生产系统中的正射校正算法、ERDAS IMAGINE 9.2中的正射校正算法对资源三号下视标准景影像进行正射校正的时间(重采样方法分别采用最邻近法、双线性插值法、双三次插值法)。从表中可知,在试验环境中RPC参数解算时间较短,而采用3种传统的正射校正方法完成一景资源三号下视标准景影像正射校正所需时间都很长,成为制约算法处理效率的瓶颈。因此,需要按照本文方法对资源三号卫星下视影像进行基于CPU和GPU协同处理的正射校正,提高算法处理效率。
| s | ||||
| 算法类型 | RPC参数解算时间 | 正射校正时间 | ||
| 最邻近法 | 双线性插值法 | 双三次插值法 | ||
| 逐点RPC正射校正算法 | 1.9 | 424.2 | 450.3 | 499.8 |
| 中国资源卫星应用中心生产系统中正射校正算法 | 1.9 | 314.1 | 366.5 | 402.3 |
| ERDAS IMAGE 9.2中正射校正算法 | 1.9 | 262.2 | 301.3 | 343.3 |
本节使用时间加速比对算法进行评价,定义如下[21]

式中,Ts为表 1中所示的在 CPU 上进行正射校正所需时间;Tp为在 GPU 上进行正射校正所需时间;Sp为加速比。图 8列出了在线程块大小和重采样方法不同的情况下,使用2.2节中的方法在 NVIDIA Tesla M2050 GPU 上对资源三号卫星下视标准景影像(校正前数据量1.12 GB,校正后数据量1.49 GB)进行正射校正的时间和相对于逐点RPC正射校正算法的加速比。可以发现:
(1) 由于采用了“层次性分块”策略,大量GPU线程同时对影像进行处理,因此校正时间大幅缩短,与逐点RPC正射校正算法相比,本文算法的加速比达到84.64~106.07倍。
(2) 在线程块大小一定的情况下,校正时间越长,加速比越高。理论上,算法加速 比Sp与 GPU 线程有效使用率σ成 正比[13],即

式中,σ定义如下
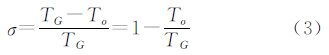
式中,TG为 GPU线 程的总运行时间(即校正时间);To为创建和销 毁GPU 线程等开销所需时间。由于To为一常数,因此σ与TG成正比。又根据式(2),Sp与σ成正比,故Sp与TG成正比。
在使用双三次插值法进行灰度重采样时,GPU线程的总运行时间(即校正时间)最长,故其有效使用率最高,算法加速比也就越高。相反的,使用最邻近法时GPU线程的总运行时间最短,因此算法加速比相应也最低。
(3) 当选择最邻近法和双线性插值法进行重采样时,若GPU线程块大小设置为256,算法执行时间最短;当选择双三次插值法进行重采样时,若GPU线程块大小设置为512,算法执行时间最短,这与2.3节中得到的结论“对执行正射校正算法的GPU线程块进行配置选择优化,将其大小设置为256或512,可以提高流式多处理器的调度性能,从而提高算法的执行效率”吻合。从2.3节中对配置选择优化的分析可知,线程块大小设置为256或512都可以使GPU流式多处理器的性能达到最优,试验中执行时间略微有差异的原因主要来自硬件性能在正常范围内的波动和计时系统的误差。

|
| 图 8 线程块大小不同的情况下在GPU上进行正射校正的时间和相对于逐点RPC正射校正算法的加速比 Fig. 8 The calculation time of orthographic rectification in different block sizes in GPU and its corresponding speedup ratio to point-to-point RPC orthographic rectification |
图 9列出了参照2.3节对线程块执行配置优化(将GPU线程块大小设置为256或512),并利用GPU常数存储器和片上缓存动态分配策略对算法进行优化后的执行时间和相对于逐点RPC正射校正算法的加速比。可以发现:
(1) 优化后算法的执行时间进一步缩短。无论采用何种重采样方法,加速比都达到了100倍以上。
(2) 当使用双三次插值法作为重采样方法时,最终加速比达到了110倍以上,相应的处理时间压缩至5 s以内。

|
| 图 9 对算法进行进一步优化后的执行时间和相对于逐点RPC正射校正算法的加速比 Fig. 9 The calculation time of optimized orthographic rectification in GPU and its corresponding speedup ratio to point-to-point RPC orthographic rectification |
将本文算法与文献[4]中算法在本文试验环境中的试验结果进行比较,如表 2所示。由于针对当前主流的基于Fermi架构的GPU进行了实现和性能优化,因此本文算法的执行效率较优。与文献[4]中算法相比,在使用最邻近法、双线性插值法和双三次插值法时,算法性能提升比分别达到1.43倍、1.42倍和1.35倍。
通过统计灰度直方图的差异可知,使用本文算法获取的校正后影像与在CPU上使用逐点RPC正射校正获取的校正后影像的灰度值完全相同,说明了本文算法的正确性。此外,由于采用了精度较高的RPC模型作为纠正变换函数的模型,与此前同类算法相比,本文算法可以保证校正后的影像具有较高的几何精度。
4 结束语本文系统地探讨了利用CPU和GPU协同处理架构对光学卫星遥感影像进行正射校正的方法。首先对正射校正算法进行任务划分,并使用“层次性分块”策略设计了基于CPU和GPU协同处理的正射校正方法;然后通过配置选择优化,并利用GPU常数存储器上的cache以及二级片上缓存进一步提高了方法的执行效率。使用本文方法在Tesla M2050 GPU上对资源三号卫星下视标准景影像进行正射校正,与逐点RPC正射校正算法相比,加速比可以达到84.64~106.07倍。其中,在线程块大小相同的情况下,使用双三次插值法进行灰度重采样时算法加速比最高;在重采样方法相同的情况下,当GPU线程块大小设置为256或512时,算法执行时间最短、效率最优。进行配置选择和存储层次性访问优化后,算法执行时间进一步缩短。当使用双三次插值法作为重采样方法时,最高加速比可以达到110倍以上,相应的处理时间压缩至5 s以内,可以满足在应急应用领域中对海量数据光学卫星遥感影像进行快速正射校正的要求。
由于GPU集群的出现,多片GPU通过访问互连的方式共同完成某一数据处理任务逐渐成为研究热点,下一步可研究在多片GPU上共同完成正射校正的粗粒度分布式并行算法,进一步提高海量数据光学卫星遥感影像正射校正的效率;并探索通过其余载荷(如SAR、LiDAR等)获取的遥感数据在GPU上进行正射校正的方法。
| [1] | JIANG Yanhuang, YANG Xuejun, YI Huizhan. Parallel Algorithm of Geometrical Correction for Satellite Images[J]. Chinese Journal of Computers, 2004, 27(7): 944-951. (蒋艳凰,杨学军,易会战. 卫星遥感图像并行几何校正算法研究[J]. )计算机学报,2004, 27(7): 944-951. |
| [2] | XIAO Han, ZHANG Zuxun. Parallel Image Matching Algorithm Based on GPGPU [J]. Acta Geodaetica et Cartographica Sinica, 2010, 39(1): 46-51. (肖汉,张祖勋. 基于GPGPU的并行影像匹配算法 [J]. 测绘学报,2010, 39(1): 46-51.) |
| [3] | FANG Xudong.CPU-GPU Heterogeneous Parallel Technology: Oriented on Large Scale Scientific Calculation[D]. Changsha: The National University of Defense Technology, 2009. (方旭东. 面向大规模科学计算的CPU-GPU异构并行技术研究[D]. 长沙:国防科学技术大学,2009.) |
| [4] | YANG Jingyu, ZHANG Yongsheng, LI Zhengguo, et al. GPU-CPU Cooperate Processing of RS Image Ortho-rectification[J]. Geomatics and Information Science of Wuhan University, 2011, 36(9): 1043-1046. (杨靖宇,张永生,李正国,等. 遥感影像正射纠正的GPU-CPU协同处理研究[J]. 武汉大学学报: 信息科学版,2011, 36(9): 1043-1046.) |
| [5] | YANG Jingyu. Study on Parallel Processing Technologies of Photogrammetry Data Based on GPU[D]. Zhengzhou: Information Engineering University, 2011. (杨靖宇. 摄影测量数据GPU并行处理若干关键技术研究[D]. 郑州:信息工程大学,2011.) |
| [6] | CHEN Chao, CHEN Bin, MENG Jianpin. Geometric Correction of Remote Sensing Images Based on Graphic Processing Unit[J]. Command Information System and Technology, 2012, 3(1): 76-80. (陈超,陈彬,孟剑萍. 基于GPU大规模遥感图像的几何校正[J]. 指挥信息系统与技术,2012, 3(1): 76-80.) |
| [7] | HOU Yi, SHEN Yannan, WANG Ruisuo, et al. The Discussion of GPU-based Digital Differential Rectification[J]. Modern Surveying and Mapping, 2009, 32(3): 10-12. (侯毅,沈彦男,王睿索,等.基于GPU的数字影像的正射纠正技术的研究[J]. 现代测绘,2009, 32(3): 10-12.) |
| [8] | FANG Liuyang, WANG Mi, LI Deren, et al. Research on GPU-based Real-time MTF Compensation Algorithm[C]// Proceedings of The 2011 International Symposium on Image and Data Fusion.Tengchong: IEEE, 2011. |
| [9] | CIZNICKI M, KIERZYNKA M, KOPTA P, et al. Benchmarking Data and Compute Intensive Applications on Modern CPU and GPU Architectures [J]. Procedia Computer Science, 2012,12: 1900-1909. |
| [10] | YANG Jingyu, ZHANG Yongsheng, ZHANG Honglan, et al. Remote Sensing Image Parallel Processing Based on GPU[J]. Engineering of Surveying and Mapping, 2008, 17(3): 22-27. (杨靖宇,张永生,张宏兰,等. 基于可编程图形硬件的遥感影像并行处理研究 [J]. 测绘工程,2008, 17(3): 22-27.) |
| [11] | SUI H, PENG F F, XU C, et al. GPU-accelerated MRF Segmentation Algorithm for SAR Images[J]. Computers & Geosciences, 2012, 43: 159-166. |
| [12] | XU Xuegui, ZHANG Qing. Efficiently Processing Parallel Remote Sensing Imagery Using CUDA[J]. Geospatial Information, 2011, 9(6): 47-53. (许雪贵,张清. 基于CUDA的高效并行遥感影像处理 [J]. 地理空间信息,2011, 9(6): 47-53.) |
| [13] | KIRK D B, HWU W M W. Programming Massively Parallel Processors[M]. Amsterdam: Elsevier, 2010. |
| [14] | ZHANG Shu, CHU Yanli. GPU High Performance Computing: CUDA[M]. Beijing: China Waterpower Press, 2009. (张舒,褚艳利. GPU 高性能运算之CUDA [M]. 北京: 中国水利水电出版社, 2009.) |
| [15] | ZHAO Jin. Study of Remote Sensing Image Parallel Processing Algorithms Based on GPU and Optimization Techniques[D]. Changsha: The National University of Defense Technology, 2011. (赵进. 基于GPU的遥感图像并行处理算法及其优化技术研究[D]. 长沙:国防科学技术大学,2011.) |
| [16] | LU Fengshun, SONG Junqiang, YIN Fukang, et al. Survey of CPU/GPU Synergetic Parallel Computing[J]. Computer Science, 2011, 38(3): 5-10. (卢风顺,宋君强,银福康,等. CPU/GPU协同并行技术研究综述[J]. 计算机科学,2011, 38(3): 5-10.) |
| [17] | ZHANG Guo, LI Deren. The Algorithm of Computation RPC Model’s Parameters for Satellite Imagery[J]. Journal of Image and Graphics, 2007, 12(12): 2080-2088. (张过,李德仁. 卫星遥感影像RPC参数求解算法研究 [J]. 中国图象图形学报,2007,12(12): 2080-2088.) |
| [18] | ZHU Xiaoyong, ZHANG Guo, QIN Xuwen. The Formulation of RPC for Domestic Optical Satellite Imagery[J]. Remote Sensing for Land & Resources, 2011, 21(2): 32-34. (祝小勇,张过,秦绪文. 国产光学卫星影像RPC制作[J]. 国土资源遥感,2011, 21(2): 32-34.) |
| [19] | ZHANG Guo, LI Fangting, JIANG Wanshou, et al. Study of Three-dimensional Geometric Model and Orientation Algorithms for Systemic Geometric Correction Product of Push-broom Optical Satellite Image[J]. Acta Geodaetica et Cartographica Sinica, 2010, 39(1): 34-38. (张过,厉芳婷,江万寿,等. 推扫式光学卫星影像系统几何校正产品的3维几何模型及定向算法研究[J]. 测绘学报,2010, 39(1): 34-38.) |
| [20] | LI Deren, WANG Shugen, ZHOU Yueqin. An Introduction to Photogrammetry and Remote Sensing[M]. 2nd ed. Beijing: Surveying and Mapping Press, 2008. (李德仁,王树根,周月琴. 摄影测量与遥感概论[M]. 第 2版. 北京: 测绘出版社, 2008.) |
| [21] | ZOU Xiancai, LI Jiancheng, WANG Haihong, et al. Application of Parallel Computing with OpenMP in Data Processing for Satellite Gravity[J]. Acta Geodaetica et Cartographica Sinica, 2010, 39(6): 636-641. (邹贤才,李建成,汪海洪,等. OpenMP并行计算在卫星重力数据处理中的应用[J]. 测绘学报,2010, 39(6): 636-641) |