


2. 地理国情监测国家测绘地理信息局工程技术研究中心, 陕西 西安 710054;
3. 西安国际港务区规划局, 陕西 西安 710026;
4. 咸阳职业技术学院, 陕西 咸阳 712000
2. Engineering Research Center, Geographical Conditions Monitoring National Administration of Surveying, Mapping and Geoinformation, Xi'an 710054, China;
3. Planning Bureau, Xi'an International Trade and Logistics Park, Xi'an 710026, China;
4. Xianyang Vocational Technical College, Xianyang 712000, China
随着遥感技术的发展,利用遥感影像提取水体信息是进行水资源调查和监测的重要手段和方法。水体提取的方法较多:基于影像光谱特征的提取方法,如毕海芸等[1]利用的单波段阈值法、基于阈值的多波段谱间关系法、基于阈值的水体指数法等;基于影像纹理特征的提取方法, 如李小涛等[2]利用变差函数来描述影像的纹理特征,根据水体的纹理特征对水体进行提取;还有一类综合考虑影像的光谱特征、空间特征和纹理特征的面向对象的提取方法,如殷亚秋等[3]把影像分割成不同的对象,利用影像的光谱信息和空间信息,在对象层次上进行水体的提取。
近年来,随着人工智能、大数据、机器学习技术的发展,一些新型目标提取算法和技术不断出现,基于全卷积神经网络(FCN)的遥感影像水体的提取就是其中之一。卷积神经网络(CNN)[4]的优点在于其多层结构能自动学习的特征,并且可以学习到多个层次的特征;较浅的卷积神经网络感知域较小,可以学习到一些局部区域的特征,较深的卷积层具有较大的感知域,能够学习到更加抽象的特征。目前, 卷积神经网络不仅在全图式的分类上有所提高[5-7], 也在局部任务上, 如目标检测上取得了进步[8-11]。
本文提出的全卷积神经网络算法用于水体目标提取,可以从抽象的特征中恢复出每个像素所属的类别,使从图像级别的分类进一步延伸到像素级别的分类。因此,本文提出的算法相对于传统的目标提取算法有更高的可信度和稳健性。
1 全卷积神经网络的基本原理卷积神经网络是包含卷积层的深度神经网络模型。卷积神经网络模型较多,经典的模型有2012年ImageNet比赛冠军的模型AlexNet[5]、2014年ImageNet竞赛的双雄VGG[6]模型和GoogleNet模型[7]。这些典型的CNN模型中,开始几层都是卷积层(CONV)和池化层(pool,即下采样)的交替,然后在最后一些层(靠近输出层)则是全连接(FC)的一维网络,这样将卷积层产生的特征图就映射成一个固定长度的特征向量。这些典型CNN结构适合于图像级的分类和回归任务。由于最后得到的是整个输入图像的一个数值描述的概率值,它会将原来二维的矩阵(图像)压扁成一维的,从而使后半段没有空间信息。那么, 如何从抽象的特征中恢复出每个像素的所属类别,即从图像级别的分类进一步延伸到像素级别的分类,Jonathan Long等提出了全卷积神经网络(FCN)[12]。
FCN模型将传统的CNN模型的全连接层转化成一个个卷积层,这样所有的层都是卷积层,故称为全卷积网络。FCN的构建包括卷积化、上采样(反卷积)和跳层结构。
1.1 卷积化卷积化即将传统的CNN全连接层转化成一个个卷积层,输出低分辨率的分割图像。如图 1所示,以AlexNet模型为例。

|
| 图 1 卷积神经网络构建全卷积神经网络示意图 |
图 1中,CONV1—CONV5为卷积层,同时每层下采样,图像尺寸每层降2倍,全连接层FC6、FC7、FC8分别进行了1×1的卷积,卷积化后的核尺寸(通道数、宽、高)分别变为(4096, 1, 1)、(4096, 1, 1)和(类别数N,1, 1)。
在卷积神经网络中,卷积计算需要矩阵化[13],若卷积参数输入为4×4图像,输出为2×2图像,卷积核尺寸为3×3,边界填充补零为0,步长为1。则矩阵乘就是将输入展开为16维向量x,输出展开为4维向量y,则卷积计算公式如下
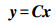 (1)
(1) 变换后的稀疏阵C由卷积核C′变换而来,C和C′的表达式如下


通过式(1)即可以进行卷积计算。
1.2 上采样(反卷积)由于卷积化后输出的为低分辨率的图像,前五卷积层降采样下降32倍,为了解决低分辨率的问题,将低分辨率图像进行上采样,输出同分辨率的分割图像。上采样的方法选用双线性插值反卷积[14]计算。图 2为上采样示意图。

|
| 图 2 上采样示意图 |
与卷积化一样,反卷积操作也需要矩阵化,若卷积参数输入为2×2图像,输出为4×4图像,卷积核尺寸为3×3,边界填充补零为2,步长为1,则矩阵乘就是输出展开为4维的向量y,输入展开为16维的向量x,反卷积计算公式如下
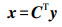 (2)
(2) 由于从32倍下采样的图像直接上采样插值到原始图像大小,信息量损失较大,结果较粗糙,只能表示出对象的大致形状。为了解决这个问题,本文提出跳层结构,以精化分割提取的图像。
3种模型的构建如图 3所示。第1种模型是FCN-32s,是在第7卷积层(CONV7)后直接采用上采样32倍的结果;第2种模型是FCN-16s,是在第4池化层(pool4)后增一个1×1的卷积层,同时把第7层上采样2倍,再将二者融合。融合方法是直接进行矩阵对应位置相加,然后对融合的结果Sum(1)进行16倍的上采样,获得FCN-16模型;第3种模型是FCN-8s,是在第3池化层(pool3)后增加一个1×1的卷积层,同时对Sum(1)进行2倍上采样,二者再进行融合得到Sum(2),对Sum(2)再进行8倍上采样获得FCN-8s模型。

|
| 图 3 FCN 3种模型的构建 |
本文选用VGG16为基本网络模型来构建FCN模型,使用VGG16作为初始网络,保留参数;舍弃最后的2个全连接层换为全卷积层,同时追加一个预测卷积层,按照跳层结构的原理,分别构建出FCN-32s网络模型、FCN-16s网络模型和FCN-8s网络模型。
本文的试验数据包括训练数据和测试数据。训练数据是从遥感影像中裁剪出带有水体的187幅约为500×500像素大小的影像,分辨率约为4 m,为了增加样本量,进行90°、180°、270°旋转,总共获取748幅影像;同时对这748幅影像的水体进行标注,除水体外其他标注为背景,共两类目标,作为标签数据;然后对748幅影像数据和标签数据的70%作为训练集,30%作为验证集,引入VGG16构建的FCN-32s、FCN-16s和FCN-8s网络模型,进行推理和学习,通过参数微调,获取3种先验模型,迭代次数均为50 000次。
测试数据是在遥感地图上裁剪的2幅图像,这两幅图像与训练数据来自不同区域。一幅背景较简单,水体形状比较规则;另外一幅背景比较复杂,水体形状不规则,如图 4(a)所示。

|
| 图 4 几种方法试验结果 |
全卷积神经网络由前文直接获取的3种先验模型进行测试;阈值法的阈值通过随机在水体区域选取分布均匀的15个点,确定出阈值的范围进行水体提取;Grabcut[15]通过人机交互界面粗略地画出前景和背景线,来自动构建高斯混合模型,进行水体提取。几种方法提取结果如图 4所示。
图 4所列为试验结果,其中图 4(a)为原始影像,图 4(b)为人工判读的结果,作为理想的水体区域参考值,图 4(c)为阈值法结果,虽然能提取出水体,速度比较快,方法简单,但是噪声比较多, 边缘也不是特别明显。另外不同的影像阈值是不固定的,每幅影像要重新选择阈值, 通用性差。图 4(d)和(e)均为全卷积神经网络提取水体,选择FCN8s和FCN32s两种模型的测试结果,可以看出FCN8s提取的边界更清晰,提取得更精细一些,而FCN32s提取结果虽然位置正确,但是比较粗略。图 4(f)为GrabCut提取结果,GrabCut对背景简单的提取效果比对背景复杂的要好,但是在提取时需要人工交互选取前景和背景,工作量大,泛化能力较差,精度也不是很高,漏掉的比较多,对于水体提取,该方法还需要改进。因此,全卷积神经网络尤其是FCN8s模型提取水体自动化程度高,效果较好。
4 结论与展望本文提出了一种全卷积神经网络模型用于水体目标提取的方法,通过3种模型FCN32s、FCN16s和FCN8s,对遥感影像上的水体目标进行分割提取试验,通过与传统的阈值法和基于图论的GrabCut算法提取水体对比,全卷积神经网络的FCN8s模型提取结果稳健性较强,泛化能力较好。
随着人工智能和大数据的崛起,若能利用遥感影像的高光谱数据的特征,并增加基础地理信息的面状和线状地图信息,构成大数据进行训练,笔者相信深度卷积神经网络将在测绘遥感领域发挥出更大的优势。
| [1] | 毕海芸, 王思远, 曾江源, 等. 基于TM影像的几种常用水体提取方法的比较和分析[J]. 遥感信息, 2012, 27(5): 77–82. |
| [2] | 李小涛, 黄诗峰, 郭怀轩. 基于纹理特征的SPOT5影像水体体取方法研究[J]. 人民黄河, 2010, 32(12): 5–6. DOI:10.3969/j.issn.1000-1379.2010.12.002 |
| [3] | 殷亚秋, 李家国, 余涛, 等. 基于高分辨率遥感影像的面向对象水体提取方法研究[J]. 测绘通报, 2015(1): 81–85. |
| [4] | 吴岸城. 神经网络与深度学习[M]. 北京: 电子工业出版社, 2016. |
| [5] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]//International Conference on Neural Information Processing Systems. Nevada: Curran Associates Inc, 2012: 1097-1105. |
| [6] | SIMONYAN K, ZISSERMAN A. Very Deep Convolutional Networks for Large-scale Image Recognition[J]. Computer Science, 2014(9): 1409–1456. |
| [7] | SZEGEDY C, LIU W, JIA Y, et al. Going Deeper with Convolutions[C]//IEEE Conference on Computer Vision and Pattern Recognition. Santiago: IEEE Computer Society, 2015: 1-9. |
| [8] | GIRSHICK R, DONAHUE J, DARREL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. Computer Science, 2013(6): 580–587. |
| [9] | GIRSHICK R. Fast R-CNN[C]//International Conference on Computer Vision. Santiago: IEEE, 2015: 1440-1448. |
| [10] | REN S, HE K, GIRSHICK R, et al. Faster R-CNN:Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137–1149. DOI:10.1109/TPAMI.2016.2577031 |
| [11] | HE K, ZHANG X, REN S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904–1916. DOI:10.1109/TPAMI.2015.2389824 |
| [12] | LONG J, SHELHAMER E, DARREL T. Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(4): 640–651. DOI:10.1109/TPAMI.2016.2572683 |
| [13] | DUMOULIN V, VISIN F. A Guide to Convolution Arithmetic for Deep Learning[J]. Stat, 2016, 1050: 23. |
| [14] | ZEILER M D, FERGUS R. Visualizing and Understanding Convolutional Networks[C]//European Conference on Computer Vision. Zurich: Springer, 2014: 818-833. |
| [15] | ROTHER C, KOLMOGOROV V, BLAKE A. "GrabCut":Interactive Foreground Extraction Using Iterated Graph Cuts[J]. IEEE Transactions on Graphics, 2004, 23(3): 309–314. DOI:10.1145/1015706 |
| [16] | GARCIAGARCIA A, ORTSESCOLANO S, OPREA S, et al. A Review on Deep Learning Techniques Applied to Semantic Segmentation[J]. Computer Science, 2017(4): 1704. |