



2. 西南林业大学林学院, 云南 昆明 650224;
3. 中国林业科学研究院资源信息研究所, 北京 100091
2. College of Forestry, Southwest Forestry University, Kunming 650224, China;
3. Research Institute of Forestry Resource Information Techniques, CAF, Beijing 100091, China
DEM描述地面高程信息,它在工程勘测设计、土地利用、地理信息、林业等领域有着广泛的应用。DEM精度的好坏直接关系到应用结果的可靠性[1-2],因此,获得高质量的DEM有着非常重要的意义。DSM包含地物的轮廓和高程信息[3],因此可以由DSM通过分割和插值得到DEM。李忠等[4]利用附近最小值方法,从平坦地区的DSM中提取出DEM,通过10个检查点计算出试验结果的中误差为3.51 m;其中10个检查点中,结果与实际参考值相差小于2 m的点只有3个。Ismail等[5]探究了附近最小值法中,滤波窗口大小和DSM分辨率对DEM提取精度的影响,试验结果表明:窗口尺寸太小则无法对大型建筑物等非地面点进行有效滤除,而尺寸太大会导致部分地面点被滤除,不容易确定最佳滤波尺寸;DSM的分辨率越高效果越好,当分辨率低于1 m时,随着分辨率的继续降低,得到的DEM的精度也随之快速下降。由于该方法采用窗口中最小值作为判断条件,当窗口位于山区、丘陵等地形复杂地区时,窗口中较高地面的高程值与最小值之间的差值很容易超过设定的阈值,致使产生错误的判断,因此该方法只能用于较平坦的区域。
区域生长是一种重要的图像串行区域分割算法,其关键因素包括初始种子点的选取、生长准测和终止条件[6-7],并且直接影响图像分割效果[8]。在生长算法的基础上,许多研究者提出了扩展算法。Pohle等[9]把待分割图像的像素值看作正态分布,先用原始区域生长算法估算出分布参数,再将该参数应用到第二遍生长过程中,从而获得更好的结果。Zheng等[10]将区域生长算法和各向异性滤波技术结合,提出了一种无需种子点的自动分割算法,克服多数区域生长算法对初始种子点的选取顺序和位置敏感的问题。无论是地形平坦地区,还是复杂地区,DSM数据中地面点之间都存在连续性和空间相关性[11]。区域生长算法具有能将连续相似性质的像素集进行合并的特性[12],可以把连续的地面点结合成区,因此可以应用区域生长算法识别地面点和提取DEM。
本文采用区域生长算法和最大类间方差法实现自动选取种子点,以及生长准则和终止条件的自适应选择,增强了算法的适用性,去除了地形条件对算法的限制,实现从平坦地区和地形复杂山区的DSM中识别地面点和提取DEM。
1 基于区域生长的DEM提取算法不管是平坦地区还是地形复杂的山区,在全局上,DSM数据的地面点之间都表现出较好的连续性,建筑物、树等其他地物与其周围的地面点之间存在较大的跳跃。虽然在局部存在一定的阶跃性,特别是在地形复杂的山区,但相邻地面点之间还具有一定的连续性。因此,利用区域生长算法能够把邻近相似的像素点结合成区域的这一特性,可从DSM中有效识别地面点,如图 1所示。

|
| 图 1 算法流程 |
由图 1可以看出,先采用区域生长算法和最大类间方差法获得DSM中的地面点,然后以八邻域插值的方法对非地面点进行插值,得到完整的DEM。由于高架道路的起点是附着于地面,而后抬升,在DSM数据中与地面点之间存在很好的连续性。但高架路的主要部分又高于地面点,具有房屋等建筑的特征,若仅用生长运算1,会导致高架道路被错误识别到地面点集G中,最终产生错误的DEM。因此,当DSM中存在高架道路时需要调用模块1;如不存在,则不需要。
1.1 种子点的自动选取以正方形窗口W不重复地连续遍历DSM数据,窗口W的大小取DSM中非地面地物的平均尺寸,如50×50。窗口W中满足式(1)的像素点为种子点,但窗口W可能全部落在某一建筑物上或平坦的地面处。若是前者,则不能在其中取种子点。若是后者,则没必要有种子点,因其是相对平坦的地面,它与其周围窗口必然有一个平滑衔接,因此可以被周围窗口中地面像素点的生长运算过程所识别出来。这两种情况有一个共同特征,即当前窗口W的标准方差较小,因此算法中要求窗口W的标准方差大于整个DSM数据的标准方差的0.6倍时,才在W中寻找种子点,以避免前一种情况下产生的错误。
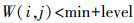 (1)
(1) 式中,W(i, j)为窗口中位于(i, j)的像素点;min为当前窗口W中的最小值;level公式如下
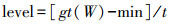 (2)
(2) 式中,gt(W)为窗口W中最大类间方差法对应的阈值;t为常数系数,根据原始数据的标准方差取值,标准方差越大,对应取值也越大,取值范围在10~20之间效果较好。level随着不同窗口中gt(W)的变化发生变化。当窗口W中数据的值和值域较大时,表示地形起伏大,即当前窗口位于地形复杂的山区或丘陵,此时gt(W)的取值较大,level随之取到较大值,在保证种子点质量的同时,获得尽可能多的种子点,以提高算法的识别和插值效果。因此,在DSM数据处理中,地形平坦和地形复杂的部分都能自动找到较合适的阈值level,实现种子点的自适应选取。
1.2 生长准则和终止条件的自适应取值种子点基础上的生长过程是在整个DSM数据中完成的,生长准则和终止条件如下
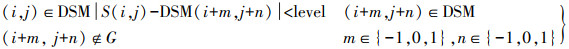 (3)
(3) 式中,S(i, j)为种子点或生长过程中新识别出来的地面点;level与式(2)中相同;G为已经识别出的地面点集。种子点位于平坦位置时,与周围地面点之间的差值相对较小,此时应该取相应较小的level作为生长准则和终止条件的限制阈值。当种子点位于起伏较大的复杂地形时,与周围地面点之间的差值变大,此时level需要相应取较大的值。式(2)使level随地形起伏程度自动取值,最终实现平坦和复杂地形下生长准则和终止条件的自适应取值。
1.3 城区高架道路识别在已识别出来的点集G的基础上再应用一次生长算法。区别在于上次以窗口中较小值为种子点,这次以窗口中较大值为种子点,且适当缩小窗口大小,当前窗口W′取前一次运算窗口大小的0.5~0.6倍,以使同一窗口中地形变化小,尽可能使高架道路和地面点之间的差异才是窗口中的主要差异。另外,此次生长过程不直接采用原始DSM,而采用对DSM进行中值滤波和开运算后的DSM′,避免异常值的影响,同时去掉细小突出部分,平滑各个地物轮廓,以增强识别结果的整体性。当窗口W′的标准方差大于整个DSM′数据的标准方差的0.6倍时,满足式(4),则判断为种子点;在相对平坦的城区DSM中,满足这两个条件的点就是高架道路的种子点。
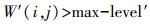 (4)
(4) 式中,W′(i, j)为窗口中位于(i, j)的像素点;max为当前窗口W′中的最大值;level′公式如下
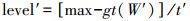 (5)
(5) 式中,gt(W′)为窗口W′中最大类间方差法对应的阈值;t′为常数系数,与式(2)的含义一致,只是具体取值不一。
种子点基础上的生长过程是在整个点集G中完成的,生长准则和终止条件如下
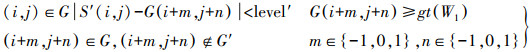 (6)
(6) 式中,S′(i, j)为种子点或生长过程中新识别出来的地面点;level′与式(5)中相同;G为已经识别出的地面点集;G′为识别出的高架道路点集;gt(W1)为窗口W1中最大类间方差法对应的阈值;W1是以当前待判断点为中心的活动窗口,其大小是式(1)中窗口W的一半或更小,以使窗口W1在检测高架道路过程中,尽可能只包含DSM′中的公路和地面信息。生长准则和终止条件(式(6)与式(3))的不同在于多了一个限制条件:G(i+m, j+n)≥gt(W1)。后一次生长过程是由大值开始,即从高架道路的种子点开始;而在生长过程中,当点(i+m, j+n)小于以点(i, j)为中心的窗口W1的最大类间方差法对应的阈值时,则说明点(i+m, j+n)不属于高架道路一类,因此终止。
1.4 插值在地面点集G(如有高架道路,则G需要减去G′)的基础上,对非地面待插值的点采用八邻域中有效值点的均值,一定程度上保持DEM结果的连续性。对于个别八邻域中没有有效值点的点,用相应窗口W中地面点的平均值给其赋值。
2 试验结果与分析 2.1 试验数据文中用到两组试验验证数据,一组是地形复杂的山区DSM,原始数据由中国林业科学研究院资源信息所机载LiCHy系统于2014年4月获取,LiCHy系统包括CCD相机、激光雷达传感器和AISA Eagle Ⅱ高光谱传感器[13]。试验中所用DSM数据由其激光雷达的点云数据通过ENVI LiDAR处理而来,图像大小为300×300像素,分辨率为1 m。影像区域地形复杂,起伏大,呈现中间和左上方地势低,右方和下方地势较高,主要有建筑物、植被、道路等地物。
另一组是2013年电气和电子工程师协会地球科学与遥感学会(IEEE GRSS)数据融合大赛数据,原始数据包括机载高光谱影像、机载LiDAR数据和分类结果检验数据,获取于2012年6月,覆盖美国休斯敦大学及附近居民区,由IEEE GRSS提供[14]。高光谱影像的中心波长为364~1046 nm,波段数为144个,空间分辨率为2.5 m。机载LiDAR点云数据地面分辨率同为2.5 m,且两者相互配准并有相同的覆盖区域[15]。同样通过ENVI LiDAR处理得到试验中所用DSM数据,大小为1905×349像素,分辨率为2.5 m。分类结果检验数据共有15类地物。影像中地物种类较多,包括商用房屋、民用房屋、道路、树等,但整体地势平坦。本试验以比赛结果检验数据中健康的草、假草、土壤、水、道路、地面停车场、网球场、跑道作为地面点的检验数据,以比赛结果检验数据中树、居民区、商业区,以及高架高速公路作为非地面点的检验数据。
2.2 评价方法采用目视解译、混淆矩阵和制图精度评价的方法,对本文算法与附近最小值法在识别地面点和提取DEM的精度及可靠性进行比较分析。
2.3 试验结果试验结果如图 2和图 3所示。为了方便视觉比较,高光谱影像为真彩色显示,并作5%拉伸,灰度图像为线性拉伸显示,试验参数设置详见表 1。

|
| 图 2 复杂地形的DSM数据试验 |

|
| 图 3 平坦城区的DSM数据试验 |
| 试验组别 | 本文方法 | 附近最小值法 | ||||||
| 窗口W | 系数t | 窗口W′ | 系数t′ | W1 | 窗口W | 系数t | ||
| 数据一 | 50×50 | 12 | — | — | — | 15×15 | 2.5 | |
| 数据二 | 50×50 | 20 | 30×30 | 12 | 25×25 | 30×30 | 8 | |
从目视效果来说,图 2中本文方法的识别结果明显好于附近最小值法,基本实现了所有地面点的正确识别。对比提取的DEM结果,附近最小值法的结果只能反映整体地形走势,而本文方法很好地保留了梯田等细节信息,效果明显好于附近最小值法。同样的,图 3中本文方法的识别结果明显优于附近最小值法,本文方法提取的DEM也较好。但从结果(图 3(h))中还能较明显看出原来建筑物的痕迹,其原因有两个:①多数建筑地基部分会比周围地面稍高,因此在DEM结果中,原建筑物位置处的值会大于周围地面;特别是整个数据的地形平坦,并对DEM结果进行了线性拉伸显示,扩大了这一细微差异,但不是错误。②如图 3(h)中Ⅲ处,虽然实现了正确识别,但由于插值过程采用的是八邻域的均值,导致在微地貌区域插值效果不理想[16],存在与周围有明显差异的人为痕迹。从图 3(e)可以看出,本文方法很好地识别出了高架道路,防止了因采用区域生长算法而把高架道路分割到地面,并且避免了Liao等[14]在2013年数据融合大赛把图中Ⅰ的高架高速公路错分到商业区的错误。结果(图 3(e))中区域Ⅱ存在一个明显错误。根据本文算法原理及通过观察对应位置DSM可知,这一错误是由于本文算法采用的DSM数据只反映地物高程信息,而图中Ⅱ的建筑物(高架高速公路)、植物及地面三者之间在DSM上存在较好连续性,难以区分。如果结合植被指数(NDVI)作为辅助分析数据,则可避免这一错误。试验效果如图 4所示,基本正确识别出了DSM中全部高架道路。

|
| 图 4 结合NDVI后的效果 |
利用混淆矩阵和制图精度质量评价指标进行定量评价,统计结果见表 2和表 3。由于识别的结果只有地面点和非地面点两类,因此不能单从地面点或非地面点的制图精度来评价方法优劣,而应该兼顾两类的精度。对于地形复杂的山区DSM数据,获取的地面点数量越多,质量越高,得到的DEM结果越好。从表 3中可以看出,本文方法的精度都优于附近最小值法,精度都超过90%,是本文方法识别地面点和提取DEM效果好的直接体现。
本文算法对地形平坦地区和复杂地形的山区都能提取到质量较好的DEM,但还存在两个局限性:①本算法不适合含有郁闭度非常高的林区的DSM数据。在算法运算中,针对林区部分的DSM数据难以识别出足够多的地面点,插值结果存在明显人为痕迹,增加了DEM结果的误差。尤其是当郁闭度高的林区位于地形复杂的山区时,不能提取出足够多有效反映地形变化的地面点,致使DEM结果误差更大。②本算法要求DSM数据中必须包含高架道路附着于地面的起点部分,才能正确识别高架道路。原因在于识别高架道路是基于其的两个属性:起点部分附着于地面,中间主要部分高于地面。
3 结语本文将最大类间方差法和区域生长算法结合,运用中值滤波和开运算减少噪声和局部极值对结果的影响,增强分割结果的整体性,实现了图像分割过程中的种子点、生长准则和终止条件的自适应选择,从平坦地区和地形复杂的山区DSM中识别地面点和提取DEM。此外,本算法使用两次区域生长算法实现高架道路的识别。试验结果及评价指标表明,本算法能够有效提高DEM的提取精度。
在后期工作中,针对本文算法局限性①,采用连续性更好的插值方法替代八邻域插值,如双三次插值法,改善林区部分的插值效果;同时,尝试对式②的常系数t做到自适应取值,从而进一步增强算法的自适应能力和适用范围。
| [1] | 雷蓉, 邱振戈, 张士涛. 基于遥感影像生成DEM的质量检查[J]. 测绘通报, 2005(4): 36–39. |
| [2] | 汤博麟, 蔡海峰, 牟玉兴. DEM制作检查及精度问题的解决方法[J]. 地理空间信息, 2016, 10(6): 76–78. |
| [3] | 马红. 利用高精度DSM数据提取建筑物轮廓算法研究[J]. 测绘通报, 2015(4): 111–124. |
| [4] | 李忠, 李梅, 杜绪奎. 平坦地区DSM到DEM的试验[J]. 测绘与空间地理信息, 2008, 31(2): 29–31. |
| [5] | ISMAIL Z, JAAFAR J. DEM Derived from Photogram-metric Generated DSM Using Morphological Filter[C]//Control and System Graduate Research Colloquium. [S. l. ]: IEEE, 2013. |
| [6] | 徐海荣, 田联房, 陈萍, 等. 改进的区域生长算法在医学图像分割中的应用[J]. 生物医学工程研究, 2005, 24(3): 187–190. |
| [7] | 林瑶, 田捷. 医学图像分割方法综述[J]. 模式识别与人工智能, 2002, 15(2): 192–204. |
| [8] | KAMDI S, KRISHNA R K. Image Segmentation and Region Growing Algorithm[J]. International Journal of Computer Technology & Electronics Engineering, 2012, 1(2): 103–107. |
| [9] | POHLE R, TOENNIES KD. A New Approach for Model-based Adaptive Region Growing in Medical Image Analysis[M]. Berlin Heidelberg: Springer, 2001: 238-246. |
| [10] | LIN Z, JIN J, TALBOT H. Unseeded Region Growing for 3D Image Segmentation[J]. Journal of Trauma, 2000, 24(11): 938–945. |
| [11] | 朱绍攀, 张书毕. 分形地形复杂度研究[J]. 地理空间信息, 2011, 9(3): 116–119. |
| [12] | 苏明超, 郭书军. 基于区域生长算法的CT图像肺组织分割[C]//中国电子学会全国网络编码学术年会论文集. 北京: 国防工业出版社, 2008. |
| [13] | 刘怡君, 庞勇, 廖声熙, 等. 机载LiDAR和高光谱融合实现普洱山区树种分类[J]. 林业科学研究, 2016, 29(3): 407–412. |
| [14] | LIAO W, PIŽURICA A, BELLENS R, et al. Generalized Graph-based Fusion of Hyperspectral and LiDAR Data Using Morphological Features[J]. IEEE Geoscience & Remote Sensing Letters, 2015, 12(3): 552–556. |
| [15] | 董彦芳, 庞勇, 许丽娜, 等. 高光谱遥感影像与机载LiDAR数据融合的地物提取方法研究[J]. 遥感信息, 2014(6): 73–76. |
| [16] | 彭仪普, 刘文熙. 实时交互的多分辨率地形模型[J]. 武汉大学学报(信息科学版), 2003, 28(4): 480–483. |