


2. 武汉大学测绘遥感信息工程国家重点实验室, 湖北 武汉 430079;
3. 德州农工大学科普斯分校地理空间计算实验室, 美国 德州 科普斯 TX78412
2. State Key Labortatory of Information Engnineering in Surveying, Mapping, and Remote Sensing, Wuhan University, Wuhan 430079, China;
3. Conrad Blucher Institute for Surveying & Science, Texas A & M University Corpus Christi, Corpus Christi, TX 78412 USA
智能手机以其出色的用户体验、低廉的价格、日益丰富的传感器系统(如GNSS接收机、加速度计、陀螺仪、磁力计、气压计等),以及持续增强的运算和续航能力,已经成为无缝运算和智能服务的理想平台,而基于智能手机平台的活动识别[1-2],则是提供智能服务的重要研究内容。一般情况下,该研究的处理过程主要包括传感器原始数据收集、数据预处理、特征提取、模型训练和学习、模型测试或活动识别等步骤[3]。其中,特征提取是对预处理后的数据进行特征计算,主要是提取统计特征或结构特征。由于智能手机用户的情境特征信息与用户的时间、空间及环境特征高度相关,陈锐志等将用户所处在的情境环境信息归纳为时间情境、空间情境、时空情境和用户情境等多维情境特征,提出了一种新的特征提取框架,并基于上述框架,利用朴素贝叶斯分类器,对复杂的人类活动进行识别[4]。
近年来,在一般的特征提取方式下,很多学者利用集成分类器中的随机森林算法进行活动识别研究[5-8]。如Coskun等基于不同放置位置的智能手机加速度计传感器数据,并利用随机森林算法识别人类活动,同时利用识别结果识别手机放置位置和姿态;Dash等在对比多个分类算法后选择随机森林算法进行基于智能手机加速度传感器的活动识别;Guo等提出了一种自学习的方法并将智能手机传感器应用在医疗检测领域中,对病人的活动进行识别,其中已标记活动的分类算法为随机森林算法。周博翔等提出了一种蜜蜂交配优化的随机森林算法,并将该算法应用于基于加速度传感器的人体姿态识别。然而,在多维情境特征框架下,文献[4]仅利用了单一的朴素贝叶斯分类器,其分类精度效果存在局限。为了提升多维情境特征框架下的分类效果,本文拟利用集成分类器中的随机森林算法对提升活动识别精度效果进行研究。
1 多维情境特征框架活动识别技术的系统输入数据是传感器的原始感知数据,系统输出是根据数据识别或识别的相关人类活动。根据对基于智能手机平台人类活动识别的总结,一般的数据处理过程主要包括传感器原始数据收集、数据预处理、特征提取、模型训练和学习、模型测试或活动识别5个步骤,其数据处理步骤如图 1所示。其中,数据收集过程主要是记录不同传感器的离散时间数据;数据预处理主要是去噪和数据分割;特征提取是对已分割的数据进行特征计算,即提取统计特征或结构特征,如提取分割时间段内传感器数据的数字特征(如加速度均值、方差)或频域特征(如频谱特征)等,另外,对冗余特征进行维度约减也是特征提取的一部分,如利用主成分分析、线性判别分析算法进行的降维运算;特征提取后,选择相关数据集,以及相应的机器学习算法并设置参数,进行相应的模型训练和活动识别。

|
| 图 1 基于智能手机平台的人类活动识别数据处理过程 |
如前文所述,一般特征提取方式是对已分割的数据计算统计特征或结构特征,与此不同,文献[4]提出了一种新的特征提取框架,即提取用户的多维情境特征,并基于该框架来识别人类活动。在该框架中,用户所处在的情境环境信息被归纳为时间情境、空间情境、时空情境和用户情境。图 2为多维情境特征人类活动识别框架,其中用户情境用于用户相关的情境信息定义,如用户的移动特征(如静止、走动及开车等)、用户的环境特征(如光照条件、噪声水平及气象条件等)、用户的心理特征(如疲劳程度、激动程度及紧张程度等)和用户的社交特征(如是否正在打电话、发短信等)。为了验证框架的有效性,文献[4]根据校园生活,选择了包括“工作”“开会”“吃饭”“喝咖啡”“等公交”及“上课”的6种活动进行识别,并将未能归类到上述活动的活动归类为“未定义的活动”。

|
| 图 2 多维情境特征人类活动识别框架 |
表 1为文献[4]中各类情境特征的具体描述和量化操作,需要指出的是,时空情境反映了用户在某个位置的停留时长,该特征反映了所在位置的停留时长对活动识别的影响,表中的量化指标是根据经验设定的,同时,用户情境仅参考于用户的运动特征,其量化规则也是根据一般的活动经验来给定。
| 类别 | 描述 |
| 时间情境 | 设置为本地系统时间的小时时间,标记值范围为0~23 |
| 空间情境 | 根据空间位置与空间位置区域关系标记,位置区域按活动定义划分,如文献[4]中为办公室、会议室、餐厅、咖啡厅、公交车站、教室、未定义7类,分别记为0~6 |
| 时空情境 | 为每个已定义的位置区域设置时长缓冲区,根据空间情境对相应缓冲区增加时长,如在办公室则在其缓冲区加1否则加0,再根据每个缓冲区的时长进行累加统计并量化,最终对各位置的时空情境进行标记,其中量化指标为短(1~5 s,记为0)、中(5~15 s,记为1)、长(15~60 s,记为2) |
| 用户情境 | 在文献[4]中仅采用用户的运动特征,根据速度大小量化为静止(<0.1 m/s,记为0)、缓步走(0.1~0.7 m/s,记为1)、走(0.7~1.4 m/s,记为2)、快速移动(>1.4 m/s,记为3) |
在智能手机平台中,上述情境特征以时间序列方式产生,即在每个采样点可获得一个情境数组,定义为:[时间情境,空间情境,时空情境,用户情境]。获得上述情境特征时间序列后,再利用机器学习算法学习特征与活动之间的关系模型,在新数据到达时,即可利用所习得的模型进行活动识别。文献[4]中利用的是机器学习中的朴素贝叶斯算法,即条件概率p(活动|给定情境数组)可由如下公式获得
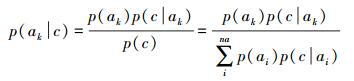 (1)
(1) 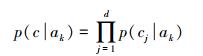 (2)
(2) 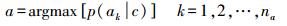 (3)
(3) 式中,a为识别结果;ak为任一定义的活动;na为定义的活动集中的活动数;c为情境特征数组;d为情境特征数组的维度。
文献[4]在朴素贝叶斯算法下对比了多维情境与单维空间情境分类结果,以及经验模型与学习后模型的分类结果,结果表明多维情境特征分类效果优于单维空间情境,学习后模型分类效果也优于仅凭经验设定参数的模型。
2 随机森林算法在活动识别研究中,不同的机器学习算法将对识别效果产生不同的影响,一般研究中采用的是监督学习分类算法,包含两个步骤:学习/训练阶段和识别/测试阶段。学习/训练阶段主要是通过数据获得模型,而一个经过学习获得的模型通常由决策函数y=f(x)或条件概率模型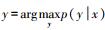
监督学习中的分类算法较多,常用的包括贝叶斯、决策树、支持向量机、对数几率回归、人工神经网络等。为了增强单一分类器的性能,集成多个分类算法的思想被提出,主要思路是利用多个基分类算法进行分类,并综合所有分类结果形成一个最终的结果,这种方式可以提高分类算法的泛化能力,改善分类效果。集成分类算法也包含多种,如装袋(bagging)、提升(boosting)和随机森林。随机决策森林概念于1995年被Tin Kam Ho提出[9],随后他又提出随机子空间的集成方法;而最终的随机森林算法被Leo Breiman在2001年进行了系统的阐述[10],从而正式成为分类算法的重要组成部分,由于其出色的分类性能,已经得到广泛应用,如遥感影像分类[11]。
随机森林算法的计算过程为:先通过bootstrap重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本构造新的训练样本集合;然后根据样本集生成k个决策树,由这些决策树组成随机森林,而新输入数据的分类结果按这些决策树的投票结果而定。其中,在决策树训练过程中进一步引入随机属性选择,传统决策树在选择划分属性时是在当前节点的d个属性中选择一个最优属性;而随机森林中对每个基决策树属性先从d个属性选择一个包含d′个属性的子集,再从该子集中选择一个最优属性,通常d′取值为log2d。随机森林算法通过构造不同的训练集来增加分类模型间的差异,从而提高组合分类模型的外推预测能力,通过k轮训练,算法得到一个分类模型序列
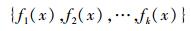 (4)
(4) 由式(4) 序列组成一个分类模型系统,该系统最终的分类结果采用简单多数投票法,即
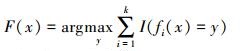 (5)
(5) 式中,F(x)表示组合分类模型;fi(x)是单个决策树分类模型;y表示输出变量;I(x)为示性函数。
随机森林中每一棵树的建立依赖于一个独立样本,每一棵树都具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。单棵树的分类能力可能很小,但在随机产生大量的决策树后,测试样本可以统计每一棵树的分类结果,然后投票选择最可能的分类,从而提升整体的分类能力。
3 试验与结果本文通过独立开发的Android平台应用程序收集数据,该程序可获取传感器源数据,并提取情境特征数据保存至手机本地,最后将数据导入PC计算机进行处理、分析及评价。
图 3为Android应用程序界面截图与该应用程序中各类情境特征的具体获取过程:① 时间情境由系统时钟提供的本地时刻标签标记;② 由于空间情境由用户当前位置及一些与活动相关的位置区域关系构成,因此需要获取用户当前位置并进行判定,其中用户当前位置由基于智能手机多传感器(包括GPS接收机、加速度计、陀螺仪、磁场传感器及WiFi模块)数据和无味卡尔曼滤波(unscented kalman filter,UKF)数据融合算法的实时无缝室内外定位引擎获得,而位置区域包括与用户相关的办公室、会议室或教室等符号位置,它们由地理空间栅栏定义,可以是一个由地理空间位置为圆心的圆或多边形组成的感兴趣区域(region of interest,ROI),如图 3中的线框;③ 时空情境是在上述未知区域中的停留时长,实际操作中由系统时钟针对每一个用户定义的位置区域提供一定长度的时长缓冲区,通过对每个缓冲区计数从而产生各个位置的时空情境数据;④ 用户情境在本文中仅考虑用户的运动状态。

|
| 图 3 数据获取Android应用程序截图与多维情境特征获取过程 |
上述应用程序中,数据更新周期为1 s,即每1 s可获取一组多维情境特征,而活动的真实标记由测试者在应用程序上人为进行标记。试验选取美国德州农工大学科普斯分校校园为试验区域,试验场景为校园生活活动识别,参照文献[4]对活动的选择,对工作、开会、吃饭、喝咖啡、等公交、上课、未定义7类活动展开识别,分别标记为0~6。3位测试者持不同型号的手机参加测试并标记活动,通过一周5个工作日的情境特征数据记录与活动标记,最终获得的数据见表 2。
| 测试者 | 设备型号 | 口袋位置 | 总数据量/条 |
| 1 | Samsung SCH-R970 | 上衣胸前 | 154 084 |
| 2 | Samsung SM-N9008V | 裤子腰部 | 133 962 |
| 3 | Samsung GT-I9502 | 上衣腰部 | 144 525 |
试验采用新西兰怀卡托大学发布的开源数据挖掘和机器学习测试平台Weka[12]进行分析,对比测试了朴素贝叶斯算法和随机森林算法的分类性能,其中随机森林算法中随机生成决策树个数k=100,原始属性个数d=4,属性子集选择取值为log2d+1=3。在机器学习分析中,若无独立测试集,则需要将数据集按比例分割成训练集与测试集,但由于分割的随机性,可能会产生过拟合与欠拟合问题,为了避免这些问题并充分利用试验数据,本试验采用十倍交叉验证方法对数据进行分析。十倍交叉验证即将数据集随机分割成10个子集,并利用9个子集训练和1个子集测试的方式,分别对10个子集进行10次测试,最终对获得的10个测试结果取平均值作为最终的结果。考虑到分类结果的查准率(precision)与查全率(recall),本文选取二者的调和平均数F1量测(F1 measure)作为分类精度效果评价指标,而由于各类别间的实例数量不均衡,试验最终选取按各类别实例数加权后的F1量测为最终评价指标。除此之外,试验还同时统计了两种分类算法在各子集上的训练时长和测试时长。
图 4反映了十倍交叉验证后朴素贝叶斯算法和随机森林算法在3个数据集上的加权平均F1量测的结果。由图可知,在各数据集上利用随机森林算法的加权平均F1量测值均大于利用朴素贝叶斯算法的值,其中3个数据集加权F1量测的均值在利用随机森林算法时的结果(0.93) 优于在利用朴素贝叶斯算法时的结果(0.87)。表 3展示了两种算法的训练时长和测试时长,可以看出在训练时间方面,3个测试集利用随机森林算法的平均时间消耗(58.88 s)远大于朴素贝叶斯算法(0.07 s),而在测试时间方面,随机森林算法结果(0.74 s)与朴素贝叶斯算法结果(0.15 s)差距并不是很明显。

|
| 图 4 朴素贝叶斯和随机森林在3个数据集上的加权平均F1量测值 |
| s | |||||
| 测试者 | 训练时长 | 测试时长 | |||
| 朴素贝叶斯 | 随机森林 | 朴素贝叶斯 | 随机森林 | ||
| 1 | 0.07 | 68.07 | 0.16 | 0.76 | |
| 2 | 0.06 | 49.81 | 0.14 | 0.75 | |
| 3 | 0.07 | 58.75 | 0.15 | 0.73 | |
| 均值 | 0.07 | 58.88 | 0.15 | 0.74 | |
图 5反映了在利用随机森林算法条件下,3个测试集归一化后的分类混淆矩阵。从3幅图中同时可以看出,主要的分类误差集中在第7行和第7列,即明确定义的活动类别与未定义的活动类别之间。而从测试者2和测试3的混淆矩阵结果可以发现标记为1的活动(开会)与被识别为标记为0的活动(工作)的误差较大。

|
| 图 5 随机森林算法在3个数据集上归一化后的分类混淆矩阵 |
从上述分类精度效果和分类效率来看,随机森林算法相对于原有朴素贝叶斯算法在分类精度效果上有较大改善,但算法的训练效率和测试效率不如后者。算法效率是由算法结构决定的,朴素贝叶斯算法在学习时仅做一些类别的统计工作,以给出分类时所需的先验概率和条件概率,在分类时根据输入的数据给出概率估计即可判定类别;而随机森林算法在学习时则需要生成多个不同的树,在进行分类时需要进行投票统计以获得最优,尤其是学习阶段,需要消耗较长时间。
从基于随机森林算法分类的混淆矩阵来看,分类误差主要发生在类别明确的活动(如工作、开会)和未定义的活动之间,此类误差主要是由活动定义造成的,如在本文的活动定义下,办公室内有可能进行的是工作和未定义活动。测试者2和测试者3在标记为0的活动(工作)和1的活动(开会)之间的误差,主要是由室内定位引擎的定位误差导致的,测试者2和测试者3的办公室和会议室均只有一墙之隔,室内定位的误差导致位置判定错误,直接影响活动识别的效果,而测试者1的定位效果较好,因此各类均得到了较高的分类精度。
4 结语将用户所处在的情境环境信息归纳为时间情境、空间情境、时空情境和用户情境等多维情境特征,综合利用多维情境特征并利用机器学习的方法识别人类活动,有利于推动从基于位置的服务迈向基于情境的服务。原有的多维情境特征框架中利用的是单一分类器朴素贝叶斯算法,该算法简单有效,但分类精度效果存在局限性,本文利用组合分类算法中的随机森林算法对其进行改进,十倍交叉验证结果表明分类精度效果有较大提升,但同时也发现由于随机森林算法结构相对复杂导致其训练效率相对较低的问题。此外,通过对随机森林分类效果的混淆矩阵分析,可见分类误差主要是由明确定义的活动和未明确定义的活动造成的,而定位引擎的定位精度也会对最终的活动分类产生较大影响。
| [1] | LARA O D, LABRADOR M A. A Survey on Human Activity Recognition Using Wearable Sensors[J]. IEEE Communications Surveys & Tutorials, 2013, 15(3): 1192–1209. |
| [2] | INCEL O D, KOSE M, ERSOY C. A Review and Taxonomy of Activity Recognition on Mobile Phones[J]. BioNanoScience, 2013, 3(2): 145–171. DOI:10.1007/s12668-013-0088-3 |
| [3] | SU X, TONG H, JI P. Activity Recognition with Smartphone Sensors[J]. Tsinghua Science and Technology, 2014, 19(3): 235–249. DOI:10.1109/TST.2014.6838194 |
| [4] | CHEN R, CHU T, LIU K, et al. Inferring Human Activity in Mobile Devices by Computing Multiple Contexts[J]. Sensors, 2015, 15(9): 21219–21238. DOI:10.3390/s150921219 |
| [5] | COSKUN D, INCEL O D, OZGOVDE A. Phone Position/Placement Detection Using Accelerometer:Impact on Activity Recognition[C]//IEEE Tenth International Conference on Intelligent Sensors, Sensor Networks and Information Processing.[S.l.]:IEEE, 2015:1-6. |
| [6] | DASH Y, KUMAR S, PATLE V K. A Novel Data Mining Scheme for Smartphone Activity Recognition by Accelerometer Sensor[C]//Proceedings of the 4th International Conference on Frontiers in Intelligent Computing:Theory and Applications (FICTA) 2015.[S.l.]:Springer India, 2016. |
| [7] | GUO J, ZHOU X, SUN Y, et al. Smartphone-based Patients' Activity Recognition by Using a Self-learning Scheme for Medical Monitoring[J]. Journal of medical systems, 2016, 40(6): 1–14. |
| [8] | 周博翔, 李平, 李莲. 改进随机森林及其在人体姿态识别中的应用[J]. 计算机工程与应用, 2015, 51(16): 86–92. DOI:10.3778/j.issn.1002-8331.1309-0162 |
| [9] | HO T K. Random Decision Forests[C]//International Conference on Document Analysis and Recognition.[S.l.]:IEEE, 1995:278-282. |
| [10] | BREIMAN L. Random Forests[J]. Machine learning, 2001, 45(1): 5–32. DOI:10.1023/A:1010933404324 |
| [11] | 郭玉宝, 池天河, 彭玲, 等. 利用随机森林的高分一号遥感数据进行城市用地分类[J]. 测绘通报, 2016(5): 73–76. |
| [12] | HALL M, FRANK E, HOLMES G, et al. The Weka Data Mining Software:An Update[J]. ACM SIGKDD Explorations Newsletter, 2009, 11(1): 10–18. DOI:10.1145/1656274 |