



2. 常州信息职业技术学院 智能制造工业云开放实验室, 常州 213164;
3. 北卡罗来纳大学夏洛特分校 电气与计算机工程系, 夏洛特市 28223
2. Open Lab of Industrial Cloud for Intelligent Manufacturing, Changzhou College of Information Technology, Changzhou 213164, China;
3. Department of Electrical and Computer Engineering, University of North Carolina at Charlotte, Charlotte 28223, USA
行为识别实现了计算机对人体行为的理解与描述,是视频监控[1]、智能看护、人机交互[2]等领域的关键技术。人体行为识别的研究具有广泛的应用前景以及可观的经济价值[3]。执行不同动作时,不同身体部位的协同运动结构特征是行为识别的难题。现今行为识别的方法大致分为3类:①利用单一模态的行为数据进行人体行为识别;②利用多个不同模态的行为数据进行人体行为识别;③利用单一模态内的不同人体部位间的协同运动结构特征进行行为识别。
利用单一模态的行为数据进行人体行为识别,学者们已经提出了许多成熟的算法。按行为识别算法使用的数据类型大致分为:①基于深度图像的人体行为识别,如DMM-LBP-FF(Depth Motion Maps-based Local Binary Patterns-Feature Fusion)[4]、HOJ3D(Histograms of 3D Joint locations)[5]等;②基于骨骼数据的人体行为识别,如协方差描述符[6]等;③基于惯性传感器数据的人体行为识别,如函数拟合[7]等。
利用多个不同模态的行为数据进行人体行为识别,也有很多的学者进行了研究。多模态行为数据的融合大致可以分为2类:特征级融合和决策级融合[8]。常见的特征级融合方法有CRC(Collaborative Representation Classifier)[9]、SRC(Sparse Representation Classifier) [10]、CCA(Canonical Correlation Analysis)[11]、DCA(Discriminant Correlation Analysis)[12]等。决策级融合方法如DS(Dempster-Shafer)证据理论[10]、多学习器协同训练[13]。
利用单一模态内的不同人体部位间的协同运动结构特征进行行为识别,目前已有少量的研究。Si等[14]提出空间推理网络,其利用Kinect采集的人体关节点位置数据来捕捉每个帧内的高级空间结构特征。首先将身体每个部位的连接转换成具有线性层的单独空间特征,然后将身体部位的个体空间特征输入到残差图神经网络(Residual Graph Neutral Network, RGNN)以捕获不同身体部位之间的高级结构特征。Liu等[15]提出动态姿态图像描述人体行为,其利用姿态估计方法得到人体14个联合估计图,每一个联合估计图表示一个关节的运动,然后使用神经网络融合不同关节的运动。邓诗卓等[16]利用人体不同部位的三轴向传感器(三轴加速度、三轴陀螺仪等)的相同轴向数据间隐藏的空间依赖性并结合卷积神经网络(Convolutional Neural Networks, CNN)进行动作识别。
基于单模态、多模态的行为识别方法虽然可以识别不同的行为,但是忽略了人体在执行动作时不同身体部位的空间协同运动结构特征。动作的完成需要多块肌肉共同协调配合,例如走路不仅需要双腿,同时也需要摆动手臂以协调身体平衡[14]。现有计算不同身体部位结构特征的方法大都使用了神经网络,其训练时间复杂度高、计算资源消耗高、可解释性差等。
本文针对使用神经网络计算结构特征的复杂性高等问题,提出利用人体不同部位的三轴加速度数据构建人体空间协同运动的结构特征模型,并无监督、自适应地对不同身体部位的运动特征进行约束。首先对执行不同动作时的人体不同部位的三轴加速度曲线进行曲线特征分析,确定不同身体部位对不同动作的完成具有不同的贡献度;其次对执行某一动作时人体全身三轴加速度曲线进行曲线特征分析,并提出利用曲线的多个统计值度量人体不同部位的贡献度;然后由于多个统计量对构建结构特征模型具有不同的权重,需要进行权重的确定;再使用协同运动结构特征模型对人体不同部位的运动特征进行无监督、自适应地约束;最后使用多模态特征选择与特征融合算法将不同模态的特征进行融合并分类识别。
1 总体框架本文提出利用人体空间协同运动的结构特征模型,对不同人体部位的运动特征进行约束,然后对多模态特征进行特征选择与特征融合,总体框架如图 1所示。对骨骼图序列按Chen等[17]方法进行特征提取,图 1中的“骨骼图序列”引自文献[18]。首先,对人体不同部位的三轴加速度数据分别提取特征;然后使用结构特征模型约束特征;最后使用多模态特征选择与特征融合方法训练多模态特征投影矩阵用于融合三轴加速度数据特征与关节点位置数据特征,使用分类器对融合后的特征进行分类识别,得到类别标签。

|
| 图 1 总体框架 Fig. 1 Overall framework |
设γk={ax, ay, az}为人体第k个惯性传感器采集的三轴加速度数据,人体执行动作时全身的三轴加速度数据为γ={γ1,…,γk,…,γK},其中K为人体惯性传感器的总数。对人体不同部位的三轴加速度数据进行特征提取,得到人体全身的运动特征FK=[fxk, fyk, fzk], k=1, 2, …, K,其中fxk为人体第k个部位x轴的特征,fyk为人体第k个部位y轴的特征,fzk为人体第k个部位z轴的特征。然后使用协同运动结构特征模型对特征进行约束从而使得样本具有更好的分类能力。
将n个样本划分为c类,ni为第i类样本的数量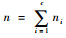

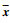
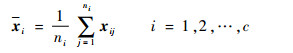
|
(1) |

|
(2) |
分别计算类间距离Sb与类内距离Sw:

|
(3) |
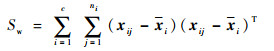
|
(4) |
然后计算类间距离Sb与类内距离Sw的比值Jw。为了使得样本具有更好的可分离性,需要增大比值Jw:

|
(5) |
本文利用人体空间协同运动的结构特征模型对特征进行约束,约束后的第i类样本均值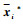
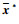

|
(6) |

|
(7) |
式中:Wij=[wxk, wyk, wzk], k=1, 2, …, K为第i类第j个样本对应的结构特征,并用于约束人体全身的运动特征,得到约束后的特征(FK)*=[fxk*, fyk*, fzk*], k=1, 2, …, K。以计算fyk*为例,fyk*=wykfyk。计算约束后的类间距离Sb*与类内距离Sw*:
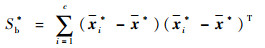
|
(8) |
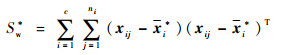
|
(9) |
其中:Sb*为约束后的样本类间距离;Sw*为约束后的样本类内距离。使Sb*与Sw*的比值Jw*大于Jw,即可使样本更好地分离。
以左高挥手、右高挥手动作为例,左高挥手动作的主运动结点为左手肘、左手腕;右高挥手动作的主运动结点为右手肘、右手腕,其他的身体部位为附加运动结点。本文分别对比左高挥手与右高挥手动作的主运动结点以及附加运动结点的三轴加速度曲线。主运动结点曲线的对比如图 2所示,附加运动结点曲线的对比如图 3所示。图 2(a)为执行左高挥手动作时左手肘、左手腕、右手肘、右手腕部位对应的三轴加速度曲线图。类似地,图 2 (b)为执行右高挥手动作时左手肘、左手腕、右手肘、右手腕部位对应的三轴加速度曲线图。图 3(a)为左高挥手动作附加运动结点的三轴加速度曲线图,图 3(b)为右高挥手动作附加运动结点的三轴加速度曲线图。

|
| 图 2 左高挥手、右高挥手动作主运动结点的三轴加速度曲线 Fig. 2 Triaxial acceleration curves of main motion nodes of left high wave and right high wave |

|
| 图 3 左高挥手、右高挥手动作附加运动结点的三轴加速度曲线 Fig. 3 Triaxial acceleration curves of additional motion nodes of left high wave and right high wave |
首先对比左高挥手、右高挥手动作附加运动结点的三轴加速度曲线,可以发现这2个动作附加结点的三轴加速度曲线形状相同均保持平稳即方差差异性小,此外曲线的均值也接近,即这2个动作附加结点的类间距离小,分类能力差。然后比对左高挥手、右高挥手动作主运动结点的三轴加速度曲线,对于区分左高挥手与右高挥手动作主要是根据左手肘、左手腕、右手肘、右手腕处三轴加速度曲线的统计特征。为了使样本更好地分离,需要强化每个动作主运动结点的特征、削弱附加运动结点的特征,基于此本文使用基于人体空间协同运动的结构特征模型对不同身体部位的特征进行约束。以右高挥手动作为例,从图 2(b)、图 3(b)中可以观察到,对于动作的完成不同身体部位的贡献度是不同的,其主运动结点为右手肘、右手腕,即右手肘、右手腕对动作的完成具有高的贡献度,附加运动结点的贡献度相对较小。本文使用执行动作时不同身体部位的贡献度构建协同运动的结构特征模型。为了度量不同部位对完成动作的贡献,本文通过式(10)度量人体第k个部位x、y、z轴的贡献,其他结点贡献度的度量与此类似:

|
(10) |
以pxk为例,pxk为人体第k个部位x轴的贡献度,σ(xk)为人体第k个部位x轴运动数据的标准差,|μ(xk)|为人体第k个部位x轴运动数据均值的绝对值,λ1、λ2为超参数用于平衡标准差和均值的绝对值。然后利用式(11)对贡献度进行归一化得到结构特征模型并用于约束特征:

|
(11) |
为了说明本文提出的结构特征模型的有效性,分别计算类间距离为2175、类内距离为10383以及Jw为0.2095。然后再计算使用结构特征模型约束后的特征的类间距离为575、类内距离为2046以及Jw*为0.2810。从计算结果可知Jw*>Jw,即使用结构特征模型约束后的特征具有更佳的分离能力。
3 多模态特征选择与特征融合在采集人体的行为数据时一般会采集多个模态的数据。为了利用不同模态的数据进行行为识别,需要融合多模态特征。此外每个模态内包含了大量的冗余特征,需要对特征进行选择。设Γ={xi1, xi2, …, xiM}i=1N表示N个动作样本,其中每个样本包含M个不同模态的特征。虽然第i个样本Γi={xi1, xi2, …, xiM}包含了M个不同模态的特征,但类别标签相同xi1, xi2, …, xiM→yi。本文为每个模态的特征分别学习投影矩阵。用于将不同模态的特征投影到子空间。并在投影的过程中完成对特征的选择。最后按式(12)进行多模态特征的融合:

|
(12) |
式中:f为融合后的特征;xp为第p个模态的特征, p=1, 2, …, M;Up为第p个模态的投影矩阵, p=1, 2, …, M;xp*为第p个模态投影后的特征, p=1, 2, …, M。将融合后的特征称之为多模态融合特征(multi-modal fusion features)并用于分类识别。本文借鉴联合特征选择与子空间学习JFSSL方法[19]学习多模态投影矩阵,用于将不同模态的特征投影到子空间,并使用ℓ2, 1范数来实现特征选择[20],其最小化问题如下:

|
(13) |
式中:Xp为第p个模态的特征矩阵, p=1, 2, …, M; Y为JFSSL方法构造的子空间,Y∈RN×c。式(13)的第1项用于学习投影矩阵,第2项用于特征选择,第3项用于保持模态内和模态间的相似关系。式(13)的第3项的推导为

|
(14) |
其中:
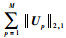


|
(15) |
其中: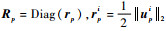
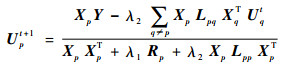
|
(16) |
本文使用式(16)迭代计算得到不同模态的投影矩阵,将不同模态的特征投影到子空间,再将子空间的特征按式(12)进行融合用于行为识别。
4 数据采集本节介绍自建的数据采集系统,并将其用于全身运动数据的获取。
4.1 采样系统搭建Kinect v2传感器可以采集RGB-D图像以及人体25个关节点的位置数据。MPU9250惯性传感器是一种体积小、功耗小的传感器,采样率为500Hz,可同时捕获三轴加速度、三轴角速度和三轴磁场强度数据并输出四元数等。
本文利用Kinect采集深度图像和关节点位置数据,利用MPU9250采集三轴加速度数据。为了采集人体全身部位的三轴加速度数据,本文搭建了包含10个惯性传感器的运动数据采集系统,采样系统架构如图 4所示,其中NTP(Network Time Protocol)服务器用于提供标准时间,无线AP(wireless Access Point)用于组建无线局域网络。利用卡片式计算机树莓派控制MPU9250传感器,利用笔记本电脑控制Kinectv2,每次采集数据时都与NTP服务器进行时间同步。本文综合考虑了MHAD[22]、UTD-MHAD[23]等行为数据库的采样方案后,确定惯性传感器的位置如图 5所示,图中红色标记点为惯性传感器的位置,“左”为人体的左侧,“右”为人体的右侧。图 6为本文的真实采样场景。

|
| 图 4 采样系统架构 Fig. 4 Sampling system architecture |

|
| 图 5 可穿戴传感器位置示意图 Fig. 5 Position schematic diagram of wearable sensor |

|
| 图 6 真实采样场景 Fig. 6 Real sampling scene |
本文自建的行为数据库包含7位男性受试者,年龄分布为20~26岁,其中包括一个肥胖型受试者、一个瘦弱型受试者。7个男性受试者分别执行15个动作, 每个动作重复执行10次。15个动作类别如表 1所示。
| 序号 | 类别 |
| 1 | 右高挥手 |
| 2 | 左高挥手 |
| 3 | 右水平挥手 |
| 4 | 左水平挥手 |
| 5 | 右手锤 |
| 6 | 右手抓 |
| 7 | 右手画叉 |
| 8 | 左手画叉 |
| 9 | 右手画圆 |
| 10 | 左手画圆 |
| 11 | 右脚前踢 |
| 12 | 左脚前踢 |
| 13 | 右脚侧踢 |
| 14 | 左脚侧踢 |
| 15 | 上下挥手 |
5 实验结果与分析 5.1 特征提取
本文在自建的数据库上进行实验,实验选取了5位受试者执行的15个行为动作,其中每个动作由每位受试者重复执行8次,实验用的行为数据库一共包含600个样本。对三轴加速度数据提取经典的时域特征:均值、方差、标准差、峰度、偏度。
5.2 实验设置1) 设置1。与Chen等[4]类似, 在第1组实验中将3/8样本作为训练,剩下数据作为测试;在第2组实验中将4/8样本作为训练;在第3组实验中将5/8样本作为训练;在第4组实验中将6/8样本作为训练。本文使用T1~T4代表上述4组实验。
2) 设置2。与Chen等[24]类似,在第1组实验中将标记为1、2对象的数据作为训练样本;在第2组实验中将标记为1、2、5对象的数据作为训练样本;在第3组实验中将标记为1、2、3、5对象的数据作为训练样本。本文使用T5~T7代表上述3组实验。
5.3 参数设置本文的实验需要对分类器参数、超参数等进行选择, 所需参数都通过CV(Cross Validation)校验的方法进行确定。
1) 分类器参数设置。本文中使用的分类器如CRC(Collaborative Respresentation Classifier)、KNN (K-Nearest Neighbor)、RandomF(Random Forest)等需要确定最佳参数。最终确定的分类器最优参数为:KNN的参数设置为1;RandomF的参数设置为65;CRC的参数设置为0.000 1。
2) 超参数设置。联合特征选择与子空间学习的参数λ1、λ2分别设置为0.001和0.001;本文提出的结构特征模型中的超参数λ1、λ2分别设置为5和0.05。
5.4 三轴加速度数据特征分类识别本节对全身三轴加速度数据的特征以及使用结构特征模型约束后的特征进行分类识别。表 2为使用人体全身的三轴加速度数据特征的识别率(即本节的基线实验),表 3为使用结构特征模型约束后的特征的识别率。
| 分类器 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| KNN | 39.64 | 41.85 | 43.84 | 45.90 | 31.11 | 33.33 | 40.83 |
| 判别分析 | 92.21 | 95.80 | 97.07 | 97.40 | 75.28 | 86.25 | 85.83 |
| SVM | 60.31 | 65.45 | 70.13 | 71.10 | 47.78 | 55.42 | 55.83 |
| 朴素贝叶斯 | 77.45 | 77.57 | 78.78 | 80.00 | 61.67 | 59.58 | 73.33 |
| CRC | 81.92 | 85.07 | 86.27 | 89.07 | 56.94 | 66.25 | 77.50 |
| RandomF | 94.01 | 95.15 | 95.96 | 96.50 | 86.39 | 88.75 | 86.67 |
从表 2可知,封闭测试T1~T4在使用判别分析、RandomF分类器的情况下识别率很高,如表 2中的T4实验使用判别分析分类器的识别率可高达到97.40%。然而表 2中的开放测试T5~T7的识别率均低于T1~T4的识别率。因此本文的目的是提高开放测试T5~T7的识别率。为此,将表 3中的T5~T7与表 2中的T5~T7的识别率进行对比,对比的结果如图 7所示。
| 分类器 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| KNN | 59.95 | 66.47 | 65.33 | 68.80 | 50.00 | 51.25 | 56.67 |
| 判别分析 | 92.59 | 95.07 | 96.89 | 97.20 | 75.83 | 88.75 | 89.17 |
| SVM | 71.31 | 76.33 | 77.96 | 78.93 | 56.39 | 67.08 | 74.17 |
| 朴素贝叶斯 | 75.68 | 78.47 | 78.58 | 80.80 | 68.33 | 60.83 | 71.67 |
| CRC | 86.56 | 89.00 | 90.04 | 92.93 | 70.83 | 80.00 | 87.50 |
| RandomF | 94.83 | 95.40 | 96.18 | 96.53 | 84.56 | 85.75 | 89.17 |

|
| 图 7 约束后的识别率与基线识别率的对比 Fig. 7 Comparison of recognition rate after constraints with baseline recognition rate |
图 7中每个分类器后的数字为特征约束后的识别率减去基线识别率的结果。从图 7中可以直观看出, 特征约束后T5~T7的识别率明显高于基线识别率。说明本文利用基于人体空间协同运动的结构特征模型约束的特征具有更佳的分类能力。
5.5 关节点位置数据的识别率表 4为关节点位置数据的识别率。由于5.6节实验为多模态特征的融合,故本节先计算关节点位置数据的识别率作为多模态特征融合的基线识别率。
| 分类器 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| KNN | 41.11 | 42.45 | 43.33 | 45.70 | 37.22 | 41.25 | 36.67 |
| 判别分析 | 94.16 | 91.93 | 60.40 | 96.50 | 86.90 | 68.33 | 90.00 |
| SVM | 61.95 | 67.73 | 71.18 | 75.43 | 49.17 | 60.83 | 71.67 |
| 朴素贝叶斯 | 84.68 | 87.43 | 89.22 | 90.30 | 83.33 | 87.92 | 85.00 |
| CRC | 71.67 | 80.60 | 83.11 | 85.57 | 73.33 | 84.17 | 85.83 |
| RandomF | 96.70 | 97.32 | 97.33 | 98.00 | 91.94 | 97.92 | 98.33 |
5.6 多模态特征选择与特征融合的识别率
本节使用多模态特征选择与特征融合方法对三轴加速度数据特征、关节点位置数据特征进行融合并使用多个分类器进行分类识别,其识别结果如表 5所示,并且将表 5作为本节的基线实验,将表 5与表 4、表 3的T1~T7识别率进行对比可知,多模态特征融合的识别率均优于单个模态特征的识别率。将本文结构特征模型约束后的特征与关节点位置数据特征进行融合,结果如表 6所示。
| 分类器 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| KNN | 77.31 | 84.25 | 88.27 | 89.23 | 89.72 | 92.08 | 88.33 |
| 判别分析 | 91.63 | 96.30 | 97.80 | 98.33 | 91.39 | 97.50 | 100.00 |
| SVM | 88.43 | 93.93 | 96.00 | 97.07 | 90.83 | 97.50 | 98.33 |
| 朴素贝叶斯 | 78.89 | 91.47 | 94.47 | 96.43 | 74.72 | 88.75 | 97.50 |
| CRC | 70.72 | 83.97 | 88.71 | 91.13 | 89.44 | 86.25 | 87.50 |
| RandomF | 88.85 | 93.52 | 94.84 | 95.93 | 82.71 | 88.40 | 97.04 |
| 分类器 | T1 | T2 | T3 | T4 | T5 | T6 | T7 |
| KNN | 88.79 | 93.75 | 96.53 | 97.10 | 87.22 | 97.92 | 100.00 |
| 判别分析 | 89.84 | 96.07 | 97.80 | 98.17 | 90.83 | 98.33 | 100.00 |
| SVM | 89.07 | 94.88 | 96.51 | 97.90 | 88.33 | 98.33 | 100.00 |
| 朴素贝叶斯 | 80.09 | 90.65 | 94.96 | 95.83 | 79.44 | 95.42 | 100.00 |
| CRC | 86.85 | 93.75 | 96.16 | 97.50 | 87.22 | 97.08 | 100.00 |
| RandomF | 88.48 | 93.01 | 94.47 | 96.00 | 85.49 | 94.50 | 96.29 |
表 6与表 5的T1~T4相比,融合约束后的特征与关节点位置数据特征的识别率均显著高于基线实验。由于本文的重点是提高开放测试的识别率,因此将表 6与表 5的T5~T7进行对比,对比结果如图 8所示。

|
| 图 8 融合约束后的三轴加速度数据特征和关节点位置数据特征的识别率与基线识别率的对比 Fig. 8 Comparison of recognition rate of triaxial acceleration feature and joint point position data feature after fusion constraints with baseline |
从图 8中可以直观看出,在T6、T7实验中本文方法明显优于基线实验,在T5测试中本文方法略低于基线实验。这是由于T5测试选取2/5受试者的样本作为训练,选取的受试者数量少,从侧面说明本文提出的算法还可以进一步改良。此外表 6中T7实验的识别率在5个分类器中高达100.00%。上述的对比结果说明本文提出的基于人体空间协同运动的结构特征模型的有效性。
6 结论本文提出了利用人体不同部位三轴加速度数据的多个统计值用于度量不同部位对完成动作的贡献度,利用不同部位的贡献度构建面向行为识别的人体空间协同运动结构特征模型,并无监督、自适应地对人体不同部位的特征进行约束。在此基础上,借鉴JFSSL方法融合多模态的行为特征,并在融合过程中完成了对特征的筛选。实验结果表明:
1) 该模型适用于具有全身三轴加速度数据的行为识别,模型的构建不需要复杂的算法计算,具有较好的实时性。
2) 在自建的行为数据库的封闭测试(T1~T4)、开放测试(T5~T7)中均有优异的效果。
3) 通过实验证明了人体在执行动作时不同部位之间存在协同性。这为进一步探索人体空间协同运动的结构特征提供了实验依据。
| [1] |
LUVIZON D C, PICARD D, TABIA H.2D/3D pose estimation and action recognition using multitask deep learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2018: 5137-5146.
|
| [2] |
FABIEN B, CHRISTIAN W, JULIEN M, et al.Glimpse clouds: Human activity recognition from unstructured feature points[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2018: 469-478.
|
| [3] |
HOU R, CHEN C, MUBARAK S.Tube convolutional neural network (T-CNN) for action detection in videos[C]//Proceedings of the IEEE International Conference on Computer Vision(ICCV).Piscataway, NJ: IEEE Press, 2017: 5822-5831.
|
| [4] |
CHEN C, JAFARI R, KEHTARNAVAZ N.Action recognition from depth sequences using depth motion maps-based local binary patterns[C]//IEEE Winter Conference on Applications of Computer Vision.Piscataway, NJ: IEEE Perss, 2015: 1092-1099.
|
| [5] |
XIA L, CHEN C, AGGARWAL J K.View invariant human action recognition using histograms of 3d joints[C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops(CVPRW).Piscataway, NJ: IEEE Press, 2012: 20-27.
|
| [6] |
HUSSEIN M E, TORKI M, GOWAYYED M A.Human action recognition using a temporal hierarchy of covariance descriptors on 3d joint locations[C]//23rd International Joint Conference on Artificial Intelligence.Palo Alto: AAAI Press, 2013: 2466-2472.
|
| [7] |
苏本跃, 蒋京, 汤庆丰, 等. 基于函数型数据分析方法的人体动态行为识别[J]. 自动化学报, 2017, 43(5): 866-876. SU B Y, JIANG J, TANG Q F, et al. Human dynamic action recognition based on functional data analysis[J]. Acta Automatica Sinica, 2017, 43(5): 866-876. (in Chinese) |
| [8] |
GRAVINA R, ALINIA P, GHASEMZADEH H, et al. Multi-sensor fusion in body sensor networks:State-of-the-art and research challenges[J]. Information Fusion, 2017, 35: 68-80. DOI:10.1016/j.inffus.2016.09.005 |
| [9] |
CHEN C, LIU K, KEHTARNAVAZ N. Real-time human action recogniti on based on depth motion maps[J]. Journal of Real-Time Image Processing, 2016, 12(1): 155-163. DOI:10.1007/s11554-013-0370-1 |
| [10] |
CHEN C, JAFARI R, KEHTARNAVAZ N. Improving human action recognition using fusion of depth camera and inertial sensors[J]. IEEE Transactions on Human-Machine Systems, 2015, 45(1): 51-61. DOI:10.1109/THMS.2014.2362520 |
| [11] |
HAGHIGHAT M, ABDEL-MOTTALEB M, ALHALABI W. Fully automatic face normalization and single sample face recognition in unconstrained environments[J]. Expert Systems with Applications, 2016, 47: 23-34. DOI:10.1016/j.eswa.2015.10.047 |
| [12] |
HAGHIGHAT M, ABDEL-MOTTALEB M, ALHALABI W. Discriminant correlation analysis:Real-time feature level fusion for multimodal biometric recognition[J]. IEEE Transactions on Information Forensics and Security, 2016, 11(9): 1984-1996. DOI:10.1109/TIFS.2016.2569061 |
| [13] |
唐超, 王文剑, 李伟, 等. 基于多学习器协同训练模型的人体行为识别方法[J]. 软件学报, 2015, 26(11): 2939-2950. TANG C, WANG W J, LI W, et al. Multi-learner co-training model for human actioin recognition[J]. Journal of Software, 2015, 26(11): 2939-2950. (in Chinese) |
| [14] |
SI C Y, JING Y, WANG W, et al.Skeleton-based action recognition with spatial reasoning and temporal stack learning[C]//Proceedings of the European Conference on Computer Vision (ECCV).Berlin: Springer, 2018: 103-118.
|
| [15] |
LIU M Y, MENG F Y, CHEN C, et al.Joint dynamic pose image and space time reversal for human action recognition from videos[C]//33rd AAAI Conference on Artificial Intelligence.Palo Alto: AAAI Press, 2019: 8762-8769.
|
| [16] |
邓诗卓, 王波涛, 杨传贵, 等. CNN多位置穿戴式传感器人体活动识别[J]. 软件学报, 2019, 30(3): 718-737. DENG S Z, WANG B T, YANG C G, et al. Convolutional neural networks for human activity recognition using multi-location wearable sensors[J]. Journal of Software, 2019, 30(3): 718-737. (in Chinese) |
| [17] |
CHEN C, JAFARI R, KEHTARNAVAZ N. A real-time human action recognition system using depth and inertial sensor fusion[J]. IEEE Sensors Journal, 2016, 16(3): 773-781. DOI:10.1109/JSEN.2015.2487358 |
| [18] |
许艳, 侯振杰, 梁久祯, 等. 权重融合深度图像与骨骼关键帧的行为识别[J]. 计算机辅助设计与图形学学报, 2018, 30(7): 139-146. XU Y, HOU Z J, LIANG J Z, et al. Action recognition using weighted fusion of depth images and skeleton's key frames[J]. Journal of Computer-Aided Design & Computer Graphics, 2018, 30(7): 139-146. (in Chinese) |
| [19] |
WANG K, HE R, WANG L, et al. Joint feature selection and subspace learning for cross-modal retrieval[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2010-2023. DOI:10.1109/TPAMI.2015.2505311 |
| [20] |
NIE F, HUANG H, CAI X, et al.Efficient and robust feature selection via joint ℓ2, 1-norms minimization[C]//Advances in Neural Information Processing Systems(NIPS).New York: Curran Associates, 2010: 1813-1821.
|
| [21] |
HE R, TIAN T N, WANG L, et al.L2, 1 regularized correntropy for robust feature selection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway, NJ: IEEE Press, 2012: 2504-2511.
|
| [22] |
OFLI F, CHAUDHRY R, KURILLO G, et al.Berkeley MHAD: A comprehensive multimodal human action database[C]//2013 IEEE Workshop on Applications of Computer Vision (WACV).Piscataway, NJ: IEEE Press, 2013: 53-60.
|
| [23] |
CHEN C, JAFARI R, KEHTARNAVAZ N.UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor[C]//2015 IEEE International Conference on Image Processing (ICIP).Piscataway, NJ: IEEE Press, 2015: 168-172.
|
| [24] |
CHEN C, ZHANG B G, HOU Z J, et al. Action recognition from depth sequences using weighted fusion of 2D and 3D auto-correlation of gradients features[J]. Multimedia Tools and Applications, 2017, 76(3): 4651-4669. DOI:10.1007/s11042-016-3284-7 |