



2. 北京市工业波谱成像工程技术研究中心, 北京 100083;
3. 中国科学院自动化研究所, 北京 100190
2. Beijing Engineering Research Center of Industrial Spectrum Imaging, Beijing 100083, China;
3. Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China
人体姿态估计是指还原给定图片或者视频中人体关节点位置的过程,其对于描述人体姿态,预测人体行为起到至关重要的作用。近年来,随着深度学习技术的发展,人体姿态估计越来越广泛地运用到计算机视觉的各个领域之中,例如人机交互、行为识别以及智能监控等等。现如今,二维人体姿态估计算法的日渐成熟,三维的人体姿态估计开始受到更多研究者的关注,其在二维姿态估计的基础上加入了深度信息,这也进一步扩大了姿态估计的应用场景。早期的研究过多关注于利用人体的几何约束为主要特征来估计三维人体姿态[1-3],例如使用梯度方向直方图以及层次物体识别模型提取特征来对三维姿态进行预测,这种方法保证了输出结果的合理性,不过由于不同个体之间存在差异,往往难以获得精确的结果。当前的研究算法大多通过单幅RGB图像[4-8]以及利用已知二维姿态方法[9-15]来恢复人体的三维姿态,前者将姿态估计由回归问题转化为在离散空间中定位关节点位置的问题,取得了不错的效果,但其一定程度上会因遮挡等环境因素而导致检测性能下降。使用二维姿态恢复的方法则是寻找由二维关节点向三维空间的映射[16-17],这种方法相比其他方法更为直接,且最终的检测结果往往依赖于二维关节点坐标是否精确。
以上研究算法大多建立在对单帧图像进行分析的基础上,而现实生活中更多的数据源来自于视频输入,视频作为多帧连续图像的组合,包含了更为复杂的时序信息。而基于单帧图像进行估计一定程度上会导致相邻帧的检测结果存在巨大差异,因此,基于视频的三维人体姿态估计比单帧图像检测具有更大的挑战。在时序分析领域,循环神经网络(Recurrent Neural Network,RNN)一直因其善于处理序列化数据而有着广泛地应用,英国著名的人工智能公司DeepMind于2016年提出的WaveNet[18]通用模型证明一维的卷积神经网络(Convolutional Neural Network,CNN)同样对序列化数据特征有着良好的提取能力,另外与RNN相比不容易受到梯度消失和爆炸的影响而且有着更为简单的网络结构。因此以一维卷积为基础设计深层网络来挖掘分析视频中的时序信息可能会具有更加突出的作用。
本文受到上述启发,构建了一种以视频中人体二维关节点坐标作为输入恢复得到三维人体姿态的算法,主要贡献概括如下:基于一维卷积对时序信息的提取能力,设计了一种高效网络,对视频中的三维人体姿态实现了准确的估计。深入研究视频相邻帧之间视觉信息的连续性,提出了一种新的损失函数,改进姿态估计结果的平滑性和有效性。最后在特定数据集上进行试验并对比分析,充分验证了本文方法对视频中的三维人体姿态估计的有效性,研究成果也为一些实际应用提供了技术支持。
1 三维姿态估计 1.1 方法概述直觉上,二维关节点坐标向三维空间的映射可能会因缺少深度信息而导致错误姿态,不过Martinez等[16]提出的基准方法证明了使用网络实现二维关节点恢复三维姿态是完全可行的,网络能够很好地依据关节相对位置来预测深度信息和连接关系。因此本文设计了一种以连续二维关节点坐标序列为输入恢复视频相关三维人体姿态的方法,如图 1所示。二维关节点坐标直接由数据集的标注得到,除此之外,还可以通过将单帧图像送入二维姿态检测器得到人体二维关节点坐标,本文方法可以与目前许多高精度二维姿态检测器相结合,实现对于任意图像或视频输入,都能够准确恢复人体的三维姿态。之后对得到的二维关节点坐标序列进行归一化处理,加快网络收敛速度。最后将处理过的序列数据送入三维姿态估计网络,训练时网络会生成与序列数据相同数目的姿态,测试时本文只取中间一帧的姿态作为输出,因此输入二维关节点坐标序列的数目应为奇数。

|
| 图 1 三维姿态生成过程 Fig. 1 Generation process of three-dimensional pose |
三维姿态估计网络主要由4个具有相同结构的残差网络模块进行串联组成,除输入输出外,第一层的3×1卷积和最后一层的1×1卷积分别用于将输入维度进行扩展以增加网络宽度和将维度降至输出维度。残差网络模块由卷积层、BatchNormal(BN)层、ReLU层以及残差连接组成。
1) 卷积层。残差网络模块在卷积层主要使用3×1的一维卷积和卷积核大小为1×1的点卷积,一维卷积通过卷积核的滑动来提取时间序列上的信息,点卷积主要用于改变特征的维度以此来对同维度的特征进行信息融合。
2) BN层。神经网络各层的输出由于经过层内操作,其数据分布显然会与对应层的输入不同,并且差异会随着网络层的堆叠而逐渐增大,而BN层主要用于对每层的输入进行规范化,用于解决数据分布不均而导致的训练深层网络模型困难的问题。BN层一定程度上起到了正则化的作用,使得训练过程中能够使用较高的学习速率,更加随意的对参数进行初始化,加快训练速度,提高网络的泛化性能。
3) ReLU层。ReLU层是一个非线性的激活单元,主要用于增加网络的非线性特征,其单侧抑制特性使得一部分神经元的输出为0,增加稀疏性,减少了参数间的相互依存关系,缓解了过拟合问题的发生。
4) 网络还借鉴了ResNet[19]网络结构中残差连接的思想,将输出表述为输入和输入的一个非线性变换的线性叠加,使得各个层级提取到的特征可以随意进行组合,保证特征在网络中的传递,三维姿态估计网络结构如图 2所示。

|
| 图 2 三维姿态重建网络结构 Fig. 2 Three-dimensional pose reconstruction network structure |
对网络的设计不仅要求模型结构有着良好的性能,还要考虑实际应用中网络运行所需要的存储空间以及计算资源。网络模型的空间复杂度主要指的是参数的个数,其中ReLU层作为激活单元并没有需要学习的参数,单个BatchNormal层也仅有2个可以学习的参数,因此网络模型占用的空间大小近似等于所有卷积层的参数量之和,网络模型的时间复杂度主要通过浮点运算次数(FLoating-Point Operations,FLOPs)来衡量。使用连续9帧图像中人体关节点二维坐标为输入,计算不同数目的残差模块对于参数个数以及计算资源的消耗,并比较最终的测试误差。
由表 1可得,在4个残差模块的使用下得到了最优结果,此后随着网络的进一步加深,出现了过拟合现象,平均测试误差开始增加,后续实验也采用4个残差模块的网络结构与其他方法进行对比分析。本文设计的轻量级网络模型实现了对三维人体姿态准确高效的估计,在有效减少参数的同时也具有极快的处理速度,能够更好地应用在各种硬件设备中。
| 残差模块数 | 浮点运算次数/百万 | 参数个数/百万 | 平均误差/mm |
| 2 | 76.9 | 8.5 | 46.6 |
| 3 | 114.6 | 12.7 | 45.8 |
| 4 | 152.4 | 16.9 | 44.7 |
| 5 | 190.2 | 21.1 | 45.5 |
2 相似姿态位移约束损失函数
本文网络主要是利用已有的数据,取连续帧的二维关节点坐标作为输入,对人体关节点坐标从二维到三维空间的映射进行有监督学习并最终输出人体三维关节点的坐标,其本质上是一个回归问题。网络优化的目标是使得预测得到的三维关节点的坐标与真值之间的差值最小,因此首先定义姿态距离(Pose Distance,PD)的损失函数:
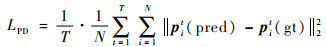
|
(1) |
式中:T为同时输入网络连续帧关节点的数目; N为人体关节点的数目,在实验中N=17;||·||22表示Euclidean范数,通过使用预测值与真值的欧氏距离作为衡量关节点之间差异的标准; pit(pred)和pit(gt)分别表示输入第t帧图像中第i个关节点的三维坐标预测值和真实值。
视频数据承载的信息不仅仅存在于单帧图像中,其更多的语义信息会通过连续帧来表达,而传统的视频姿态估计算法大多基于单帧图像,然后将结果整合为视频输出,无法充分利用视频的时空结构特性,往往存在输出不连续等问题。本文随机选取任意视频序列进行分析,并通过计算两个姿态间各个关节点之间的欧氏距离之和作为姿态差异,将实验结果取平均,根据图 3可以得出同一视频段中姿态差异随序列增加近似呈线性增长,且相邻帧保持着微小的差异,通过网络训练来学习这一特性,可以使网络能够依据当前时刻的输入预测下一时刻的输出,同时也保证后一帧的姿态预测结果与前一帧相比能够近似一致,以此来增加视频中姿态估计的准确性和平滑性。

|
| 图 3 相邻帧姿态差异 Fig. 3 Pose difference between adjacent frames |
基于上述分析,本文设计一种名为相似姿态位移约束(Similar Pose Displacement Constraint,SPDC)的损失函数来学习视频中的人体姿态在时间维度上的连续性,计算公式为
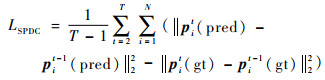
|
(2) |
式中:pit(pred)-pit-1(pred)表示预测得到的第t和t-1帧间的姿态差异;pit(gt)-pit-1(gt)则表示相邻帧间的真实姿态差异。最终的损失函数定义为上述两种损失的加权和,即
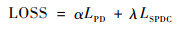
|
(3) |
式中:α和λ分别为姿态距离损失函数以及相似姿态位移约束损失函数的权重比,本文以姿态距离损失函数为主要的优化目标,使输出的每个关节点坐标值都尽可能地回归到真值附近,并辅以相似姿态位移约束损失函数来充分学习相邻帧的近似一致性,增加检测结果的平滑性。对α和λ的选取规则应该是α大于λ,经过多次实验对比,本文选取α=5以及λ=1作为最优的权重比,最终的损失函数为两种不同损失函数的加权和。
3 实验结果分析 3.1 实验数据集为了对本文方法的性能进行评价,在三维人体姿态数据集Human3.6M[20]上进行了实验,Human3.6M是目前为止最大也是使用最为广泛的三维人体姿态估计数据集,其主要由7位实验者在4个不同视角下使用高清摄像机精确捕捉的360万个三维人体姿态组成,视频的帧率为50 Hz,分辨率大小为1 000×1 000。数据集被分割为11个子类别,其中7个类别包含了三维关节点标注,而且还使用相机参数对三维姿态的关节点数据进行投影,并获得准确的二维姿态信息,每个类别中都包括走路、打招呼等15个生活中常见动作。
3.2 实验细节和评价标准实验过程中,使用Human3.6M提供的二维关节点坐标,选取某帧前后数目相等的二维关节点坐标序列作为输入,训练时为了保证视频起始端和末端完整性,对输入数据采取边缘填充操作,根据输入连续帧数目对起始帧和结束帧的二维关节点数据进行复制并填充。此外,本文还对输入的二维关节点坐标根据图像大小进行归一化处理。训练时采用Adam优化算法,初始学习率设置为0.001,批处理大小为1 024,权重衰减参数设为0.000 65,对整个数据集迭代50次。
实验使用NVIDIA GTX1060显卡,64位Ubuntu系统,Intel i7-6700型号CPU,并Python3.5环境配置下使用开源深度学习框架Pytorch对网络模型进行训练。使用平均关节位置误差(Mean PerJoint Position Error,MPJPE)作为评价标准,即计算网络预测得到的关节点坐标与真实标签17个人体关节点坐标之间欧氏距离的平均值。为了与其他实验方法进行公平比较,根据协议使用Human3.6M中的S1、S5、S6、S7、S8子数据集用于训练,S9、S11数据集用于测试。
3.3 实验结果与分析三维人体姿态估计结果如图 4所示,每25帧连续图像的二维关节点坐标作为输入,采用4个残差模块网络结构的条件下,得到了最佳的实验结果。

|
| 图 4 三维姿态估计结果 Fig. 4 Three-dimensional pose estimation results |
为了充分评价本文方法在视频三维姿态估计上的有效性,首先将本文方法与目前的流行方法进行比较,在单个和平均动作误差上本文方法相比其他方法均有不同程度的提升,证明了基于一维卷积网络结构预测三维人体姿态相比其他方法具有一定的竞争力。为了验证本文方法的鲁棒性,还使用当前较为先进的二维姿态检测器CPN(Cascaded Pyramid Network)[21]来对视频中的人体二维关节点坐标进行检测,然后利用所设计的网络得到最终的三维姿态,结果表明本文方法在未提供二维关节点标注的情况下与二维姿态检测器结合同样能得到较为准确的输出,实验结果如表 2所示。另外本文还对两个不同方面进行了实验,一部分是采用不同数目连续帧的二维关节点坐标作为输入来探索序列长度对于视频三维姿态估计的影响;另一部分是验证本文的网络结构以及损失函数的改进对模型性能带来的提升。
| 方法 | 姿态误差/mm | 平均误差/mm | |||||||||||||||
| 指路 | 讨论 | 吃饭 | 问候 | 打电话 | 照相 | 摆姿势 | 购买 | 坐 | 坐下 | 抽烟 | 等待 | 遛狗 | 走路 | 散步 | |||
| 几何约束方法 | 文献[6] | 54.8 | 60.7 | 58.2 | 71.4 | 62.0 | 65.5 | 53.9 | 55.6 | 75.2 | 115.6 | 64.2 | 66.0 | 51.4 | 63.2 | 55.3 | 64.9 |
| 单幅图像方法 | 文献[7] | 58.6 | 64.6 | 63.7 | 62.4 | 66.9 | 70.7 | 57.7 | 62.5 | 76.8 | 103.5 | 65.7 | 61.6 | 69.0 | 56.4 | 59.5 | 66.9 |
| 二维姿态推断方法 | 文献[15] | 48.5 | 54.4 | 54.4 | 52.0 | 59.4 | 65.3 | 49.9 | 52.9 | 65.8 | 71.1 | 56.6 | 52.9 | 60.9 | 44.7 | 47.8 | 56.2 |
| 文献[12] | 53.3 | 46.8 | 58.6 | 61.2 | 56.0 | 76.1 | 58.1 | 48.9 | 55.6 | 73.4 | 60.3 | 62.2 | 61.9 | 35.8 | 51.1 | 57.5 | |
| 文献[16] | 52.8 | 54.8 | 54.2 | 54.3 | 61.8 | 67.2 | 53.1 | 53.6 | 71.7 | 86.7 | 61.5 | 53.4 | 61.6 | 47.1 | 53.4 | 48.3 | |
| 文献[1] | 37.7 | 44.4 | 40.3 | 42.1 | 48.2 | 54.9 | 44.4 | 42.1 | 54.6 | 58.0 | 45.1 | 46.4 | 47.6 | 36.4 | 40.4 | 45.5 | |
| 本文方法(真实值输入) | 35.4 | 43.0 | 37.9 | 40.0 | 44.4 | 52.1 | 41.7 | 40.4 | 51.8 | 68.4 | 42.0 | 46.0 | 47.4 | 36.4 | 38.4 | 44.3 | |
| 本文方法(CPN检测器输入) | 50.2 | 52.7 | 53.3 | 54.9 | 56.7 | 69.4 | 50.7 | 51.2 | 66.6 | 83.2 | 56.4 | 53.9 | 61.3 | 44.9 | 49.2 | 57.0 | |
对于不同数目连续帧输入的实验分析如图 5所示,当输入序列长度大于25以后,模型的性能开始下降,平均误差开始增加,推测原因可能因为当前帧的检测结果只与相邻几帧呈高度相关性,其余帧的存在会带来更多的冗余信息。而且由于输入维度的增加,网络前向传播所需的时间也会成倍增加。

|
| 图 5 不同输入序列下的平均误差 Fig. 5 Average errors in different input sequences |
接下来对本文设计的网络各个部分进行深入分析,表 3给出了不同的网络设计对最终测试误差的影响。Dropout[22]正则化是最简单的网络正则化方法:通过任意丢弃网络层中的参数来减少神经元之间复杂的共适应关系,迫使网络去学习更加鲁棒的特征,缓解过拟合的发生,起到正则化的作用。然而加入Dropout反而增加了大约10 mm的误差,分析原因,可能由于Dropout随机删除卷积层参数,破坏了一维卷积提取时序信息的连续特征过程。与此同时,BN层的加入减少了14.9 mm的测试误差,大幅提高了网络的泛化性能。另外,残差连接的设计也为本文的网络带来了0.6 mm误差的减小。
| 网络结构 | 平均误差/mm | 误差变化/mm |
| 原始网络 | 44.3 | |
| 加入Dropout(0.1) | 54.8 | +10.5 |
| 删除BN层 | 59.2 | +14.9 |
| 删除残差连接 | 44.9 | +0.6 |
最后分析本文所提出的损失函数对于网络性能的影响,具体方法为同时训练加入和不加入SPDC损失函数的网络,损失函数曲线如图 6所示。由图 6可见,在训练初期,随着三维点坐标回归的逐渐精确,两个网络的相似姿态位移差异同时减小,但加入SPDC损失函数的网络下降幅度更大。在继续迭代的过程中,加入SPDC损失函数网络的相似姿态位移差异进一步减小且具有更小的震荡幅度,这说明SPDC损失函数的加入使得网络很好地学习了视频帧间的连续性,增加了视频三维姿态估计输出的平滑性,另外,SPDC损失函数的加入最终减少了网络0.8 mm的误差,进一步提高了估计结果的准确性。

|
| 图 6 损失曲线对比 Fig. 6 Loss curves comparison |
本文结合用于提取时序信息的一维卷积神经网络,提出了一种基于视频的三维人体姿态估计方法。研究结论如下:
1) 本文方法能够以连续帧图像中人体二维关键点坐标作为输入,将已有的二维姿态准确地映射到三维空间中。
2) 针对帧间信息缺失的情况,本文又设计了一种新的损失函数,对帧间的近似一致性进行学习,充分利用视频时间维度上的相关性来估计视频中的三维人体姿态。
3) 实验表明,基于连续帧输入的姿态重建网络具有一定的合理性,并且本文方法可以与二维姿态检测器相结合,具有一定的鲁棒性。
下一步的主要研究工作是将本文方法与二维姿态估计任务相结合,设计通用的框架同时对二维和三维的人体姿态进行估计,并利用三维的姿态估计结果对二维的输出进行优化。
| [1] |
BO L, SMINCHISESCU C. Twin gaussian processes for structured prediction[J]. International Journal of Computer Vision, 2010, 87(1-2): 28. DOI:10.1007/s11263-008-0204-y |
| [2] |
RADWAN I, DHALL A, GOECKE R.Monocular image 3D human pose estimation under self-occlusion[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2013: 1888-1895.
|
| [3] |
ZHOU X, HUANG Q, SUN X, et al.Towards 3D human pose estimation in the wild: A weakly supervised approach[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 398-407.
|
| [4] |
PAVLAKOS G, ZHOU X, DERPANIS K G, et al.Coarse-to-fine volumetric prediction for single-image 3D human pose[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 7025-7034.
|
| [5] |
NEWELL A, YANG K, DENG J.Stacked hourglass networks for human pose estimation[C]//Proceedings of the European Conference on Computer Vision.Berlin: Springer, 2016: 483-499.
|
| [6] |
PAVLAKOS G, HU L, ZHOU X, et al.Learning to estimate 3D human pose and shape from a single color image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 459-468.
|
| [7] |
ROGEZ G, SCHMID C.Mocap-guided data augmentation for 3D pose estimation in the wild[C]//Advances in Neural Information Processing Systems, 2016: 3108-3116.
|
| [8] |
VAROL G, ROMERO J, MARTIN X, et al.Learning from synthetic humans[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 109-117.
|
| [9] |
CHEN C H, RAMANAN D.3D human pose estimation=2D pose estimation+matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 7035-7043.
|
| [10] |
BOGO F, KANAZAWA A, LASSNER C, et al.Keep it SMPL: Automatic estimation of 3D human pose and shape from a single image[C]//European Conference on Computer Vision.Berlin: Springer, 2016: 561-578.
|
| [11] |
PISHCHULIN L, INSAFUTDINOV E, TANG S, et al.Deepcut: Joint subset partition and labeling for multiperson pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 4929-4937.
|
| [12] |
LOPER M, MAHMOOD N, ROMERO J, et al. SMPL:A skinned multi-person linear model[J]. ACM Transactions on Graphics(TOG), 2015, 34(6): 248. |
| [13] |
LUVIZON D C, PICARD D, TABIA H.2D/3D pose estimation and action recognition using multitask deep learning[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 5137-5146.
|
| [14] |
MORENO-NOGUER F.3D human pose estimation from a single image via distance matrix regression[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2017: 2823-2832.
|
| [15] |
ZHOU X, ZHU M, LEONARDOS S, et al.Sparseness meets deepness: 3D human pose estimation from monocular video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 4966-4975.
|
| [16] |
MARTINEZ J, HOSSAIN R, ROMERO J, et al.A simple yet effective baseline for 3D human pose estimation[C]//Proceedings of the IEEE International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2017: 2640-2649.
|
| [17] |
DROVER D, MV R, CHEN C H, et al.Can 3D pose be learned from 2D projections alone?[C]//Proceedings of the European Conference on Computer Vision(ECCV).Berlin: Springer, 2018: 78-94.
|
| [18] |
OORD A, DIELEMAN S, ZEN H, et al.WaveNet: A generative model for raw audio[EB/OL].(2016-09-19)[2019-06-13].https: //arxiv.org/abs/1609.03499.
|
| [19] |
HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2016: 770-778.
|
| [20] |
IONESCU C, PAPAVA D, OLARU V, et al. Human3.6 M:Large scale datasets and predictive methods for 3D human sensing in natural environments[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 36(7): 1325-1339. |
| [21] |
CHEN Y, WANG Z, PENG Y, et al.Cascaded pyramid network for multi-person pose estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway, NJ: IEEE Press, 2018: 7103-7112.
|
| [22] |
SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout:A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958. |