



2. 电子科技大学 信息与通信工程学院, 成都 611731
2. School of Information and Communication Engineering, University of Electronic Science and Technology of China, Chengdu 611731, China
随着电子信息技术的高速发展和各种视频数据采集方式的使用,数字视频成为了多媒体信息的主要载体。然而,未经压缩的数字视频数据量非常巨大,如分辨率为4 000×2 000的8 bitRGB彩色视频,帧率为30 Hz,则其每小时的数据量高达2 531 GB。如此之大的数据量给视频的传输和存储带来巨大的挑战,因此自20世纪90年代以来,视频压缩技术持续成为国内外研究和应用的热点领域[1]。现代视频编码器采用一个包括预测、变换、量化和熵编码等多种压缩工具的混合视频编码框架,能有效去除视频数据中的空域冗余、时域冗余、视觉冗余等,从而实现较高的数据压缩。预测编码包括帧内预测和帧间预测,其中帧间预测利用了视频图像帧间相关性,根据运动矢量(Motion Vector, MV)和参考索引从重建帧中获得当前编码块的预测像素值。进一步地,相邻编码块的运动信息之间存在相关性,为了去除这种相关性从而减少用于编码运动信息的比特数,高效视频编码(High Efficiency Video Coding, HEVC)引入了高级运动矢量预测(Advanced Motion Vector Prediction, AMVP)、合并模式(merge mode)和跳过模式(skip mode)等技术[2]。视频编码器通过率失真优化(Rate Distortion Optimization, RDO)[3-5]为当前编码块选择最佳的预测模式,其数学表述为:min{J}, J=D+λmodeR。其中:J称为率失真代价;D和R分别为选择某一模式编码时得到的编码失真和编码码率(或比特数);λmode为拉格朗日乘子。模式选择过程中,率失真代价最小的预测模式被选择用于编码当前块。
如果当前编码块选择了合并模式,则其采用相邻块的运动矢量从参考帧中获得预测像素,因此不需要重复编码运动信息。合并模式节省了编码运动信息的比特数,在HEVC中实现了较高的率失真性能提升[6],该技术已被扩展应用到了下一代视频编码标准的开发中,新标准在联合视频专家组(Joint Video Experts Team, JVET)第10次会议后被正式命名为多功能视频编码(Versatile Video Coding, VVC)。近年来,研究人员针对视频编码中的合并模式提出了一些算法改进。HEVC采用基于四叉树的灵活块划分结构,每个编码树单元(Coding Tree Unit, CTU)被迭代地划分为许多编码单元(Coding Unit, CU),每个CU又进一步划分为1~2个预测单元(Prediction Unit, PU)。因此,针对大量预测块的模式选择需要极高的运算量。为了降低HEVC编码器的运算复杂度,文献[7-9]提出了不同的早期合并模式决策方法。在文献[7]中,根据不同划分深度子CU的模式与最大编码单元(Largest Coding Unit, LCU)最佳模式之间的相关性,设计快速算法。文献[8]提出基于率失真代价的统计模型用于早期合并模式决策,其减少了近一半的编码时间,但率失真性能损失较大。文献[9]分析了不同CU深度和量化系数值对应的率失真代价变化特点,采用自适应阈值减少合并模式候选进行RDO的次数,以降低编码器运算复杂度。为了便于合并模式在硬件编码器中的实现,文献[10]提出能减少运算量和存储要求的合并模式设计方法。针对三维高效视频编码(3D-HEVC),文献[11-13]提出了相应的早期合并模式判决方法。大部分关于合并模式的改进算法[14-16]都是以损失率失真性能为代价,降低编码器运算复杂度。以提升编码器率失真性能为目的的合并模式改进方法[17]相对较少。
通过分析合并模式的运动补偿预测残差分布特性,本文提出了一个附加的合并模式候选项,其预测像素值由空、时域候选的预测块加权得到。附加的合并模式候选项能获得更精确的预测像素值,减小了预测残差,从而节省编码残差变换系数的比特数。实验结果显示,本文算法能有效地改善编码器压缩性能。
1 视频编码中的合并模式虽然灵活的四叉树块划分结构更好地适应了视频内容,能有效去除时域冗余,然而细致的划分也导致需要编码的运动信息增加。为此,HEVC中提出了一种新的模式,即合并模式[6]。合并模式利用了空域和时域相邻编码块的运动相关性,不需要进行运动估计(Motion Estimation, ME),当前待编码块直接使用已编码块的运动信息进行运动补偿预测(Motion Compensation Prediction, MCP)。编码过程中,选择合并模式的PU仅需编码邻域PU复用索引,有效地减少了比特消耗。图 1为合并模式的流程。首先,根据空域和时域相邻已编码块的可用运动信息建立合并候选列表;然后,采用每个候选项的运动矢量对当前块进行运动补偿预测并编码计算率失真代价,其率失真代价最小的运动信息对应候选项即为最佳合并模式。

|
| 图 1 合并模式流程图 Fig. 1 Flowchart of merge mode |
合并模式候选列表来自于空域、时域已编码块的可用运动信息和附加生成的列表项,空域和时域中采用的相邻块位置如图 2所示。空域运动矢量候选有5个,时域运动矢量候选有2个,在HEVC中最多生成4个空域和1个时域合并候选列表。

|
| 图 2 合并模式候选块位置 Fig. 2 Location of merge mode candidates |
具体地,建立合并候选列表的步骤如图 3所示。其输出结果是当前块的合并候选列表,每个候选项具有不同的运动信息,被用于当前编码块的运动补偿预测。合并模式中,候选列表的个数由参数MaxNumMergeCands控制,其包含在码流中传输到解码端,在HEVC中设置合并列表数为5,在VVC的开发过程中,该候选列表数增加到7个。参照图 2和图 3,HEVC中合并候选列表的生成过程描述如下:

|
| 图 3 建立合并候选列表 Fig. 3 Construction of merge candidate list |
1) 生成空域运动矢量列表
空域运动矢量列表由图 2(a)中相应位置可用的PU生成,按照A1、B1、B0、A0、B2的顺序检测每个位置运动信息的可用性,若某个位置的PU是帧内预测方式或其位于别的Slice中,则其不可用。另外还有2种特殊的情况,运动信息不可用。一种情况是检测到当前相邻块的运动信息与之前已检测相邻块的运动信息相同,则标记为不可用,也就是合并列表不添加重复的运动信息。另一种情况是若CU划分为左右2个PU或上下2个PU,则右边PU或下方PU建立空域运动矢量列表时,对应于图 2(a)中的A1或B1不可用,这是因为左右2个PU运动信息相同或上下2个PU运动信息相同等价于CU采用了2N×2N的PU划分模式。最终按检测顺序至多选择4个可用的运动信息生成空域运动矢量列表。
2) 生成时域运动矢量列表
时域运动矢量列表由图 2(b)中邻近已编码帧的同位PU生成,首先检测TB位置的运动信息是否可用,若TB位置PU采用帧内预测或与其左上角PU不在同一个CTU内,则其运动信息不可用,然后检测TC位置PU的运动信息可用性。合并候选列表中仅生成一个时域运动矢量列表项,该时域运动矢量需要根据当前帧和同位PU所属帧各自与其参考帧之间的距离进行缩放。
3) 生成附加的候选列表
如果生成的空域运动矢量列表和时域运动矢量列表总数小于MaxNumMergeCands,则需要生成附加的候选列表,以使合并候选列表补齐到MaxNumMergeCands。对于B Slice,利用之前空域和时域生成的运动信息组合生成附加的候选运动矢量对。若之前步骤生成的合并候选列表长度仍小于MaxNumMergeCands,则添加0运动矢量使列表长度达到MaxNumMergeCands。
在进行RDO选择最佳合并候选项的过程中,每个候选列表项对应的当前块像素值由相应运动矢量通过运动补偿预测得到。式(1)表示单向预测中的运动补偿预测:
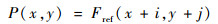
|
(1) |
式中:P(x, y)和Fref(x, y)分别为预测图像和参考图像;(i, j)为合并候选项中的运动矢量。双向预测则需要由2个运动矢量和对应的参考索引采用加权2个方向的预测值获得。
2 加权预测算法合并模式不需要进行耗时的运动估计,通过复用领域PU的运动矢量极大地节省了编码运动信息的比特数,从而为视频编码带来显著的压缩性能提升。然而合并模式仍然有进一步优化以提升编码性能的空间,因为合并模式中的运动补偿预测不够准确。直观地,更准确的运动补偿预测能减小PU的预测残差,从而降低编码中的量化失真,减少编码量化系数的比特数。本节首先分析了合并模式中预测残差的分布特征,然后提出了一种基于曼哈顿距离的加权预测作为合并模式的附加候选项,以进一步改善合并模式的性能。
2.1 合并模式中预测残差的分布合并模式决策过程中,每一个候选列表项的运动信息被用于运动补偿预测获得当前PU的残差块,如下:
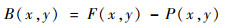
|
(2) |
式中:B(x, y)、F(x, y)和P(x, y)分别为当前PU的残差块、原始像素块和预测像素块。
直观地,2个像素点的运动相关性随着它们之间距离的增大逐渐变小,因此当前PU中的像素点运动矢量与合并候选项的运动矢量相关性随着像素点到邻域候选块的距离增大而减小。如式(1)所示的运动补偿预测中,越接近候选块的像素点将能获得越准确的预测像素值,反之,离候选块较远的像素点的预测误差会较大。
以图 2(a)中空域候选块B2为例,由于B2位于当前PU的左上方,当采用B2的运动矢量为当前PU进行运动补偿预测,则其残差块的残差幅度将呈现从上到下、从左到右逐渐增大的趋势。类似的不均匀分布也将出现在其他合并候选项的运动补偿预测残差块中。
为了验证如上分析,采用VVC开发过程中的联合探索测试模型(Joint Exploration Test Model 7.0, JEM 7.0)[18]编码视频序列BasketballDrill,编码器配置为低延迟P,量化参数(Quantization Parameter, QP)设置为22,编码帧数设置为前100帧。统计编码过程中使用合并模式,运动矢量来自同一空域候选位置的所有8×8残差块的残差绝对值之和,该统计数据能反映出残差幅度的分布特点。图 4(a)~(c)分别为运动矢量来自图 2(a)中候选块B2、B0、A0时的残差幅度统计分布。尽管由于不同位置的候选块被选择作为最佳合并模式的次数不同,导致图 4中的统计数值差异较大,但它们的残差幅度分布规律与前面的分析基本一致。即随着像素点位置与候选块的距离增加,相应的预测残差幅度变大。

|
| 图 4 不同位置合并候选项进行运动补偿预测后的残差幅度统计分布 Fig. 4 Statistical distribution for residual magnitudes after MCP of merge candidates at different locations |
从2.1节的分析可知,由于当前PU中不同像素点运动与候选块运动相关程度不同,导致合并模式中的运动补偿预测不够精确。为了充分利用像素间随着距离变化的运动相关性,本节提出一种基于曼哈顿距离的加权预测作为合并模式的附加候选项,其预测块由可用的不同位置候选项预测块加权得到。所提出附加合并候选项的流程如图 5所示,具体步骤如下:

|
| 图 5 附加合并候选项的流程图 Fig. 5 Flowchart of additional merge candidate |
1) 检测邻域合并候选块
如图 2中合并模式候选块位置所示,按A1、B1、B0、A0、B2、TB的顺序检测不同位置候选块是否可用,并生成相应的运动矢量。如果生成的运动矢量数小于2,则不执行本文算法,否则执行本文算法。需要指出的是,时域候选块TC并不包括在所提加权算法中,因为TC与当前PU中所有像素点的距离相同。
2) 运动补偿预测
采用步骤1)生成的运动矢量根据式(1)进行运动补偿预测获得相应的预测块,记为Pi(x, y)。
3) 加权预测
根据2.1节的分析可知,由步骤2)得到的多个预测块具有不同的残差幅度分布特点,随着像素点位置与候选块的距离越远,残差幅度相对变得越大。因此,本文提出使用曼哈顿距离度量像素间随着距离变化的运动相关性。
曼哈顿距离表示2个点在标准坐标系上的绝对轴距之和,二维平面上两点a(x1, y1)与b(x2, y2)之间的曼哈顿距离定义为
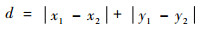
|
(3) |
所提附加合并候选项的预测块由式(4)加权得到:
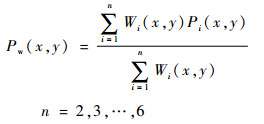
|
(4) |
式中:Wi(x, y)为每个预测块Pi(x, y)对应的权重,其设置与候选块的位置有关。每个像素点的权重值随着它与候选块的曼哈顿距离增大而减小,具体设置如表 1所示,其中H和W分别为当前预测块的高和宽。
| 候选块的位置 | Wi(x, y) |
| A1 | W-x+y |
| B1 | H-y+x |
| B0 | H-y+x |
| A0 | W-x+y |
| B2 | W-x+H-y+1 |
| TB | x+y+1 |
4) 最佳合并模式选择
计算所提附加候选项的率失真代价,并与原始合并候选列表中的率失真代价对比选择出最佳合并模式。在联合探索测试模型JEM 7.0中,合并候选项的索引号范围为0~6,因此所提附加候选项索引号设置为7。若所提附加候选项最终被选择作为当前PU的编码模式,则相应的合并索引号7被编码并传至解码端,解码端将采用与编码端一致的加权方法重建编码块。
需要说明是的,若当前PU最终选择所提附加合并候选项编码,则当前PU没有明确的运动信息。为便于后续编码过程中当前PU被用于导出其他编码块的运动矢量,需要对当前PU设置一个确定的运动矢量,本文算法采用步骤1)中检测到的第一个可用候选块运动信息作为当前PU的运动信息。
3 实验验证为验证本文算法的有效性,将提出的基于曼哈顿距离加权预测算法集成到联合探索测试模型JEM 7.0,该测试软件是由JVET在HEVC测试模型(HEVCTestModel, HM)基础上开发的,用于评估新的编码工具和技术改进。测试序列使用JVET通用测试条件(Common Test Conditions, CTC)和软件参考配置[19]建议的Class B、Class C、Class D、Class E中的16个视频和Class F的4个可选视频。实验测试了低延迟P(Low Delay P, LDP)、低延迟B(Low Delay B, LDB)、随机接入(Random Access, RA)3种编码器配置,依据CTC设置QP分别为37、32、27、22编码每一个测试序列。需要说明的是,Class E是会议视频序列,根据CTC建议,RA配置下测试序列不包括Class E中的3个视频。以原始的JEM 7.0编码器作为基准,计算本文算法输出Y、U、V分量的BDBR,BDBR表示在相同的峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)条件下,测试算法相对于基准算法的码率节省百分比,若其值为负则表示性能增益,反之表示性能损失。
表 2列出了3种编码器配置下的全部测试序列BDBR,数据显示本文算法在3种编码器配置下都获得了率失真性能提升。其中,LDP的性能平均提升达1.34%,比LDB和RA配置的性能提升大许多,这是因为B帧采用的双向预测比P帧的单向预测准确,对于B帧可提升的预测准确度空间比较有限。另外,Class F是屏幕内容视频,其编码块中的像素运动相关性很强,基本不随距离大小变化。因此,对于Class F本文基于距离的加权预测获得性能改善不显著。对于实验数据中显示在LDB和RA配置下,个别测试序列出现率失真性能损失,其原因是由于本文算法为传输附加合并候选索引,增加了合并模式的编码比特,而对于这些特殊的视频,基于距离的加权预测提高的预测精确度比较小。
| Class | 测试序列 | LDP | LDB | RA | ||||||||
| Y | U | V | Y | U | V | Y | U | V | ||||
| B | Kimono | -0.32 | -0.29 | -0.56 | -0.07 | -0.10 | 0.02 | -0.07 | 0.11 | 0.04 | ||
| ParkScene | -0.36 | -1.35 | -0.83 | 0.08 | 0.23 | 0.30 | -0.03 | -0.39 | -0.42 | |||
| Cactus | -1.66 | -3.01 | -2.57 | -0.17 | -0.37 | -0.90 | -0.26 | -0.64 | -0.46 | |||
| BasketballDrive | -1.18 | -2.20 | -2.27 | -0.27 | -0.77 | -0.52 | -0.15 | -0.38 | -0.02 | |||
| BQTerrace | -6.98 | -5.93 | -5.02 | -0.40 | -0.76 | -0.57 | -0.61 | -0.71 | -0.94 | |||
| C | BasketballDrill | -1.58 | -2.12 | -2.69 | -0.05 | 0.02 | -0.17 | -0.21 | -0.02 | -0.13 | ||
| BQMall | -0.56 | -0.86 | -0.66 | -0.01 | -0.79 | -0.24 | -0.08 | -0.40 | 0.15 | |||
| PartyScene | -1.59 | -1.66 | -1.17 | -0.33 | -0.43 | -0.19 | -0.24 | 0 | -0.16 | |||
| RaceHorses | -0.89 | -1.87 | -2.04 | -0.08 | -0.33 | -0.54 | -0.13 | -0.28 | -0.24 | |||
| D | BasketballPass | -0.29 | -0.53 | -0.86 | -0.01 | -1.39 | -0.60 | -0.08 | -0.26 | -0.02 | ||
| BQSquare | -3.37 | -5.00 | -3.32 | -0.36 | -0.20 | -1.26 | -0.27 | -0.03 | 0 | |||
| BlowingBubbles | -0.84 | -0.94 | -1.24 | -0.23 | -0.58 | -0.67 | -0.04 | -0.01 | -0.22 | |||
| RaceHorses | -0.12 | -0.12 | 0.08 | -0.01 | -0.36 | -0.45 | 0.02 | -0.21 | -0.23 | |||
| E | FourPeople | -1.27 | -1.17 | -0.67 | -0.29 | -1.60 | -2.66 | — | — | — | ||
| Johnny | -2.59 | -3.99 | -3.59 | -0.03 | -0.59 | -0.52 | — | — | — | |||
| KristenAndSara | -1.10 | -3.75 | -3.70 | 0.09 | -0.67 | 0.09 | — | — | — | |||
| F | BasketballDrillText | -1.31 | -0.98 | -1.19 | -0.15 | -0.40 | -0.29 | -0.23 | -0.04 | -0.35 | ||
| ChinaSpeed | -0.29 | -1.37 | -1.02 | -0.08 | -0.27 | -0.24 | -0.09 | -0.16 | -0.25 | |||
| SlideEditing | -0.28 | -0.15 | -0.18 | -0.02 | -0.31 | -0.61 | 0.04 | 0.03 | 0.01 | |||
| SlideShow | -0.16 | -0.89 | 0.46 | 0.49 | 1.84 | 0.63 | -0.30 | -0.41 | -0.19 | |||
| 平均 | -1.34 | -1.91 | -1.65 | -0.10 | -0.39 | -0.47 | -0.16 | -0.22 | -0.20 | |||
LDP编码配置下部分测试序列的率失真性能提升很大,如测试序列BQTerrace的码率节省高达6.98%。图 6给出了性能改善较为显著的测试序列BQTerrace、BasketballDrill、BQSquare、Johnny的率失真曲线对比。可看出,本文算法在低码率和高码率下均优于原始的JEM 7.0。

|
| 图 6 率失真曲线对比 Fig. 6 Comparison for rate-distortion curves |
1) 本文分析了合并模式空域、时域不同候选块运动信息与当前待编码PU中不同位置像素点运动信息的相关性,并通过实验统计证实随着PU中像素点距候选块的距离增加,运动补偿预测后的残差幅度增大。
2) 提出了一种基于曼哈顿距离的加权预测算法生成附加合并候选项,其充分利用了所有可用候选块的运动信息,根据每个可用候选块与当前待编码PU中像素点的曼哈顿距离设置加权预测的权重,该加权预测获得了更准确的预测块,从而减小量化失真和编码量化系数的比特数。
3) 实验结果显示,在LDP、LDB和RA编码结构下,本文算法均获得了率失真性能提升。特别地,对于LDP配置,相比原始JEM 7.0编码器,本文算法获得了平均1.34%的码率节省,最高达到6.98%。
| [1] |
马思伟. AVS视频编码标准技术回顾及最新进展[J]. 计算机研究与发展, 2015, 52(1): 27-37. MA S W. History and recent developments of AVS video coding standards[J]. Journal of Computer Research and Development, 2015, 52(1): 27-37. (in Chinese) |
| [2] |
SULLIVAN G J, OHM J R, HAN W J, et al. Overview of the high efficiency video coding(HEVC) standard[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2012, 22(12): 1649-1668. DOI:10.1109/TCSVT.2012.2221191 |
| [3] |
GAO Y, ZHU C, LI S, et al. Temporal dependent rate-distortion optimization for low-delay hierarchical video coding[J]. IEEE Transactions on Image Processing, 2017, 26(9): 4457-4470. DOI:10.1109/TIP.2017.2713598 |
| [4] |
LI S, ZHU C, GAO Y B, et al. Lagrangian multiplier adaptation for rate-distortion optimization with inter-frame dependency[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(1): 117-129. DOI:10.1109/TCSVT.2015.2450131 |
| [5] |
LI S, ZHU C, GAO Y, et al.Inter-frame dependent rate-distortion optimization using Lagrangian multiplier adaption[C]//Proceedings of IEEE International Conference on Multimedia and Expo(ICME).Piscataway, NJ: IEEE Press, 2015: 1-6.
|
| [6] |
HELLE P, OUDIN S, BROSS B, et al. Block merging for quadtree-based partitioning in HEVC[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2012, 22(12): 1720-1731. DOI:10.1109/TCSVT.2012.2223051 |
| [7] |
PAN Z Q, KWONG S, SUN M T, et al. Early merge mode decision based on motion estimation and hierarchical depth correlation for HEVC[J]. IEEE Transactions on Broadcasting, 2014, 60(2): 405-412. DOI:10.1109/TBC.2014.2321682 |
| [8] |
TARIQ J, KWONG S, YUAN H. Spatial/temporal motion consistency based merge mode early decision for HEVC[J]. Journal of Visual Communication and Image Representation, 2017, 44: 198-213. DOI:10.1016/j.jvcir.2017.01.029 |
| [9] |
蒋洁, 叶德周, 潘勉. 一种基于自适应阈值的Merge模式快速选择方法[J]. 光电子·激光, 2016, 27(9): 980-986. JIANG J, YE D Z, PAN M. A fast candidate selection method for Merge mode based on adaptive threshold[J]. Journal of Optoelectronics·Laser, 2016, 27(9): 980-986. (in Chinese) |
| [10] |
KIM T S, RHEE C E, LEE H J. Merge mode estimation for a hardware-based HEVC encoder[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016, 26(1): 195-209. DOI:10.1109/TCSVT.2015.2496820 |
| [11] |
SONG Y X, JIA K B. Early merge mode decision for texture coding in 3D-HEVC[J]. Journal of Visual Communication and Image Representation, 2015, 33: 60-68. DOI:10.1016/j.jvcir.2015.07.001 |
| [12] |
HEO Y S, BANG G, PARK G H. Adaptive merge list construction for 3D-HEVC fast encoder[J]. Electronics Letters, 2016, 52(8): 604-690. DOI:10.1049/el.2015.4323 |
| [13] |
宋雨新, 贾克斌, 吴强. 3D-HEVC合并模式快速判决方法研究[J]. 信号处理, 2016, 32(1): 46-55. SONG Y X, JIA K B, WU Q. Research on fast merge mode decision method for 3D-HEVC[J]. Journal of Signal Processing, 2016, 32(1): 46-55. (in Chinese) |
| [14] |
WU J F, GUO B L, HOU J, et al. Fast CU encoding schemes based on merge mode and motion estimation for HEVC inter prediction[J]. KSII Transactions on Internet and Information Systems, 2016, 10(3): 1195-1211. |
| [15] |
CHENG Z X, SUN H M, ZHOU D J, et al. Accelerating HEVC inter prediction with improved merge mode handling[J]. IEICE Transactions on Fundamentals of Electronics Communications and Computer Sciences, 2017, 100(2): 546-554. |
| [16] |
VANNE J, VIITANEN M, HAMALAINEN T D. Efficient mode decision schemes for HEVC inter prediction[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2014, 24(9): 1579-1593. DOI:10.1109/TCSVT.2014.2308453 |
| [17] |
ZHANG N, FAN X P, ZHAO D B, et al. Merge mode for deformable block motion information derivation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(11): 2437-2449. DOI:10.1109/TCSVT.2016.2589818 |
| [18] |
CHEN J, ALSHINA E, SULLIVAN G J, et al.Algorithm description of joint exploration test model 7(JEM 7)[C]//Joint Video Exploration Team(JVET) of ITU-T SG16WP3 and ISO/IEC JTC 1/SC 29/WG 117th Meeting, 2017: 10-15.
|
| [19] |
SUEHRING K, LI X.JVET common test conditions and software reference configurations[C]//Joint Video Exploration Team (JVET) of ITU-T SG16WP3 and ISO/IEC JTC 1/SC 29/WG112nd Meeting, 2016: 1-4.
|