



在航空发动机的故障预测中,由于其系统复杂,长时间处于高温度、高速度等困难环境下,不仅部件更易损坏,而且故障的预测也更为困难。现有的轴承故障预测方法大多选择在实验状态下测试,数据都在低负载、低速度以及常温常压下采集,对比发动机内环境过于温和,而在发动机内部的轴承振动数据又面临具体故障的已标记样本获取难度大以及过拟合等问题。
在基于神经网络的轴承故障预测领域中,机器学习一直面临着可用样本不足、过拟合等问题,大多数情况下,标签数据的获取成本很高,而未标记的数据则很容易获得而且数量更多。基于这个原因,半监督学习(Semi-Supervised Learning, SSL)获得了越来越多的关注,其致力于从未标记样本中获得信息,寻找大量的未标记数据中的规律,再利用少部分已标记数据的信息,做出预测。大多数现有的半监督学习技术主要是在未标记数据的信息获取方式上加以区别。半监督学习方法中,少量的有标记样本其实是训练学习的核心,过拟合的效果很难消除,同时随着信息的增加,新增的未标记样本也未必严格与已标记样本同分布。
知识迁移就是一种能够打破同分布样本的假设,极大地增加机器学习的跨领域能力,提取更多的样本用于训练。而并非所有的迁移都会提升预测效果,无价值或不相关的信息的迁入只会造成预测效果大打折扣。
房晓南[1]提出了半监督框架下的自标记技术和多学习器模型的结合方法,来解决欠标记且不平衡的垃圾网页数据集分类问题, 是解决只有少量标记且类不平衡数据集分类问题的一个有效策略。杨印卫[2]选取了支持向量机(SVM)、隐马尔可夫模型(HMM)以及径向基函数(RBF)神经网络这3个单学习器作为异构集成学习模型的基分器,同时采用了majority voting和stacking两种集成结果整合策略来选择最优组合,证明异构集成学习模型的泛化能力相比于以往单分类模型得到了改善,同时模型复杂度降低。张伟[3]利用卷积神经网络(Convolutional Neural Network,CNN)识别振动信号的时域图,引入了自适应批量归一化算法,取得了良好的变负载自适应性能。
郭勇[4]给出了一种基于简单投票制的样本迁移学习方法,有效提高了目标领域预测学习器的分类效果。对TrAdaBoost算法进行了权值更新策略方面的改进,解决了TrAdaBoost算法源领域与目标领域样本权值之间易出现的两极分化问题。然后以基于迁移成分分析(Transfer Component Analysis, TCA)的域匹配算法为基础,对其进行了归纳式扩展,并结合聚类算法对源领域数据集数据分布作进一步修正。
上述算法并未同时解决负迁移以及过拟合的问题,基于此,本文采用基于迁移学习的半监督集成算法,利用高相似度样本的迁移提高半监督学习的精度,同时利用半监督算法筛选迁移学习的高相似度样本,最大限度地防止负迁移的发生。
1 机器学习 1.1 半监督学习在半监督的发展中,最早提出的是自训练以及直推学习,但训练出的学习器鲁棒性极差,然后是协同训练算法,这种算法的一个主要困难是它需要2个完全独立的视图,在大多数的学习问题中很难满足这一要求。此外,在协同训练中,值得信赖的样本的估计是通过交叉验证进行的,这是一个耗时的过程。为了克服这些困难,Zhou和Li[5]提出了三重训练算法,三重训练的思想是训练3个训练集,依此3个训练集生成3个学习器,而且无需满足苛刻的独立条件,然后使用其他2个学习器同意的未标记数据对另一个学习器进行改进,由于未标记数据的分类误差估计比较困难,因此,在未标记数据与标记数据具有相同分布的前提下,仅对标记数据进行分类误差估计。3次训练过程的训练一直持续到误差停止减小为止,这意味着已经达到了最大的泛化效果。在一定的理论证明限制下,将一致的未标记样本逐步加入到标记数据中,用于细化相应的学习器,直到没有一个学习器的预测误差进一步减小,一旦训练过程完成,就可以用2个或多个成员学习器一致同意的标签来预测未标记或看不见的数据[6]。
1.2 迁移学习迁移学习的目的在于将已有的知识恰当地引入到新领域中,使机器能够获得“举一反三”的能力[7]。本文将源领域DS定义为“一”,将目标领域DT定义为“三”,也就是将DS的学习经验迁移到DT中来。其中迁移的有效性很大程度上依赖于领域间的相似程度,当相差过大时,就会发生负迁移,降低学习性能。迁移学习可以划分为5类:基于实例的迁移,基于参数的迁移,基于特征的迁移,给予相关知识的迁移以及基于模型的迁移。
1.3 基于强化学习的极限学习机极限学习机(ELM)是一种神经网络监督学习算法,采用基于有限集的局部逼近,收敛速度快,可以代替强化学习中Q值等于实现状态动作到Q值的映射。Q学习是强化学习的一种,在模型未知时通过估计Q值来实现目的[8]。
Q值函数更新公式为
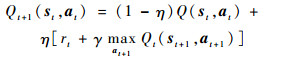
|
(1) |
式中:η为学习速度;γ为折扣因子,影响决策的远视程度;st为t时刻的状态;at为t时刻的动作;rt为t时刻奖赏;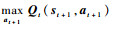
随机设定输入权值矩阵α以及偏置项β;计算隐含层输出矩阵H,以及输出量Q=Hw1,w1为权值向量,Q=[Q1,Q2, …, QL]T为对应L个动作的估计Q值向量,再通过广义逆矩阵获取权值w1。
1.4 集成学习集成学习是一种机器学习方法,最初,集成学习的提出是由于Schapire证明了多个弱学习器可以形成一个强学习器,集成学习的目的是通过组合多个学习器的输出来构造多个不同的学习器,如图 1所示[9]。所谓“集成”是专家的混合体,用以防止过度拟合以及减少所有基础学习器的误差,而如何结合多种学习器的输出结果和提高基学习器的多样性来提高学习器的精度是重点。为了提高集成的精度和稳定性,人们开发了不同的技术。这些技术因所使用的培训数据、所使用算法的类型以及所遵循的组合方法而有所不同。所谓的异构集成学习器就是构造不同种类的基学习器,然后进行集成,多重训练的异构集成学习器便是取多个基学习器分别训练学习,最后对所有预测结果进行组合。

异构集成学习器的关键是根据所有基学习器的预测来量化未标记样本的置信度,而精度也随学习器的数量增加而增加,而且对所有的训练集以及算法没有要求,避免了大量交叉验证。
2 基于迁移学习的支持向量机与极限学习机 2.1 基于迁移学习的支持向量机一般来讲基于SVM的迁移学习直接利用2个领域的数据构建模型,但是面临着目标方程很难优化的问题,并且无法有效剔除源领域中的噪声影响,随着源领域数据的增多,算法复杂度将大大提高,由此本文提出筛选源领域相似度高的数据进行迁移的SVM算法,思想如下:
源领域与目标领域的高相似度势必会导致2个分类超平面过于接近,本文选取决定2个领域分类超平面的支持向量来进行筛选数据,从而最大程度降低负迁移的发生。源领域DS,以及目标领域DT分别为

|
(2) |

|
(3) |
如果本文借鉴欧氏距离[10]的概念定义了一个函数σ(VSj, DTt)来衡量数据的相似性,其中VSj为源领域的支持向量,β用于控制VS的重要程度,||VSj-xi||22表示VS与DTt的距离。

|
(4) |
式中:k为目标训练集个数。
具体步骤如下:
1) 使用DS中的数据训练初始SVM,得到支持向量VS,并计算相似度σ(VSj, DTt)。
2) 将VS加入到源领域数据的已标记数据中,将相似度函数考虑进支持向量机的目标函数中,构造出如下新的优化问题:
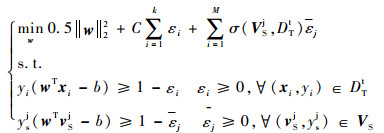
|
(5) |
式中:w为分类超平面权值向量; b为偏置。
3) 将支持向量通过惩罚项C与目标领域形成新的训练集D用以训练新的学习器,引入拉格朗日系数将上述约束问题转化为对偶问题:
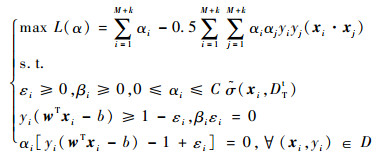
|
(6) |
式中:M为已标记样本数量。
4) 求解上述问题得到最优解α*,以及最优分类平面权向量w*,b以及最终分类函数f(x)如下,根据f(x),得到最终学习器。
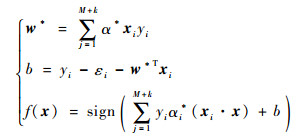
|
(7) |
基于强化学习的迁移极限学习机通过贝叶斯理论计算目标任务与源任务的相似度,依此衡量迁移的数量,继续求出源任务各样本属于目标样本的概率并降序排列确定有效迁移样本。
迁移学习的核心在于选择合适的源任务添加进训练集中[11],本文通过计算源任务与目标领域的相似度来对源任务目标进行排序筛选。具体方式如下。
首先定义Si为源任务,T为目标任务,
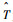
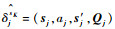

具体步骤如下:
1) 执行动作ai,由式(8)和式(9)计算第K个源任务中第j个样本与目标任务中第i个样本的状态相似度以及回报相似度:
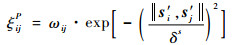
|
(8) |
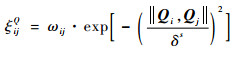
|
(9) |
2) 计算第K个源任务中第j个样本属于目标任务的概率:

|
(10) |
式中:nT为从T个训练集中已迁移样本数。
3) 获取任务相似度,并且从每一个源任务中按照相似度排序选取(删除“个”)样本到目标样本集:
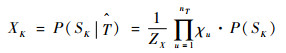
|
(11) |
式中:χu为状态回报相似度的匹配度。
4) 使用新的训练集对ELM进行训练更新。
循环以上步骤直到达到最大迭代次数。
2.3 基于迁移学习的三重训练学习器在Tri-Training的基础上引入迁移学习,需要强学习器对源领域样本进行筛选,比较弱学习器选择的样本进行迭代更新,通过判断弱学习器选择的样本与上一轮是否一致来调整样本权重以及对目标任务学习的影响,这里不再赘述具体步骤[12]。
3 基于迁移学习的半监督集成学习器集成学习可以综合多个基学习器的优势,这是其优势,但会因此集成到对结果有负面影响的基学习器,因此本文需要为基学习器设置权值,并根据错误率实时更新权值最大限度地降低基学习器的负面作用。
根据图 2的学习器构造方式,集成最终的学习器。

|
| 图 2 学习器构造方式图 Fig. 2 Learning device structure diagram |
参考图 2,具体的步骤如下:
步骤1 通过boosting方法将已标记样本L(xi,yi)构造为具有差异性训练集的L1到L6,同样的方法将未标记样本U(xj)构造得到训练集U1到U3,定义目标领域样本集D1到D3。
步骤2 根据训练集L1到L3分别训练得到基学习器SVM、ELM、Tri-training。再按照上述改进的迁移学习算法通过训练集L2和D1、L4和D2、L6和D3分别获得迁移学习的支持向量机(TSVM)、基于迁移学习的极限学习机(TELM)和基于迁移学习的三重训练学习器(TTri-training)。
步骤3 将未标记样本U1通过SVM以及TSVM进行识别,若两学习器对样本x1j判别结果相同都为y1j,则将样本分类结果(x1i,y1i)添加到L7中,同理将U2通过ELM以及TELM进行识别,获得已标记样本L8,同理获得L9。
步骤4 将L7、L1以及D1中迁移学习过程中认可的目标样本共同训练得到半监支持向量(Semi-supervised Support Vector Machines, SSVM)、半监督极限学习器(Semi-supervised Extreme Learning Machine, SELM)以及半监督三重训练学习器(Semi-supervised Triple training learning machine, STri-training)。
步骤5 将U4(x4j)通过3个半监督基学习器SSVM、SELM以及STri-training进行识别,按照式(12)集成其识别结果,将集成结果加入到L10(x10k,y10k)中,将L10用于测试基学习器的错误率εi,如式(13),并以错误率获得基学习器权重ωi。
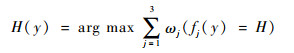
|
(12) |
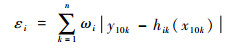
|
(13) |
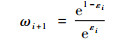
|
(14) |
式中:H(y)为预测结果函数; ωj为第j个半监督集成学习器的权重,等于其2个同簇初始基学习器权重ωi相加; hik(x10k)为第i个初始基学习器对L10中第k个样本的识别结果。
步骤6 不断调整学习器权重并实时记录学习器误差,直到权重以及误差都稳定得到稳定的半监督基学习器,并按照稳定后的权值集成最终学习器。
在上述算法中,为便于理解,通过示意图 3阐述在上述步骤中使用的半监督学习算法流程,图 4为TSVM的构造方式,图 5为TELM的构造方式。其中集成算法的步骤可参考文献[2]。

|
| 图 3 半监督算法构造示意图 Fig. 3 Schematic diagram of semi-supervision algorithm construction |

|
| 图 4 TSVM算法示意图 Fig. 4 Schematic diagram of TSVM algorithm |

|
| 图 5 TELM算法示意图 Fig. 5 Schematic diagram of TELM algorithm |
相比于其他算法,基于迁移学习的集成学习器的优点有:
1) 提出改进迁移学习器加入到基学习器中。
2) 利用改进的迁移学习器提高半监督学习的精度。
3) 利用半监督学习调整迁移学习的效率。
4) 集成方式上可以在运算中调整各学习器权值,进行增量式学习,进一步提升学习器性能。
4 仿真实例为验证算法的有效性,本文在2个数据集中分别进行实验。在字母识别数据集中,主要验证算法在分类识别上的效果,量化半监督学习方法与迁移学习方法间的相互影响,调整算法中的参数以及分析各基分类器的精度变化。在发动机轴承数据集中主要验证本文方法在轴承故障识别的效果,寻找最优的迁移数据以及半监督数据。
4.1 公共数据集实验为了测试最终学习器的性能,本文在机器学习存储库(UCI)的字母识别数据集上进行了模拟[13]。选取26个字母中A~E个字母为源任务,选取F~N为目标领域样本,具体的样本特征如表 1所示。
| 数据集 | 字母 | 样本数 | 字母数 |
| L | A~E | 100 | 5 |
| U | A~E | 400 | 5 |
| L1-L6 | A~E | 30 | 5 |
| U1-U3 | A~E | 120 | 5 |
| D1 | F,G,H | 400 | 3 |
| D2 | I,G,K | 400 | 3 |
| D3 | L,M,N | 400 | 3 |
| 合计 | A~N | 1850 | 29 |
实验采用RBF为基分类算法,隐藏节点取20,每次实验做5次取其平均值,设定初始基学习器的权重都为1/6,已标记样本数量、未标记样本与迁移样本比例为1:4:4。安排单纯的半监督神经网络以及基于迁移学习的学习器作为对比。
图 6为误差稳定后基学习器以及集成学习器的预测精度变化。从图中可见,分类效果经过迁移学习以及半监督学习后有显著的提升,无论是稳定性还是精度都大幅优于单一的学习器,而且经过少量的样本的训练后精度就达到了良好的效果,而单独的迁移学习或半监督学习都无法做到。这是由于基于迁移学习的半监督集成学习器(SSIT)可以更充分利用样本的信息,无需大量迭代就会达到良好的效果。

|
| 图 6 预测精度变化 Fig. 6 Prediction accuracy change |
图 7为基学习器权重变化,经由错误率的调整后可以看出,迁移学习器的权重都由于可以提取目标样本的信息而逐渐提高,三重训练器权重不断拔高。若本文保持初始权值恒定,预测精度会下降大约8%。据此本文也调整初始学习器权重,使其在训练过程中减轻权重变化的迭代,可以更快地达到稳定的预测精度。

|
| 图 7 基学习器权重变化 Fig. 7 Base learning device weight change |
本文通过调整实验找到精度提升的原因。图 8为调整未标记样本U的数量,对比迁移学习器的精度,可以发现无标记样本对于迁移学习的效果有较大的影响,在没有无标记样本时,也就是不进行半监督学习时,预测精度下降了大约10%。随着无标记样本的增加,迁移学习器精度以及迁移数量都会稳步提升,这是因为无标记样本的训练信息可以筛选目标领域中的高相似度样本,保证迁移学习的效果。但精度的增加有一个上限,这是由于少量的有标记样本仍然是训练的核心,仍然会有过拟合的作用。数量的增长也有上限,因为目标领域内高相似度样本数量也有限。

|
| 图 8 迁移学习器精度变化 Fig. 8 Transfer base learning device accuracy change |
同理本文保持U的数量恒定,调整D中的样本数量,如图 9和图 10所示,发现若是没有迁移目标领域的样本,半监督学习效果的稳定性很差,最大最小精度之间有较大差异,这是由于半监督学习一旦做出错误的判断便会“一错再错”,自身很难纠正,需要目标领域样本来调整,随着迁移样本的增加,预测精度稳步增加且趋于稳定,最大最小精度差异也下降到2%左右。

|
| 图 9 迁移数量变化 Fig. 9 Transfer data change |

|
| 图 10 半监督学习精度变化 Fig. 10 Semi-supervised learning accuracy change |
继续调整已标记样本的比例,图 11为SSIT学习器精度变化。已标记样本的增加固然可以提高辨识度,但过多的已标记样本可以保持最高精度,但平均精度反而有所下降,这是由于学习器过于追求少量的已标记样本,过拟合效果增大,鲁棒性也下降,反而不易对大量复杂的样本进行预测。在已标记样本比较少时,SSIT仍然表现表现出稳定的预测性能,而单独的半监督或迁移学习算法却受到极大影响,这是因为SSIT并不依赖那些少量的已标记样本,可以从目标领域以及未标记样本中提取到充足的信息来保证预测精度。

|
| 图 11 精度随已标记样本比例变化 Fig. 11 Change of accuracy with labeled sample scale |
在公共数据集上的实验验证了所提算法对迁移以及半监督效果的改进作用,但对于具体的发动机内数据效果犹未可知,接下来本文搭建接近航空发动机内部的轴承振动试验设备对轴承故障进行诊断,实验具体设置如下。
本文搭建航空发动机机转子实验平台进行模拟实验,其模拟了真实发动机的内部结构,达到真实发动机的振动效果,图 12为发动机实验平台内部结构,图 13为迁移实验平台示意图。选择型号6205的轴承,滚动体9个。在模拟发动机50000磅(22.68t)推力下通过加速度传感器收集3种轴承故障(内圈、外圈、滚动体)以及正常情况下的轴承振动数据各1000组。

|
| 图 12 发动机转子实验平台内部结构 Fig. 12 Internal structure of engine rotor experimental platform |

|
| 图 13 迁移轴承实验平台示意图 Fig. 13 Schematic diagram of transfer bearing test rig |
模拟发动机最大推力63800磅下轴承振动数据500组作为迁移领域D1,模拟50000磅推力下同位置6206型号轴承振动数据500组为D2,取来自凯斯西储大学轴承数据库型号6205轴承在负载746W、转速2000r/min下轴承振动数据500组为D3。
首先利用包络谱的方法提取振动信号的具体特征[14],其中载波频率为5000Hz,将通过得到的分量组成特征矩阵并采用奇异值分解方法求得对应的特征向量,于是每个样本信号都有对应的特征向量作为训练的输入。图 14和图 15分别为内圈故障振动信号时域波形以及包络图。

|
| 图 14 时域波形图 Fig. 14 Time domain waveform |

|
| 图 15 包络谱分析 Fig. 15 Envelope spectrum analysis |
通过上述方法将振动信息提取为特征向量,得到带有故障结果的轴承振动特征向量数据集L,以及无故障结果的数据集U以及迁移数据D。为检验算法的有效性,本文采用同样数量已标记样本的训练样本以及相同的测试样本,分别使用基学习器、CNN以及基于距离的谱聚类(SL)算法[15]进行对比测试[16],其中采用同样特征提取方法将特征向量的输入到训练好的TELM中进行诊断,再利用卷积神将网络提取振动信号的包络谱进行学习,保证特征的提取程度不变。
将训练成熟后的学习器输入测试样本的特征向量,根据输出向量的值进行故障预测,其中信号类型中1、2、3、4等分别代表无故障,内圈故障,外圈故障以及滚珠故障。图 16为在不同方法对样本的预测结果与实际结果的对比。

|
| 图 16 不同方法对故障的预测结果 Fig. 16 Fault prediction result by different methods |
选取不同的测试样本分别测试5次,表 2为在不同数据集合方法的精度比较,训练过后的SSIT的平均精度达到了90.6%,远高于CNN等预测精度,虽然CNN方法对于大量的图片识别率基本上达到了99%以上的识别率,但对于航空发动机的轴承振动时域图却因为已标记样本信息过少且特征复杂的原因而大大降低了识别率,SSIT却可以从大量的源领域以及未标记样本中获得辅助信息帮助判断。TELM以及SELM的低预测精度也表明半监督以及迁移学习在面对少量已标记样本时有着相辅相成缺一不可的关系。
| 测试集 | SSIT | CNN | TELM | SL |
| 测试集1 | 90.5 | 81.3 | 68 | 69.7 |
| 测试集2 | 90.6 | 82.1 | 68 | 69.6 |
| 测试集3 | 90.6 | 82.2 | 72 | 68.5 |
| 测试集4 | 90.5 | 79.2 | 71 | 70.4 |
| 测试集5 | 90.6 | 79.5 | 73 | 69.5 |
| 平均值 | 90.6 | 80.9 | 70 | 69.5 |
本文选取3个数据集,比较3个迁移领域最终的迁移样本量,3个领域的区别在于工作负载以及环境的差异,差异越大越难以迁移,从表 3中可以看出,实验状态下D3数据集的轴承振动数据难以用于预测民航发动机故障预测,而这正是现如今大量轴承预测方法难以在发动机环境内奏效的原因,D1于D2则展现了与源领域样本的高相似度,对于SSIT的故障预测给予了巨大帮助,由此本文可以增加同发动机不同推力下的目标领域样本以及不同轴承型号相同推力下的样本,以期迁移更多的样本帮助预测。
| 测试集 | D1 | D2 | D3 |
| 测试集1 | 63.2 | 40.1 | 22.3 |
| 测试集2 | 69.4 | 43.9 | 20.3 |
| 测试集3 | 66.7 | 39.6 | 25.1 |
| 平均值 | 66.4 | 41.2 | 22.6 |
图 17为在D1领域下,迁移样本量的提升,SSIT精度的精度变化。从图中可以看出,在迁移样本达到350个以后,迁移学习提升了整个学习器18%的精度。

|
| 图 17 D1下迁移样本量对精度的影响 Fig. 17 Effect of transfer sample size on accuracy under D1 |
半监督算法中的未标记样本选用实验前已记录的无结果振动数据[17],但是本文在实验中发现如果加入部分测试时间点前后的振动信息作为未标记样本参与训练会提升算法的精度以及稳定性。而无法确定的是多少量的已记录样本(HS),测试前样本(BS),测试后样本(AS)能够最大提升精确性,本文不断调整无标记样本中三者的比例来测试其精确度的变化。如图 18所示。可以看出加入的测试节点样本有效地提升了精度,并且在(4.84,6.58)达到最大值,这是因为未标记样本中加入测试节点前后的振动数据,可以在训练时完善预测节点的特征,特别是在航空发动机内的轴承振动信息,复杂的噪声下不易提取到精确的振动信号特征,而未标记样本的半监督训练相当于又一次进行了特征提取,提高了预测的精度。

|
| 图 18 测试前后样本量对精度的影响 Fig. 18 Effect of HS and BS on prediction accuracy |
本文提出了一种半监督迁移学习集成学习器,构造改进迁移学习器组成6种初始基学习器来集成同簇的半监督基学习器,利用迁移学习降低半监督学习中的不稳定性,再利用无标记样本减少负迁移作用,并不断调整基学习器权重,提升SSIT的精度与稳定性,得出如下结论:
1) 迁移学习可以提高半监督学习的稳定性以及降低过拟合效果。
2) 半监督学习可以帮助迁移算法挑选更多更好的高相似度样本。
3) 同簇集成的方法也可以通过调整权重的方法减少负学习的效果。
4) 温和环境下的轴承振动数据难以直接迁移至发动机内部的轴承预测中,而不同推力以及不同发动机下的振动数据则展现了良好的迁移效果。
5) 测试节点前后的数据加入到无标记样本的半监督训练中可提升最终的预测精度。
将研究更加多部件故障的迁移方法,并将其运用到发动机其他部件的故障预测方面,利用大量的目标领域样本来提高预测精度。
| [1] |
房晓南.基于半监督和集成学习的不平衡数据特征选择和分类[D].济南: 山东师范大学, 2016. FANG X N.Unbalanced data feature selection and classification based on semi-supervised and integrated learning[D]. Jinan: Shandong Normal University, 2016(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10445-1016086762.htm |
| [2] |
杨印卫.基于异态集成学习的刀具状态监测技术研究[D].天津: 天津大学, 2014. YANG Y W.Research on tool condition monitoring technology based on alien integration learning[D]. Tianjin: Tianjin University, 2014(in Chinese). |
| [3] |
张伟.基于卷积神经网络的轴承故障诊断算法研究[D].哈尔滨: 哈尔滨工业大学, 2017. ZHANG W.Research on bearing fault diagnosis algorithm based on convolutional neural network[D]. Harbin: Harbin Institute of Technology, 2017(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10213-1017864225.htm |
| [4] |
郭勇.基于单源及多源的迁移学习方法研究[D].西安: 西安电子科技大学, 2013. GUO Y.Research on transfer learning method based on single source and multiple sources[D]. Xi'an: Xidian University, 2013(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10701-1013304243.htm |
| [5] |
ZHOU Z H, LI M. Tri-training:Exploiting unlable data using three classfiers[J]. IEEE Transactation on Knowledge and Data Engineering, 2005, 17(11): 1529-1541. DOI:10.1109/TKDE.2005.186 |
| [6] |
卞则康, 王士同. 基于相似度学习的多源迁移算法[J]. 控制与决策, 2017, 32(11): 1942-1948. BIAN Z K, WANG S T. Multi-source transfer algorithm based on similarity learning[J]. Control and Decision, 2017, 32(11): 1942-1948. (in Chinese) |
| [7] |
谭建平.基于半监督的SVM迁移学习文本分类方法[D].广州: 广东工业大学, 2016. TAN J P.A semi-supervised SVM transfer learning text classification method[D]. Guangzhou: Guangdong University of Technology, 2016(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-11845-1016139239.htm |
| [8] |
张倩, 李海港, 李明. 基于多源动态TrAdaBoost的实例迁移学习方法[J]. 中国矿业大学学报, 2014, 43(4): 713-720. ZHANG Q, LI H G, LI M. An example transfer learning method based on multi-source dynamic TrAdaBoost[J]. Journal of China University of Mining & Technology, 2014, 43(4): 713-720. (in Chinese) |
| [9] |
PAN J, WANG X S, CHENG Y H, et al. Multi-source transfer ELM-based Q learning[J]. Neurocomputing, 2014, 137: 57-64. DOI:10.1016/j.neucom.2013.04.045 |
| [10] |
王雪松, 潘杰, 程玉虎. 知识迁移学习方法及应用[M]. 北京: 科学出版社, 2016. WANG X S, PAN J, CHENG Y H. Knowledge transfer learning method and application[M]. Beijing: Science Press, 2016. (in Chinese) |
| [11] |
CHENG Y H, WANG X S. Multi source tri-training transfer learning[J]. Transactions on Information and System, 2014, 97(6): 1668-1672. |
| [12] |
邓万宇, 屈玉涛. 基于ELM-AE的迁移学习算法[J]. 计算机与数字工程, 2018, 46(5): 854-860. DENG W Y, QU Y T. Transfer learning algorithm based on ELM-AE[J]. Computer and Digital Engineering, 2018, 46(5): 854-860. (in Chinese) |
| [13] |
莫志军, 基于复杂网络的航空发动机故障传播特性研究[D].长沙: 湖南科技大学, 2016. MO Z J.Research on fault propagation characteristics of aeroengine based on complex network[D]. Changsha: Hunan University of Science and Technology, 2016(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-10534-1016792678.htm |
| [14] |
郭艳平, 龙涛元. 振动信号模型在滚动轴承故障诊断中的应用[J]. 机械设计与制造, 2018, 30(17): 270-272. GUO Y P, LONG T Y. Application of vibration signal model in fault diagnosis of rolling bearings[J]. Machinery Design & Manufacture, 2018, 30(17): 270-272. (in Chinese) |
| [15] |
LIU X B, LIU Z T. Ensemble transfer learning algorithm[J]. IEEE Access, 2018, 32(6): 2389-2396. |
| [16] |
IQBAL M S, LUO B, KHAN T. Heterogeneous transfer learning techniques for machine learning[J]. Iran Journal of Computer Science, 2018, 1(1): 31-46. DOI:10.1007/s42044-017-0004-z |
| [17] |
BLUM A, MITCHELL T.Combining labeled and unlabeled data with co-training[D]. Pittsburgh: Carnegie Mellon University Madison, 1998: 92-100.
|