



2. 合肥学院 计算机科学与技术系, 合肥 230601
2. Department of Computer Science and Technology, Hefei University, Hefei 230601, China
数字信号处理器(DSP)芯片是对信号和图像实时处理的一类芯片, 其具有高性能、低功耗和低成本等特点,在通信、雷达、电子对抗、仪器仪表等领域有着广泛的应用[1]。随着现代通信技术的发展,数字电视广播(DVB)、数字媒体播放(DMB)、数字音频广播(DAB)等技术的全面应用与拓展,处理器对数字信号处理领域算法的性能需求也愈发强烈, 如快速傅里叶变换(FFT)、有限冲激响应(FIR)、无限冲激响应(IIR)等。高性能DSP技术已成为目前集成电路领域发展速度最快、竞争最激烈的研究方向。
数字信号处理应用通常涉及大量的数据传输与运算。对于FFT、FIR等数据密集型算法,数据吞吐率很大程度上决定了算法的直接效率。输入数据需经过多次读取、计算后,再重新写回内存中。对于部分计算较为简单的运算环节,同一数据的高频次的取数、写回过程会导致数据传输拥堵、运算部件闲置、总线带宽负载过重等问题,进而引发流水线停滞,带来大量时间、空间上的开销和浪费。因此,采用高效便捷的传输策略,在数字信号处理领域尤为重要。
在处理DSP芯片的传输瓶颈问题时,通常会采用调整访存策略、提高传输带宽、扩充寄存器、增加Cache等方式来提高吞吐量[2]。Lee和Sunwoo[3]基于DSP芯片提出数据处理单元(DPU),可以让现有DSP芯片的访存速度提高一倍。Nishitsuji等[4]则提出通过增加额外bank,利用5-bank的错位内存结构来缓解访存冲突问题。Chang和Sung[5]采用设计额外的访存Cache,用以解决非连续和非对齐数据访问的问题。这些方式大多需要对专用芯片进行大量的硬件调整,更多地侧重于通过扩充硬件或调整策略的方式提高传输总量。但在同一块处理器上,硬件的过分扩充会影响其通用性,且额外增加的通道相互之间可能产生相干或冲突[6]。Le等[7]提出一种高级访存管理方案,该方案可以动态计算并有效预测地址,从而实现访存的规范管理。Luo[8]和Hsiao[9]等则通过针对数字信号处理领域中特定应用的算法特点,进行访存策略设计,从而达到充分利用现有访存资源的目的。然而,这些方式大多数基于通用访存设备和额外硬件。在充分利用现有资源的同时,还可以深挖其他部件的使用价值,使资源利用效率达到更高的程度。
本文首先提出了一种基于移位器的查找暂存技术,通过为移位器额外添加专用暂存空间随机存取存储器(RAM),从而形成传输缓存区。其次,通过移位器查找表(LUT)的方式对相应区域进行灵活存读取,并对运算中间过程数据进行暂存,以达到缓解系统访存压力的目的。此外还充分利用移位器数据暂存过程中对数据进行简单移位、提取、算术与逻辑运算等能力,将部分数据运算处理的过程直接融合在数据存读取过程中,取数、计算、写回的过程完全在移位器中实现,显著地提高了运算部件的使用效率。
1 移位器在普通微处理器中,一般没有单独的移位器单元,相应的移位运算通过逻辑运算单元实现。但在数字信号处理领域,移位操作被广泛使用在计数器、分频器及译码器上。信号处理算法普遍涉及大量的移位操作,单纯通过算术逻辑单元(ALU)来实现移位功能不仅无法满足运算需求,同时会造成运算资源的浪费。所以一般DSP芯片中都设计有专用的移位器,其性能直接影响到所在DSP的处理能力和执行速度[10]。
移位器是DSP中的重要部件,其可以实现对源操作数进行任意裁减、分解、移位和拼接等功能。在传统CPU中,移位器的设计一般采用矩阵结构和树状结构。而在DSP芯片上,为满足移位器由一个时钟周期内完成一次简单的移位发展到在一个时钟周期内可进行大量位数的移位操作的需求,桶形移位器[11-12]与对数移位器[13]先后被提出和实现,并发展成混合译码移位器。如今的移位器,在逻辑/算数运算、压缩及拓展、移位裁减、位域操作、数据传输及校验等方向有着广泛的应用。
在DSP领域的移位器的研究中, 大量工作的研究方向都是提高其运算速度, 以及降低移位器功耗。除此之外,为移位器设计专用暂存RAM,可在部分算法应用,运算部件负载压力较小但传输带宽总线压力较大时,充当数据中转区,以实现数据暂存。使用专用RAM和LUT辅助移位器的设计思路,在现场可编程门阵列(FPGA)领域有一定的应用。Xilinx公司的Block ram[14](基于RAM模拟的移位器)与Altera公司的Altshift_taps[15]通过在FPGA中模拟实现类似功能,但它们为一个IP核结构,并非移位器专用部件,在专用DSP芯片中也没有类似结构。因为移位器暂存部件与数据访存总线之间并不冲突,在同一指令发射上,同时采用移位器查找存储和数据访存的方式,可以极大效率地提高数据吞吐效率,而不产生相干。
通过移位器查找表进行的数据暂存,利用移位器取数的灵活特性,不仅可以实现数据的暂存,还可以在寄存器使用压力较大的算法中,分担部分寄存器存储压力。同时,在分簇DSP的单指令多数据流(SIMD)运算的过程中,常常会因为数据宏间传输限制、从属于不同bank的相邻数据之间运算等问题,造成流水线停滞,浪费大量时间和空间。利用移位器查找表作为宏间数据传输中转站,还可以达到提高数据访问效率,减少运算bank冲突的作用。
2 平台HXDSP是国内某研究所研制的第二代高性能超长指令字(VLIW)DSP芯片[16],其结构如图 1所示。它是一款32位静态超标量处理器,内部集成2个新一代处理器核eC104+,工作主频为800 MHz~1 GHz。采用16纳米工艺,16发射、SIMD架构,通信带宽为252 Gbit/s,存储容量105 Mbit,运算性能可达134 GFLOPS(GFLOPS表示每秒10亿次的浮点运算数)。

|
| 图 1 HXDSP104x系统架构 Fig. 1 Architecture of HXDSP104x system |
HXDSP的每个核心处理器如图 2所示,其采用哈佛体系结构,有独立的程序总线和数据总线。HXDSP处理器有宽度为512 bit的指令总线和非对称全双工的内部数据总线。其包括4个基本执行宏(element operation macro),每个执行宏由8个ALU、8个乘法器(MUL)、4个移位器(SHF)、1个超算器(SPU)以及128个通用寄存器组成。

|
| 图 2 HXDSP处理器向量处理单元 Fig. 2 Vector processing unit for HXDSP Processor |
在HXDSP的每个分簇中(HXDSP的4个执行宏,即4个分簇,分别称为Cluster x、y、z、t),包含4个移位器(Shifter 0~Shifter 3)[17]。为移位器增加的额外暂存空间结构如图 3所示,移位器查找表TAB是移位器内部对应的RAM,每个移位器对应一个TAB,用参数k来区分各移位器。每个移位器包含4块8 bit RAM (Table 0~Table 3), 每块8 bit RAM又分为4个块(用参数n表示),共计16块,每块256×8 bit。

|
| 图 3 移位器查找表结构 Fig. 3 Structure of shifter look-up table |
当用户从移位器取一个标准32 bit数数据时,从4块RAM的每个第n位置,分别取一个8 bit数据,组成一个32 bit。当用户从移位器取一个标准16 bit数时,有2种方式:①从第0、1块RAM的第n个位置,每块取一个8 bit数据,组成一个16 bit;②从第2、3块RAM的第n个位置,每块取一个8 bit数,组成一个16 bit。第0、1块RAM取出的16 bit可与32 bit通用寄存器的低16 bit做运算,第2、3块RAM取出的16 bit数可与32 bit通用寄存器的高16 bit做运算。
3.2 LUT指令基于这样的硬件结构,HXDSP的移位器查找表通用访问指令为
Rs=STABn(LLORm)(k)\STABn(LLORs)=Rm(k)
Rs=STABn(HLORm)(k)\STABn(HLORs)=Rm(k)
Rs=STABn(LHORm)(k)\STABn(LHORs)=Rm(k)
Rs=STABn(HHORm)(k)\STABn(HHORs)=Rm(k)
在这组微操作指令中,“\”左侧为通用寄存器从移位器查找表中读出数据,右侧为通用寄存器将数据写入移位器查找标中。其中STAB为移位器查找表指令形式,n指代每个TAB的4块8 bit RAM中的序号(0~3)。在HXDSP指令架构寻址移位器查找表的过程中,一般将一个32 bit通用寄存器Rm划分为4个8位区域:[7:0]、[15:8]、[23:16]、[31:24],分别称为低位、次低位、次高位、高位,并通过读取指定区域上的8位数值,映射查找表中的具体地址。同一个8 bit RAM中的4块分别读出一个8 bit数据,即可拼接成一个需要的32 bit数。
4 移位器查找表的扩展使用 4.1 移位器查找表的暂存作用DSP芯片作为数字信号处理领域的通用处理器,经常会面对各种算法的需求与性能考量[18]。有些算法特点为数据密集型,即在函数运算的过程中,运算部件的运算占用率不高,此时性能瓶颈主要在带宽总线的吞吐上;有些算法为运算密集型,此时至少有一种运算部件在核心周期指令发射上接近满负荷,运算占用率接近1,此时性能瓶颈主要在算法与运算部件上。还有一些算法,在计算的不同阶段,对传输和运算有不同的需求,可能在算法的不同时期,分别造成不同瓶颈。如基-2点的FFT算法,会在不同的运算层,产生传输瓶颈与运算瓶颈。
FFT算法在计算和实现的过程中,需要对大量旋转因子(twiddle)及中间层数据进行暂存。对于这类数据密集型运算,单纯依靠总线带宽,往往会造成运算部件的闲置和资源浪费。HXDSP平台每个执行宏中,含有4个移位器,所以在同一条指令行可以执行4条移位器查找表指令。4个执行宏同时执行时,每个时钟周期可以读取4×4个32bit数据。同时,HXDSP拥有3条64 bit非对称全双工的内部数据总线,可同时进行两读一写或两写一读操作,每次2个32 bit数据。
当4个执行宏同时执行运算时,可以对存储器读取或写入2×4×2×32 bit数据。即采用移位器查找表暂存方式,有着与访存指令相同的吞吐能力。基于HXDSP的16发射、SIMD架构,移位器查找表的暂存指令可以和数据存储指令同时执行,使得访存速度提升至原来的2倍。这显著地提升了平台数据吞吐能力,有助于解决内存读写速度与运算部件计算速度不匹配的问题。对于FFT、FIR等访存密集型算法,有着较大的性能提升作用。
4.2 移位器查找表在存读取过程中的额外运算支持在基-2或者基-2n的FFT运算中,数据地址寻址会随着层数的变化而变化。图 4为16点DIT-FFT算法实现图,DIT模式算法,在数据读入时,需要对输入地址进行位反序寻址。寻址过程通常会选择将基地址依层次变化加上相应偏移地址形成实际访存地址。这就需要针对相应层次,为基地址加上32、16、8等偏移量。但如表 1所示,考虑到偏移地址依层次变化,十进制中变址跃迁的8、16、32等相对距离,转换成二进制机器数据,就是针对寄存器中二进制表示的数据的其中某一位去置0或置1。这些被读取数据地址的变化,可利用移位器作为暂存寄存器处理。移位器可在作为替代内存进行访存指令数据暂存的同时,额外进行一定的逻辑或算数运算。从而在不产生额外时钟周期消耗的同时,完成一些需要的运算。

|
| 图 4 16点DIT-FFT Fig. 4 16-DIT-FFT |
| 层数 | 偏移(D) | 偏移(O) |
| 1 | 32 | 100000 |
| 2 | 16 | 010000 |
| 3 | 8 | 001000 |
| 4 | 4 | 000100 |
| 5 | 2 | 000010 |
| 6 | 1 | 000001 |
为增强对移位器查找表访存过程中额外运算的支持,文中提出一种改良微指令Rs=STABn(Rm)(k)。
该指令以Rm寄存器的高位与低位分别存储映射查找表中具体地址的8 bit数值及调整自增数值的偏移位,使寄存器在一条指令中能够在存/读取移位器查找表的同时,完成偏移量修正自增工作。在FFT运算中,常常会出现4个移位器全部用于移位器查找表的读写;8个ALU全部用于蝶形计算。所以如果中间再加入移位器查找表中的标志寄存器自增指令,能节省不必要的开销。
微指令Rs=STABn(Rm)(k)完成过程:
1) 以源寄存器Rm的低位[7:0]为地址,读出需访存移位器查找表中的目的位置s。
2) 从4块RAM的每个第s位置,每块取一个8 bit数据,组成一个32 bit数并将这个32 bit数赋给目的寄存器堆Rs。
3) 同时以寄存器Rm的次高位[23:16]为地址,读出下一次源寄存器低位[7:0]读取变更数据位。当算法需求为自增时,最低位置1,当算法需求为FFT等呈2n次幂形式递增时,修改相应数据位。
4) 读取STAB查找表中相应数据并赋给目的寄存器堆Rs的同时,在同一个时钟周期内,更源寄存器Rm,进入下一次运算。
在这样的指令形式下,FFT算法可对中间层临时数据进行按需读取或存储操作。并且在暂存器访存指令执行的同时对相应偏移地址进行调整,从而达到在同一条指令中实现取数、取值、运算、更新的全部过程。这一过程显著地提升了运算效率,为访存部件和运算器都减轻了工作压力。而当变更寄存器置位为最低位为1时,可利用移位器部件,实现循环自增寻址工作。这一功能可以广泛运用在数字信号处理,数字图像处理等领域。
本文还提出另一种改良微指令
HSTABn(LORs)+=HRm(U, k)
该指令利用Rs的次低位[15:8]和低位[7:0]位寻址高16 bit和低16 bit,分别取出第n(n可以取0、1、2、3)块STAB中的2个16位数,并分别与Rm[19:16]和[3:0]累加,累加结果存入原位置。高效直接地对移位器查找表中的数据进行调整修改,从而提高了工作效率。
4.3 移位器查找表在存读取过程中的额外寄存器支持移位器查找表的RAM的存在,类似于寄存器与内存之间的Cache,能够完成部分数据的暂存作用。但是因为移位器自身的特点,它可以灵活地对暂存的数据进行选择性输出或处理,甚至在寄存器使用瓶颈的时候,起到部分替代寄存器的作用。
HXDSP原有微指令STABd(Rn, Rs, Rm)(k)的作用是把寄存器Rm的值写入到STAB中,同时把STAB中某个位置的值读出到寄存器Rs。k指定本指令在哪个移位器上执行,在第2个字的[1:0]位。d指定本指令占用的STAB块,在第2个字[3:2]位。Rn[7:0]位指定读出STAB中某一块的位置。寄存器Rn[23:16]指定写入STAB中某一块的位置。
本文同时提出对STAB(Rn, Rs, Rm)这一微指令的修改方案。
在目前的这条指令中,Rn的低位[7:0]用于移位器查找表中读位置的标识,次高位[23:16]用于移位器查找表中写位置的标识,如:

|
此时次低位[15:8], 高位[32:24]空闲。对于寄存器资源紧张的算法应用,如FFT算法的中间层代码编写,是极大的浪费。
因此可调整成:
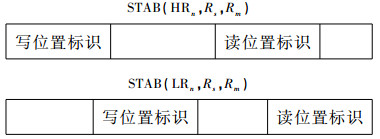
|
这样可以充分利用Rn寄存器,将一个寄存器划分成2个,使寄存器使用紧张的情况得以缓解。同时由于移位器查找表的灵活寻址取数方式,它实际上构成了寄存器与内存区域中间一层灵活的缓冲区。在高效完成大量移位操作的同时,为DSP芯片的数据传输、运算部件使用、寄存器分配充分地分担了压力。
5 实验结果与分析 5.1 移位器查找表吞吐率分析HXDSP的微指令Rs=STABn(LLORm)(k)每次执行,只占用一个移位器,指令周期为1个cycle。因为HXDSP是一个支持4个执行宏4路SIMD指令的处理器,每个执行宏又包括4个移位器,所以在每一个时钟周期中,最多可以4路并行执行4条上述指令,即一个周期可存取4×4×32 bit。因此,通过移位器查找表指令,可实现一个时钟周期对16个寄存器的暂存访问。
同时,HXDSP拥有3条非对称全双工总线,可以在同一指令行同时进行两读一写或两写一读操作。HXDSP的通用读写指令{x, y, z, t}Rs+1:s=[Un+=Um, C]支持双字读写,即每次执行可以存读取连续的2个32 bit数据,指令周期也为1个cycle。其中Un表示寻址的起始地址,Um表示每次寻址之后的基地址跃迁地址,立即数C表示寻址过程中的偏移地址。因此每个时钟周期最多可以进行2×2×4×32 bit的读操作或者写操作,即在一个时钟周期内,HXDSP可对16个寄存器进行访存读写操作。
上述对比表明,移位器查找表有着和HXDSP访存总线相同的传输效率和吞吐能力。当面对数据密集型运算时,可利用传输指令和移位器的暂存RAM进行复合读写操作,存读取速度可扩展到之前的2倍,极大地缓解数据访存压力。
5.2 移位器查找表应用分析基于移位器查找表,可以对数字信号处理应用中许多算法进行加速优化。对于数字信号处理算法如FFT,移位器查找表可以作为DIF-FFT寻址中相应偏移地址形成的加法器;也可以作为旋转因子及中间层运算结果的暂存器,以提高运算过程中的访存效率。
如图 5所示,对于基-2点的FFT算法,移位器查找表的暂存功能对FFT的访存性能有显著地提升。图中,横坐标表示FFT算法的具体运算规模,左侧纵坐标表示算法运行的实际运算周期数,右侧纵坐标表示使用移位器查找表前后加速比。当点数为64时,由于FFT点数较少,部分中间运算可以直接用寄存器存储,所以加速比不高。当FFT点数小于等于1 024点时,FFT效率显著提升,加速比约为1.20。这是因为所有数据的中间计算暂存可以在移位器查找表中完成,可充分提高访存效率。而当FFT点数大于1 024点时,加速比略有下降,但是依然稳定在1.15左右。这是因为对于大点数的FFT,数据访问无法完全在移位器查找表中实现,其访存过程需要和访存总线同时进行。

|
| 图 5 使用移位器查找表前后对比 Fig. 5 Comparison with and without shifter look-up table |
HXDSP是一款高性能的VLIW DSP芯片,基于其开发设计的移位器暂存RAM与移位器查找表的架构,是一种新颖而灵活的移位器拓展结构。其在高效完成数字信号处理应用中大量移位操作的同时,还可以在一定程度上分担芯片的传输与运算压力。HXDSP的移位器查找表在同一周期内,有着和系统总线同样的传输带宽,不仅可以分担传输压力,还可以将部分简单运算过程融入其中,极大地提高了芯片的使用效率。
目前这一技术尚在试用及继续开发中,关于移位器查找表的适应指令集依然在调整和扩充。本文提出一种对移位器查找表的高效使用,并对现有指令集进行了两处调整和升级。相信在不久的将来,会有更多更高效的创新,让这一技术和结构,能够在DSP领域,发挥更出色的作用。
| [1] |
EYRE J, BIER J. The evolution of DSP processors[J]. IEEE Signal Processing Magazine, 2000, 17(2): 43-51. |
| [2] |
YE H, GU N, ZHANG X, et al. Design and implementation of a conflict-free memory accessing technique for FFT on multicluster VLIW DSP[J]. IEICE Electronics Express, 2018, 15(18): 20180674. |
| [3] |
LEE J S, SUNWOO M H. Design of new DSP instructions and their hardware architecture for high-speed FFT[J]. Journal of VLSI Signal Processing Systems for Signal, Image and Video Technology, 2003, 33(3): 247-254. |
| [4] |
NISHITSUJI T, KAKUE T, SHIMOBABA T, et al.Conflict-free FFT circuit using loop architecture by 5-bank memory system[C]//IEEE Asia Pacific Conference on Circuits and Systems(APCCAS).Piscataway, NJ: IEEE Press, 2014: 523-526.
|
| [5] |
CHANG H, SUNG W.Efficient vectorization of SIMD programs with non-aligned and irregular data access hardware[C]//Proceedings of the 2008 International Conference on Compilers, Architectures and Synthesis for Embedded Systems.New York: ACM, 2008: 167-176.
|
| [6] |
YE H, GU N, ZHANG X, et al.An efficient conflict-free memory-addressing unit for SIMD VLIW DSP[C]//2017 International Symposium on Performance Evaluation of Computer and Telecommunication Systems(SPECTS).Piscataway, NJ: IEEE Press, 2017: 1-7.
|
| [7] |
LE G B, CASSEAU E, HUET S. Dynamic memory access management for high-performance DSP applications using high-level synthesis[J]. IEEE Transactions on Very Large Scale Integration(VLSI) Systems, 2008, 16(11): 1454-1464. |
| [8] |
LUO H F, LIU Y J, SHIEH M D. Efficient memory-addressing algorithms for FFT processor design[J]. IEEE Transactions on Very Large Scale Integration(VLSI) Systems, 2015, 23(10): 2162-2172. |
| [9] |
HSIAO C F, CHEN Y, LEE C Y. A generalized mixed-radix algorithm for memory-based FFT processors[J]. IEEE Transactions on Circuits and Systems Ⅱ:Express Briefs, 2010, 57(1): 26-30. |
| [10] |
PENG Y X, ZOU J J. Design and implementation of ALU and shifter in X-DSP[J]. Journal of Computer Applications, 2010, 30(7): 1978-1982. |
| [11] |
PEREIRA R, MICHELL J A, SOLANA J M. Fully pipelined TSPC barrel shifter for high-speed applications[J]. IEEE Journal of Solid-State Circuits, 1995, 30(6): 686-690. |
| [12] |
ACKEN K P, IRWIN M J, OWENS R M.Power comparisons for barrel shifters[C]//Proceedings of 1996 International Symposium on Low Power Electronics and Design.Piscataway, NJ: IEEE Press, 1996: 209-212.
|
| [13] |
WESTE N, ESHRAGHIAN K. Principles of CMOS VLST design[M]. Boston: Addison Wesey, 1993.
|
| [14] |
Xillinx.PG058-block memory generator v8.4 product guide (v8.4)[EB/OL].(2017-10-04)[2019-01-28].https://china.xilinx.com/support/documentation/ip_documentation/blk_mem_gen/v8_4/pg058-blk-mem-gen.pdf.
|
| [15] |
Altera.RAM-based shift register(ALTSHIFT_TAPS)IP core user guide[EB/OL].(2014-08-18)[2019-01-28].https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/ug/ug_shift_register_ram_based.pdf?wapkw=altshift_taps&_ga=2.155121400.1796521913.1564220766-1713056724.1564220743.
|
| [16] |
中国电子科技集团公司第三十八研究所.BWDSP104x软件用户手册[Z].2015. CETC-38.Software user's manual BWDSP104x[Z].2015(in Chinese). |
| [17] |
中国电子科技集团公司第三十八研究所.BWDSP104x硬件用户手册[Z].2015. CETC-38.Hardware user's manual BWDSP104x[Z].2015(in Chinese). |
| [18] |
刘余福, 郎文辉, 贾光帅. HXDSP平台上矩阵乘法的实现与性能分析[J]. 计算机工程, 2019, 45(4): 25-29. LIU Y F, LANG W H, JIA G S. Implementation and performance analysis of matrix multiplication on the platform HXDSP[J]. Computer Engineering, 2019, 45(4): 25-29. (in Chinese) |