



2. 中央财经大学 统计与数学学院, 北京 100081
2. School of Statistics and Mathematics, Central University of Finance and Economics, Beijing 100081, China
在目前的大数据时代,数据采集的途径越来越多样化,数据量越来越大,采集到的数据类型也日益丰富。在对这些数据进行分析的过程中,不可避免地会遇到混合类型的数据,无法直接使用已有方法进行分析处理。在已有方法的基础上,构建新方法对混合类型的数据进行统计分析具有理论和现实意义。例如,图像数据、音频数据和矩阵数据混合的数据分析问题,在图像处理、语音识别、推荐系统构建等领域中并不少见,且已引起广泛的关注。
事实上,音频数据和图像数据分别可以采用一元和二元函数型数据进行表示,矩阵数据可以采用多元向量加以描述。因此,对函数型数据和多元向量数据混合的模型及其估计方法进行研究并加以推广,可解决一系列实际问题。
对于函数型数据的研究成果众多[1],集中于函数型线性回归模型的参数估计和假设检验[2]、函数型数据的聚类分类等诸多方面[3-4]。多元统计分析的成果更是丰富,近年来围绕着高维情形下的多元统计分析,如变量选择、假设检验等也有一系列理论与实际结果。但对于函数型数据和多元向量数据混合的情形,研究成果相对较少。因为在处理该类混合数据时,需要考虑不同类型数据之间的相关性度量及对模型估计结果的影响,情况比较复杂。此外,由于函数型系数的存在,理论上研究估计量的渐近性质也具有难度。因此,通常在尽可能不过多损失信息的前提下,对混合数据进行转化,基于转化后的数据改进已有方法进行处理[5]。
基于此,本文对含有函数型和多元向量自变量的回归模型中变量选择和参数估计问题进行探讨。首先,对函数型自变量利用函数型主成分基函数进行投影,对模型加以转化。然后,采用L1损失函数并考虑组变量选择方法,同时进行变量选择和参数估计,其中调节参数的选择采用了自适应算法,目标函数的最优化借助于线性规划相关算法。最后,通过数值模拟验证了本文方法在变量选择和参数估计上的有效性。
1 函数型和多元向量混合回归模型本节引入函数型和多元向量混合回归模型,并给出对模型进行变量选择和参数估计的方法。
假设X1(t), X2(t), …, Xp(t)为p个函数型自变量,满足E(Xj(t))=0, E(Xj2(t)) < ∞, n个样本的取值分别为Xij(t), 1≤i≤n, 1≤j≤p。
考虑如下模型:
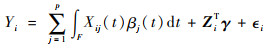
|
(1) |
式中:F为积分区域; Yi为响应变量;Xij(1≤j≤p)为函数型自变量;Zi∈Rq为多元向量自变量;εi为随机误差项,满足E(εi)=0, E(εi2) < ∞;βj(t)(1≤j≤p)和γ∈Rq为待估参数。
在模型中,如果βj≡0(1≤j≤p), 模型即为常见的多元线性回归模型;如果γ=0,模型退化为通常的多元函数型线性模型;进一步, 如果p=1, γ=0,模型则成为函数型线性模型。因此,该模型具有较强的泛化能力。
2 模型变量选择和参数估计本节先对函数型自变量在主成分基函数所张成的函数空间进行投影,再采用L1损失函数和组LASSO(Least Absolute Shrinkage and Selection Operator)[6]惩罚方法进行变量选择。
2.1 函数型主成分及模型转化假设任意函数型自变量Xj(t)(1≤j≤p),定义Xj(t)的协方差函数为Kj(s, t)=cov(Xj(s), Xj(t)),并进行如下谱分解[7]:
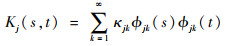
|
式中:κj1≥κj2≥…≥0为算子Kj的各个特征值;Φjk为特征值对应的特征函数。{Φjk}构成L2(F)空间的一组规范正交基,从而有
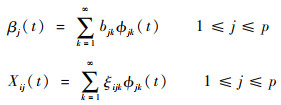
|
式中:bjk和ξijk为系数。进一步,模型(1)可转化为
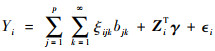
|
以上是关于理论的探讨,当面对样本时,需要对Kj(s, t)进行估计,可使用样本协方差函数进行估计。类似地,可定义函数型自变量的样本协方差函数为
|
式中:
对
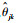
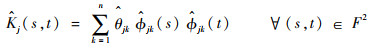
|
在实际数据分析中,对样本协方差估计时通常会进行截断处理,最常用的做法是依据方差占比进行基函数个数选择。这里,函数型主成分基函数的个数可以通过累计方差占比CPV进行选择[8-10],如设定选取主成分基函数的个数后能保留CPV=85%的方差信息,根据
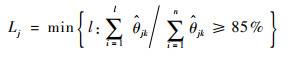
|
来对Xj(t)选择Lj个函数型主成分基函数。
模型(1)可转化为
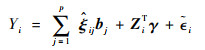
|
(2) |
式中:
本节基于模型(2)进行变量选择及参数估计的讨论。考虑到将每个函数型自变量展开为几个函数型主成分方向上的投影,若对原始的函数型自变量进行选择,自然会考虑组变量选择方法[11-13]。组变量选择方法不对单个变量的系数添加惩罚,而是对变量组的系数向量整体添加惩罚,从而达到变量选择的效果。构造如下目标函数:
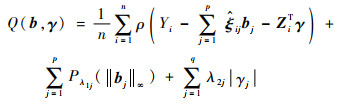
|
(3) |
式中:ρ(·)为损失函数;Pλ(t)=λt为惩罚函数,λ1j(1≤j≤p)、λ2j(1≤j≤q)为惩罚项的调节参数;||·||∞为针对bj的范数定义,||bj||∞=max{|bj1|,
|bj2|, …, |bjLj|}。通过最小化目标函数Q(b, γ)可得到对应系数的估计量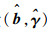
损失函数ρ(·)可以选择为任意常见损失函数或根据需要构造,如最小二乘损失、分位数损失函数等,或负的对数似然函数等。综合考虑效率及稳健性质,选择分位数损失函数[14],并以50%分位数为例,则ρ(t)=|t|。
2.3 调节参数选择及目标函数优化注意到,||bj||∞ < C等价于|bjk| < C, 1≤k≤Lj。因此,最小化目标函数式(3)中的Q(b, γ),可通过引入松弛变量转化为线性规划问题[15]。
通过如下定义引入松弛变量(ui, vi)i=1n:
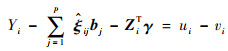
|
同样,待估参数向量(b, γ)的各个元素都可以表示成正部、负部相减的形式,即bjk=bjk+-bjk-, 1≤k≤Lj, 1≤j≤p, γl=γl+-γl-, 1≤l≤q。最小化目标函数式(3)中的Q(b, γ),即转化为在如下约束条件下:
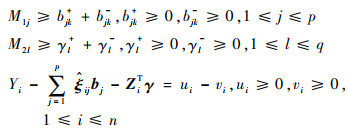
|
最小化如下目标函数:
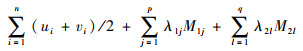
|
该优化问题转化为线性优化问题,简化了目标函数的优化过程。充分利用了损失函数和惩罚函数的具体形式,对于其他损失函数和惩罚函数需要另行考虑。
关于调节参数,主要涉及到损失函数和惩罚函数之间的权重选择。调节参数过小,损失函数权重较大,模型复杂度惩罚不足;调节参数过大,模型复杂度惩罚过重,模型过于简单,无法很好地拟合数据。调节参数选择有诸多准则供参考[16-17],本节采用SIC准则。
引入不加惩罚项时的估计量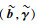
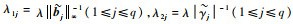
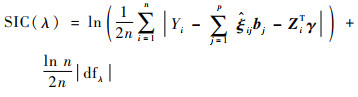
|
式中:dfλ表示调节参数为λ时
以上针对含有函数型和多元向量自变量的混合回归模型,从模型本身出发,利用函数型主成分分析、组变量选择方法、线性规划等,对模型实现了变量选择和参数估计。
3 数值模拟在不同误差分布、样本量和信噪比下,对函数型和多元向量混合回归模型进行变量选择和参数估计,考查其有限样本性质。
关于函数型自变量及其函数型系数、多元向量自变量及其系数,参考1[10]进行如下设计:p=q=3, 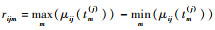

按照如下公式生成因变量:
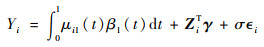
|
式中:σ为标准差;β1(t)=sin(2πt), γ=[0.3, 0, 0]。为对比不同样本量、信噪比下的模型估计效果,分别设定n=100, 300, σ=0.05, 0.2。
关于效果评价指标,分别使用将非零参数估计为非零的参数个数(TP)、将为零的参数估计为非零的参数个数(FP)来衡量变量选择的效果,TP=2, FP=0是最理想的结果。参数估计效果分别使用均方误差根(RMSE)和偏差(Bias)加以衡量:
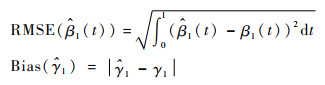
|
为保证结果的稳定性,将各情况均随机模拟200次,表 1和表 2给出了各指标的均值(Mean)和标准差(Sd)。
| (n, σ) | 统计指标 | TP | FP | RMSE | Bias |
| (100, 0.05) | Mean | 2 | 0.22 | 0.028 2 | 0.005 8 |
| Sd | 0 | 0.52 | 0.007 6 | 0.004 4 | |
| (100, 0.2) | Mean | 2 | 0.34 | 0.084 4 | 0.022 9 |
| Sd | 0 | 0.61 | 0.033 0 | 0.017 9 | |
| (300, 0.05) | Mean | 2 | 0.09 | 0.016 8 | 0.002 7 |
| Sd | 0 | 0.30 | 0.004 8 | 0.002 0 | |
| (300, 0.2) | Mean | 2 | 0.18 | 0.049 1 | 0.012 0 |
| Sd | 0 | 0.42 | 0.019 5 | 0.009 8 |
| (n, σ) | 统计指标 | TP | FP | RMSE | Bias |
| (100, 0.05) | Mean | 2 | 0.01 | 0.036 0 | 0.008 3 |
| Sd | 0 | 0.07 | 0.007 6 | 0.004 4 | |
| (100, 0.2) | Mean | 2 | 0.03 | 0.116 8 | 0.035 5 |
| Sd | 0 | 0.16 | 0.054 7 | 0.030 1 | |
| (300, 0.05) | Mean | 2 | 0 | 0.019 5 | 0.003 8 |
| Sd | 0 | 0 | 0.006 5 | 0.002 8 | |
| (300, 0.2) | Mean | 2 | 0.12 | 0.062 1 | 0.014 0 |
| Sd | 0 | 0.32 | 0.026 6 | 0.011 6 |
由表 1可知,在正态误差项下能将非零参数都估计为非零,但某些情况下会将为零的参数估计为非零,在模型中引入了无关变量。在样本量大、信噪比低情形(n=300, σ=0.05),模型变量选择效果最好。根据RMSE和Bias可以看出,该方法对于函数型自变量的参数和多元向量自变量的参数均具有良好效果。表 2结果类似。由表 1和表 2的结果对比可知,误差分布为厚尾分布时,变量选择的结果受到影响较小,而参数估计精度受到较大影响。
4 结论1) 本文同时考虑了函数型自变量和多元向量自变量,拓展了函数型数据分析的应用领域,给出了一种新的数据混合回归模型。
2) 引入惩罚函数同时进行变量选择和参数估计,对函数型自变量引入了组变量选择方法,对经过函数型主成分分析投影后的函数型自变量具有选择效果。
3) 在变量选择过程中,将目标函数优化问题转化为线性优化问题,降低了参数估计的复杂性。
4) 在参数估计过程中考虑了异常值的影响,采用了稳健变量选择方法,扩大了适用性。
| [1] |
FERRATY F. Recent advances in functional data analysis and related topics[M]. Berlin: Springer, 2011.
|
| [2] |
CHEN S T, XIAO L, STAICU A M. A smoothing-based goodness-of-fit test of covariance for functional data[J]. Biometrics, 2018, 75(2): 562-571. |
| [3] |
CUEVAS A. A partial overview of the theory of statistics with functional data[J]. Journal of Statistical Planning and Inference, 2014, 147: 1-23. DOI:10.1016/j.jspi.2013.04.002 |
| [4] |
PARK J, AHN J. Clustering multivariate functional data with phase variation[J]. Biometrics, 2017, 73(1): 324-333. DOI:10.1111/biom.12546 |
| [5] |
KATO K. Estimation in functional linear quantile regression[J]. Annals of Statistics, 2012, 40(6): 3108-3136. DOI:10.1214/12-AOS1066 |
| [6] |
TIBSHIRANI R. Regression shrinkage and selection via the Lasso[J]. Journal of the Royal Statistical Society.Series B(Statistical Methodology), 1996, 58(1): 267-288. |
| [7] |
HALL P, HOROWITZ J L. Methodology and convergence rates for functional linear regression[J]. Annals of Statistics, 2007, 35(1): 70-91. |
| [8] |
HALL P, HOSSEINI-NASAB M. On properties of functional principal components analysis[J]. Journal of the Royal Statistical Society.Series B(Statistical Methodology), 2005, 68(1): 109-126. |
| [9] |
LIN X, LU T, YAN F, et al. Mean residual life regression with functional principal component analysis on longitudinal data for dynamic prediction[J]. Biometrics, 2018, 74(4): 1482-1491. DOI:10.1111/biom.12876 |
| [10] |
HUANG L, ZHAO J, WANG H, et al. Robust shrinkage estimation and selection for functional multiple linear model through LAD loss[J]. Computational Statistics & Data Analysis, 2016, 103: 384-400. |
| [11] |
QIAN J, SU L. Shrinkage estimation of common breaks in panel data models via adaptive group fused Lasso[J]. Journal of Econometrics, 2016, 191(1): 86-109. DOI:10.1016/j.jeconom.2015.09.004 |
| [12] |
VINCENT M, HANSEN N R. Sparse group lasso and high dimensional multinomial classification[J]. Computational Statistics & Data Analysis, 2014, 71: 771-786. |
| [13] |
LIU X, LIN Y, WANG Z. Group variable selection for relative error regression[J]. Journal of Statistical Planning and Inference, 2016, 175: 40-50. DOI:10.1016/j.jspi.2016.02.006 |
| [14] |
WANG H J, LI D, HE X. Estimation of high conditional quantiles for heavy-tailed distributions[J]. Journal of the American Statistical Association, 2012, 107(500): 1453-1464. DOI:10.1080/01621459.2012.716382 |
| [15] |
BANG S, JHUN M. Simultaneous estimation and factor selection in quantile regression via adaptive sup-norm regularization[J]. Computational Statistics & Data Analysis, 2012, 56(4): 813-826. |
| [16] |
WANG T, ZHU L. Consistent tuning parameter selection in high dimensional sparse linear regression[J]. Journal of Multivariate Analysis, 2011, 102(7): 1141-1151. DOI:10.1016/j.jmva.2011.03.007 |
| [17] |
HIROSE K, TATEISHI S, KONISHI S. Tuning parameter selection in sparse regression modeling[J]. Computational Statistics & Data Analysis, 2013, 59: 28-40. |