



遥感技术的快速发展使得相关设备可以提供分辨率更高、信息量更大的遥感图像,遥感技术在大气监测、环境保护以及抢险救灾等领域得到了广泛应用,这些都可以归结为一定条件下的图像分类问题。如何快速准确地对遥感图像进行分类是一项十分艰巨的任务,对相关算法的目标特征提取能力提出了很高的要求,图像分类一直是相关科研人员感兴趣的研究方向。
传统的图像分类技术主要是基于无监督学习[1]和全监督学习[2]。无监督学习通过利用未标记样本的特征分布规律,使得相似的样本聚为一类。由于不需要先验知识辅助和样本标记信息,因此算法简单,实现起来比较容易。然而,这类算法仅仅考虑了不同样本之间的特征差异,缺乏样本类别信息的有效指导,分类效果往往不好。因此,基于标记样本的全监督算法应运而生。全监督算法通过学习样本特征与标签之间的对应关系,能够快速捕捉新样本的类别信息。这类算法在大量标记样本的训练下,分类准确率较好,鲁棒性较高。一些算法,如支持向量机(Support Vector Machine,SVM)[3]、贝叶斯(Bayes)算法[4]、随机森林(random forest)及其扩展算法[5-6]已经广泛应用于遥感图像分类等领域。但是,全监督算法需要对大量的标记样本进行学习,而实际中标记样本数量很少,并且易受噪声的影响,通过人工获取准确训练集是一项十分艰巨的任务[3]。相对而言,未标记样本极易获取、数量巨大,同样蕴含着丰富的有用信息,如果能够对其加以利用,不仅可以解决训练样本数量不足的问题,而且会大大减少前期的资源投入,提高分类效率。半监督学习能够基于标记样本,不依赖外界交互,自动地利用未标记样本提升学习性能。由于现实应用中利用未标记样本提升算法性能的巨大需求,迅速成为了研究热点。
一般认为, 半监督学习的研究始于1994年,Shahshahani和Landgrebe首次提出了半监督学习的概念[7]。依据工作形式,半监督学习大概发展成为以下几种类型:生成式模型[8]、半监督SVM[9]、图半监督学习[10]、自训练模型[11]、协同训练方法[12]。尽管半监督学习的模型较多,但是在进行算法的具体设计时,往往都是通过综合未标记样本的信息来扩充标记样本集,使得分类时相似的样本具有相同的标签或者分类面通过样本较为稀疏的地方[13]。例如:文献[14]提出了直推式支持向量机(Transductive Support Vector Machine,TSVM)算法,通过将每个未标记样本分别作为正例或反例,然后在所有这些结果中,寻找一个在所有样本上间隔最大化的划分超平面,使得泛化误差最小。文献[15]提出了基于SVM的PS3VM-D(the Progressive Semi-Supervised SVM with Diversity)算法,通过迭代查询间隔边界(margin band)附近的样本保证增量样本的信息量,并利用样本间的相似性提取最可靠的增量样本作为半监督样本。文献[16]提出了基于协同训练的tri-training半监督算法,通过初始标记样本训练出3个分类器,然后分类器分别挑选置信度最高的未标记样本赋予标签并提供给另2个分类器作为新增的有标记样本进行训练,迭代进行上述过程直至分类器不再变化,有效地提高了分类性能。文献[3]提出了基于SVM的CS4VM(Context-Sensitive SVM)算法,通过利用标记样本周围的像素背景信息,并将其设计成代价函数添加到SVM的目标函数中,得到性能更好的分类器。文献[13]提出了基于自训练的半监督算法,通过结合主动学习方法迭代查询最有用和信息量最大的样本,并利用分类器对其进行标记之后加入到初始训练集中。证实了其分类性能在标记样本较少时优于传统全监督算法。文献[17]提出了一种合成实例生成(synthetic examples generation)的半监督框架,通过对标记样本和未标记样本过采样和位置调整得到合成标记样本,然后将这些样本加入到自标记(self-labeled)过程,提高了分类性能。
尽管上述半监督算法通过实验都证明了各自的有效性,然而研究发现半监督学习并非一定能有效提升分类器的性能。这主要是由于这种方法对数据分布、未标记样本的筛选方式以及赋予伪标签的方法要求比较严格。事实上,现实中的样本数量众多,分布往往比较复杂。在某些情况下,利用未标记样本甚至是有害的[18-19]。例如对于基于自训练模型和协同训练模型的相关算法,其通过选取未标记样本赋予伪标签来扩充初始训练集,然后对分类器进行重新训练。如果未标记样本的选择不恰当或者赋予的标签不正确,那么分类器的性能不仅不会提升,甚至会严重下降。一些研究正致力于保证未标记样本利用的安全性[20-22]。而对于半监督SVM算法,尽管其可以通过迭代的方式对未标记样本进行各种可能的标签指派,以此使得分类面最佳,但是在未标记样本较多的情况下,算法计算复杂度会非常之高,严重限制了其在现实生活中的应用[23-24]。
为了能够安全地利用未标记样本提升分类性能,本文提出了基于样本类别确定度(CCS)的半监督分类算法。不同于大部分半监督算法利用未标记样本时赋予其伪标签的方法,CCS通过赋予未标记样本类别确定度信息并将其巧妙地融合到线性判别分析(LDA)的散度矩阵中,使得新的散度矩阵更能代表真实的特征分布,样本在投影后的子空间中更具有可分性。由于类别确定度能够有效衡量样本的类别可靠性,未标记样本中可靠性较高的样本所起作用大于可靠性较低的样本,算法能够充分地吸收未标记样本的特征信息,保证CCS中未标记样本利用的安全性。此外,针对现实世界中样本分布往往较为复杂的情况,本文对未标记样本的类别确定度进行归一化与阈值处理,保证了半监督过程中利用的类别确定度拥有一定的可靠性,从而提升了算法性能的稳定性。
1 支持向量机与线性判别分析算法SVM是基于结构风险最小化的机器学习方法,通过提取训练集的支持向量得到最大间隔分类器,对测试样本分类[25]。以二分类SVM为例,假定标记样本集合为L,测试集合为T,学习过程受限于以下优化问题:
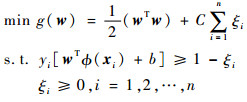
|
(1) |
式中:g(w)为优化函数;w为超平面的法向量;b为位移,衡量点到超平面的距离;ξi为松弛变量,表征数据点xi能够容许的偏移量,xi为一个样本特征向量; yi为样本类别;C为惩罚因子,用以衡量最大间隔的范围以及最小误差之间的权重;ϕ(xi)将原来的样本映射到新的高维空间,使样本更具有可分性;n为训练样本个数。
SVM的输出f(xi)=wTϕ (xi)+b具有一定的物理意义。其绝对值越大,表示离分类面越远,此时样本类别可靠性越高;其绝对值越小,表示离分类面越近,此时样本类别可靠性越低。对于多分类SVM,各个二分类SVM的输出之和能够有效衡量样本到各个分类面的距离,因此同样满足值越大,属于某个类别的概率越大的规律。很多半监督算法利用SVM的这一特点,吸收可靠性较高的样本加入到初始标记样本集中,以此扩充训练样本集[15]。
针对SVM的多分类问题,主要有“一对其余法”和“一对一法”。这2种方法都是通过将多分类问题转化成多个2类问题来进行解决。在“一对其余法”的训练中,对于具有k个类别的样本,需要训练k个SVM二分类器。在构造第i个SVM时,第i个类别的样本标记为正类,其他不属于i类别的样本标记为负类。可以看出,当k比较大时,负类样本数量远大于正类样本数量。对于“一对一法”,该方法在每2类样本间训练一个分类器,因此对于一个k分类问题,将有k(k-1)/2个分类器。
LDA算法通过寻找一个子空间使同类样本尽量靠近,异类样本尽量远离,广泛应用于图像降维和分类中[26]。以二分类为例:给定数据集{(x1, y1), (x2, y2), …, (xi, yi), …,(xm, ym)}, yi∈{0, 1}。令ui和Ci分别为第i∈{0, 1}类的均值向量和协方差矩阵。w为投影向量。欲使同类样本的投影点尽可能接近,可以使同类样本的协方差尽可能小,即wTC0w+wTC1w尽可能小;而欲使异类样本投影点尽可能远离,可以使类中心之间距离尽可能大,即||wTu0-wTu1||22||尽可能大。同时考虑二者,则可得到最大化的目标函数:

|
(2) |
定义类内散度矩阵以及类间散度矩阵分别为
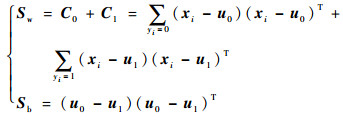
|
(3) |
则根据式(3),式(2)可重新表示为

|
(4) |
这被称为广义瑞利商。
接下来将LDA推广到多分类任务中。假定存在k个类,且第i类样本数为ni。定义全局散度矩阵为

|
(5) |
式中:

|
(6) |
由式(5)和式(6)可以得到类间散度矩阵为

|
(7) |
多分类LDA的J可以有多种实现方法,其中一种常见的构造形式仍如式(4)所示。
由于LDA从高维空间到低维空间的函数映射是线性的,然而,在不少现实任务中,可能需要非线性映射才能找到更可分的低维空间。因此此时需要非线性降维,其中一种常用的方法是基于核技巧对LDA进行“核化”得到核化线性判别分析(KLDA)[27]。
2 基于CCS的半监督分类算法首先对要用到的符号进行定义,根据是否有标签本文将训练数据集X=[L, U]∈Rd×N分为两部分,d为训练样本的维度,N为训练样本的数目。其中标记样本特征矩阵L=[x1, x2, …, xl]∈Rd×l,其对应的标签为[y1, y2, …, yl]。未标记样本特征矩阵则为U=[xl+1, xl+2, …, xl+u]∈Rd×u,l+u=N为训练样本总个数。测试样本集则为T。本文算法主要包括3个部分:未标记样本初始类别确定度获取、样本类别确定度安全处理和半监督分类器。图 1所示为本文算法流程。

|
| 图 1 本文算法流程 Fig. 1 Flowchart of proposed algorithm |
在图 1中,作为输入的L和U的维度往往较高,为了能够提取样本特征并且方便得到类别确定度,首先对样本进行降维。为了在降维过程中利用到类别信息,使得在降维后的子空间中,异类样本之间更具有可分性,采用KLDA方法。训练样本经过KLDA降维后,得到投影特征L1和U1。
在样本进行降维之后,根据标记样本训练出SVM,这主要是利用SVM的输出f(xi)=wT(xi)+b能够有效衡量样本的可靠性。由于样本一般为多类,因此要构造多分类SVM。对比“一对其余法”和“一对一法”。前者由于正负类训练样本极不均衡,有可能会造成分类面出现偏差,进而导致样本类别判决出现错误及f(xi)无法有效衡量样本的可靠性。因此本文采用“一对一法”构造多分类SVM。以获取未标记样本属于类别m的初始确定度为例,其流程如图 2所示,L1(m)表示L1降维后属于第m类别的标记样本。

|
| 图 2 多分类SVM构造及未标记样本初始类别确定度获取 Fig. 2 Multi-class SVM construction and acquisition of initial class certainty of unlabeled sampless |
首先,将L1(m)作为正类,其余类别的标记样本作为负类,两两训练出二分类SVM。之后将U1输入到每个二分类SVM中,得到对应的输出向量。例如:f(m, m-1)=(wTϕ(U1)+b)T表示U1输入到L1(m)和L1(m-1)训练出的SVM中得到的输出向量。由于输出函数较多,借鉴投票法判决类别的思想,将所有的输出向量相加得到未标记样本属于第m类别的初始确定度f(m)。此时f(m)仍然满足值越大,属于第m类别的确定性越大,值越小,属于m类别的确定性越小的性质。尽管本节只是列出了获取未标记样本U属于第m类确定度的过程,其他类别f(i), i≠m,i=1, 2, …, k,可由此推广得到,这里不再赘述。
2.2 样本类别确定度安全处理对于向量fs(i)里的元素值,当其值大于1时,属于i类的可信度很高,当其值小于-1时,属于i类的可信度很低,为了准确方便地利用f(i),本文对其进行归一化和阈值处理,归一化方法较多,本文采用min-max标准化方法得到:

|
(8) |
式中:pU(i)为未标记样本U经过归一化之后属于类别i的确定度;max和min分别为p(i)U中元素的最大值和最小值。对于阈值处理,设置阈值t,当 p(i)U里面的元素值小于预设的阈值t时,将其设置为0。即:
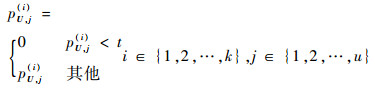
|
(9) |
其中:pU, j(i)为向量p(i)U的元素值。此时t值越大,表示对利用的未标记样本可靠性要求越高。当t=1时,未标记样本属于各个类别的确定度都为0,在之后的半监督过程中不起作用。此时半监督算法性能退化至全监督性能。当数据分布存在类间重叠等极端情况时,通过增大阈值t,可以防止半监督算法的性能恶化,有效地保证半监督算法稳定性。通过上述处理,加大了可靠样本的权重而减小了不可靠样本权重,保证利用的未标记样本拥有足够的可信度。
之后计算标记样本L的类别确定度,设属于i类别的原始标记样本集为L(i)。显然,对于L(i),其属于i类别确定度为1,属于其他类别则为0。因此,标记样本L=[x1, x2, …, xl]属于i类别的确定度向量可以表示如下:

|
(10) |
式中:pL, j(i)为向量pL(i)的第j个元素值;yj为样本xj的标签。因此对于所有的样本X,其属于i类别的确定度如式(11)所示:

|
(11) |
为了充分利用未标记样本的信息,本文接下来对原始训练集数据进行半监督LDA降维,其原理是将上述获得的样本类别确定度融入到散度矩阵中得到新的目标函数,从而使样本在投影后的子空间中更具有可分性。首先重新定义类内均值向量ui和总均值向量u分别为

|
(12) |
全监督LDA中均值向量代表了样本的特征平均值。如果将样本特征映射到空间中,设每个样本的密度为1,那么此时的均值向量就是每个类的质心。借鉴这个思想,本文将样本X属于各个类别的确定度作为密度,样本属于该类别可靠性越高,则密度越大,对该类质心位置影响越大,反之则越小。由于充分融入了未标记样本的特征信息,使得求出的均值向量更加真实可靠,而且对噪声不敏感。
接下来,为了得到“广义瑞利商”优化函数,定义新的散度矩阵如下:

|
(13) |

|
(14) |
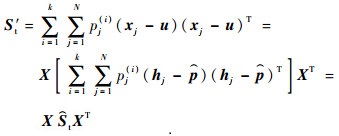
|
(15) |
式中:pj(i)为向量p(i)的元素值;hj∈RN×1中元素的数学表达式如下:

|
(16) |
其中:hj, i为向量hj的元素值。
从式(13)~式(15)可以看出,不同于全监督LDA的是,本文在类间散度矩阵Sb中改变了ni的定义,在类内散度矩阵Sw和全局散度矩阵St中添加了pj(i)作为权重。当样本属于该类别的确定度越小时,pj(i)值越小,对散度矩阵的影响越小,反之则越大。这样做不仅充分融入了未标记样本的信息还减小了错分样本的影响,从而使得散度矩阵能够代表更加真实准确的样本分布信息。
可以证明新的散度矩阵仍然满足St=Sb+Sw,因此在构造新的广义瑞利熵时,可以采用三者中的任意两者。以Sw和Sb为例,表示如下:

|
(17) |
式中:w∈Rd×(N-1)。式(17)可通过如下广义特征值来求解:
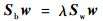
|
(18) |
式中:λ为拉格朗日乘子。w的闭式解则是Sw-1Sb的N-1个特征向量组成的矩阵。可以看出其求解是非常简单的。
由于上述的半监督降维是线性降维,接下来,本文利用核方法将其推广到非线性降维中,得到核化半监督LDA。首先对样本X进行非线性变换X→Φ(X),根据式(13)、式(14)、式(17),核化目标函数可表示为

|
(19) |
根据可再生核希尔伯特空间的有关理论可知,式(19)问题的任何解w∈F都处在所有训练样本张成的子空间中。由于本文样本的类别确定度信息是由SVM得出来的,在标记样本较少时,处于分类面附近的未标记样本属于每个类别的确定度都会比较低。为了减小这部分样本在核化过程中的影响,将w表示如下:

|
(20) |
式中: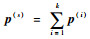
接下来将式(20)代入到式(19)得到:

|
(21) |
式中:K为核函数矩阵,按照式(18)的方法即可求解出a,最后代入到式(20)求解出w。
依照上述算法对测试样本进行半监督降维后,需要对其进行分类,此时采用最近邻分类器(Nearest Neighbor Classifier,NNC)。这是因为训练集样本在降维后,同类样本往往较近,异类样本相距较远。此时投影后的均值向量充分代表了每个类别的特征信息。降维之后的均值向量可表示为

|
(22) |
将其作为最近邻分类器的标记样本,测试样本的类别即为距离其最近的
本文设计了相关实验对本文算法性能进行衡量。实验一共分成3个部分:首先是对本文算法进行探讨,验证本文算法有关步骤的有效性;之后对本文算法与全监督算法进行实验,比较两者性能上的差异性;最后将本文算法与其他半监督算法进行实验,对结果进行比较。实验采用数据集包括2部分:训练样本和测试样本。其中训练样本选择了T72系列主战坦克(sn_132)、BMP2系列六轮履带式装甲车(sn_c21)以及BTR70装甲(sn_c71)。3种训练目标的光学图像如图 3所示,SAR图像如图 4所示。虽然3种车辆的光学图像的差异明显,但是对应的SAR图像在视觉上无法分辨:它们的空间和谱特征十分相似,而且由于斑点噪声的影响,加大了识别的难度。实验选用T72(sn_s7)、BMP2(sn_c9566)、BTR70(sn_c70)作为测试样本,可以看出,训练样本与测试样本的同类目标的型号不同,使得目标分类难度增大。表 1展示出了训练样本与测试样本的种类及样本数量。

|
| 图 3 3种训练目标的光学图像 Fig. 3 Optical images of three kinds of training objective |

|
| 图 4 3种训练目标的SAR图像 Fig. 4 SAR images of three kinds of training objective |
| 样本种类 | 训练样本 | 测试样本 | ||||
| T72 (sn_132) |
BMP2 (sn_c21) |
BTR70 (sn_c71) |
T72 (sn_s7) |
BMP2 (sn_c9566) |
BTR70 (sn_c70) |
|
| 样本数/幅 | 232 | 232 | 232 | 191 | 191 | 191 |
3.1 算法分析
本文算法在获取未标记样本的类别确定度时,首先使用了KLDA对原始样本数据进行监督降维,为了验证使用KLDA的有效性,将其置换成核化主成分分析(Kernel Principal Component Analysis, KPCA)算法这种被广泛使用的无监督降维算法,并将两者对分类精度的影响进行对比。在训练样本中每类选取相同比例的样本作为初始标记样本集,得到CCS使用上述2种降维算法分类精度走势如图 5所示,KLDA-CCS表示使用KLDA进行原始数据的降维,KPCA-CCS表示使用KPCA进行原始数据的降维。

|
| 图 5 不同降维算法对本文算法分类精度影响走势 Fig. 5 Classification accuracy trend of proposed algorithm with different dimension reduction algorithms |
从图 5可知,不同降维算法的分类精度的差异十分明显:KLDA-CCS的分类精度明显高于KPCA-CCS,标记样本比例越小,差异越大。标记样本数增加时,差异有所减小。这是因为当标记样本较少时,相比于KPCA,KLDA利用了样本类别差异,吸收了标记样本类别信息,使其具备良好的样本特征表征能力;当标记样本数增加时,KPCA足够表征未标记样本,使得KPCA与KLDA性能接近。上述实验证明了对原始样本数据进行降维时使用KLDA进行降维的有效性。
在获取未标记样本的类别确定度时,为了提高未标记样本的安全性,本文对类别确定度进行了阈值处理,接下来分析阈值t的变化对分类性能的影响进行探讨。通过选取几个典型的t值,得到对应的分类精度走势图(见图 6),来说明在实际中如何取t值。

|
| 图 6 不同阈值设置时本文算法的分类精度走势 Fig. 6 Classification accuracy trend of proposed algorithm with different threshold setting |
当t=0.2时,分类精度最高,t=0次之。随着标记样本比例的增加,两者的分类性能逐渐靠近。当标记样本的比例达到15%时,t=0的分类精度超越前者。当阈值t设置较大时,如t=0.7,t=1时,分类精度降低。
从上述实验可知,在标记样本很少时,相比于t=0利用所有的未标记样本类别确定度信息,通过设置合理的阈值,使得在半监督过程中利用的未标记样本具有一定的可信度,有效地提高了分类性能。随着标记样本数的增加,利用多分类SVM获取的样本类别确定度的可信度提升,进而可以放宽阈值,调整为t=0,利用所有的未标记样本信息,达到最好的分类效果。因此在实际应用中,只需在标记样本很少时设置较小的t值,标记样本增多设置t=0即可。针对t值较大分类精度较低的现象,是因为此时对利用的未标记样本可靠性要求很高,CCS吸收未标记样本信息较少,导致半监督降维时,样本在投影后的子空间可分性不好。
最后,本文利用可视化图形来验证本文算法中的半监督LDA的有效性,如图 7所示,test-BMP2表示从BMP坦克中挑选的一个测试样本,u-BMP2,u-BTR70,u-T72表示各类均值向量,箭头所指类别表示利用NNC算法对测试样本的判决结果,图中的点均表示投影后的向量。

|
| 图 7 3类标记坦克样本在LDA和半监督LDA中的二维特征 Fig. 7 Two-dimensional feature of three kinds of labeled tank samples in LDA and semi-supervised LDA |
可以看出在LDA中,同类样本降维后相距很近,LDA只是借助于标记样本进行分类,因此类均值向量就在标记样本附近,根据NNC算法,test-BMP2样本相距T72的均值向量最近,因此样本被错分为T72类别。与LDA不同,半监督LDA中的类均值向量与标记样本相距较远。这是因为半监督LDA通过充分吸收未标记样本的特征信息,使得降维后的类均值向量更能代表真实的样本特征分布,同时,测试样本更加靠近其所属类别的类均值向量。如图 7(b)所示,此时test-BMP2明显相距u-BMP2最近,样本分类为BMP2,这也是本文算法对原始样本数据进行降维时采用KLDA而不是LDA的原因。
3.2 与全监督算法的比较为了验证本文算法的有效性,将其与使用LDA进行降维,之后利用NNC进行分类的全监督算法(LDA-NNC)进行性能对比。同时,当本文算法中使用核方法时,称此时算法为核化CCS(KCCS)。因此同样为了验证KCCS的有效性,本文将其与KLDA-NNC算法进行比较。在训练样本中每类选取相同比例的样本作为初始标记样本集,得到不同算法的分类精度走势图,如图 8所示。
从图 8可知,在标记样本比例小于20%时,本文算法的分类精度明显高于全监督算法LDA-NNC,KCCS的分类精度明显高于KLDA-NNC。当标记样本比例达到40%时,半监督算法与全监督算法性能差异较小。另外,在标记样本比例达到10%时,此时本文算法以及KCCS的分类精度已比较接近收敛值,相比全监督算法能够更快地收敛。

|
| 图 8 全监督算法与本文算法的分类精度走势 Fig. 8 Classification accuracy trend of supervised algorithm and proposed algorithm |
上述实验说明了在标记样本较少时,本文算法以及KCCS有效提高了分类器的泛化性能。当标记样本增多时,此时的标记样本具有足够的特征表达能力,能够训练出一个性能较好的分类器,使得全监督算法的分类精度逐渐接近半监督算法。另外对比图 8各曲线可知,核化之后的KCSS算法分类性能得到了提高,这说明本文遥感数据在原空间中线性可分性不好,通过核化寻找到一个更高维度的线性可分空间。因此针对不同的数据可以选择核化或者非核化的方法进行样本的降维。这也是本文算法采用KLDA而不是LDA对原始数据进行降维的原因。
3.3 与其他半监督算法的比较为了进一步验证本文半监督算法CCS的有效性,选取其他4种半监督算法进行对比,包括标签传播(Label Propagation,LP)[28]、PS3VM-D[15]、限制K均值聚类(Constrained KMeans,C-KMeans)[29]、SDA(Semi-supervised Discriminant Analysis)算法[30]。其中LP通过建立相似矩阵,将标记样本的标签按相似程度传播给未标记样本;PS3VM-D通过利用样本间的相似性提取可靠的增量样本加入到初始标记样本集;C-KMeans通过添加“勿连”与“必连”约束对分类进行指导;SDA则是通过向LDA中添加正则式进行半监督分类。由于本文算法、SDA建立在LDA的基础上,因此为了保证比较的公平性,LP、PS3VM-D、C-KMeans事先利用LDA对原始数据进行降维,以此能够得到更准确的特征。在训练样本中每类选取相同比例的样本作为初始标记样本集,得到不同算法随标记样本比例变化的分类精度走势图,如图 9所示。

|
| 图 9 不同半监督算法的分类精度走势 Fig. 9 Classification accuracy trend of different semi-supervised algorithms |
从图 9可以看出,在标记样本较少时,本文算法分类精度最高,相比其他半监督算法始终高出至少8%的分类精度,而SDA次之,说明了基于LDA的半监督算法拥有良好的分类性能。对于LP、PS3VM-D、C-KMeans算法,由于事先利用了LDA进行降维,否则与本文算法的分类精度差异会更加的明显。本文分析可知,LP、PS3VM-D是通过迭代的方式向未标记样本赋予伪标签,样本的标签一旦出错,便会影响后续分类器的训练,导致分类器性能提升不高;C-KMeans算法通过添加约束条件并不能充分利用未标记样本样本的谱信息;SDA重在保持样本之间的邻域关系,但是对数据分布要求较高。而本文算法一方面基于LDA充分地利用了标记样本的类别信息,另一方面通过将未标记样本的类别确定度融入到半监督过程中,可靠地吸收了未标记样本的特征信息,使得在标记样本极少时算法更加稳定和准确。此外,本文算法并不需要像LP、PS3VM-D一样进行迭代,也不需要像SDA建立图模型矩阵,算法较为简单。
4 结论1) 创新性地利用训练样本降维和一对一SVM,有效地赋予了未标记样本类别确定度信息。
2) 通过对类别确定度预处理,提高了类别确定度利用的安全性。
3) 基于样本类别确定度推导了半监督LDA降维算法,并通过核化方法将其推广到非线性降维领域中,根据降维后的数据特点,采用NNC进行测试样本的分类。
采用MSTAR数据库中的BMP2、T72、BTR70系列样本作为数据集,通过一系列实验验证了本文算法有关步骤的有效性;证实了本文算法相比全监督算法可以得到更高的分类精度以及具有更好的鲁棒性;验证了本文算法相比其他半监督算法可以更好地适应标记样本缺乏时的情况,表现出了良好的精确度和稳定性。
| [1] | SUN H, LIU S, ZHOU S L, et al. Unsupervised cross-view semantic transfer for remote sensing image classification[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13 (1): 13–17. DOI:10.1109/LGRS.2015.2491605 |
| [2] | CAVALLARO G, MURA M D, BENEDIKTSSON J A, et al. Remote sensing image classification using attribute filters defined over the tree of shapes[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54 (7): 3899–3911. DOI:10.1109/TGRS.2016.2530690 |
| [3] | BOVOLO F, BRUZZONE L, CARLIN L. A novel technique for subpixel image classification based on support vector machine[J]. IEEE Transactions on Image Processing, 2010, 19 (11): 2983–2999. DOI:10.1109/TIP.2010.2051632 |
| [4] | BRUZZONE L. An approach to feature selection and classification of remote sensing images based on the Bayes rule for minimum cost[J]. IEEE Transactions on Geoscience and Remote Sensing, 2000, 38 (1): 429–438. DOI:10.1109/36.823938 |
| [5] | CABEZAS J, GALLEGUILLOS M, PEREZ-QUEZADA J F. Predicting vascular plant richness in a heterogeneous wetland using spectral and textural features and a random forest algorithm[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13 (5): 646–650. DOI:10.1109/LGRS.2016.2532743 |
| [6] | XIA J S, DU P J, HE X Y, et al. Hyperspectral remote sensing image classification based on rotation forest[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11 (1): 239–243. DOI:10.1109/LGRS.2013.2254108 |
| [7] | SHAHSHAHANI B M, LANDGREBE D A. The effect of unlabeled samples in reducing the small sample size problem and mitigating the Hughes phenomenon[J]. IEEE Transactions on Geoscience and Remote Sensing, 1994, 32 (5): 1087–1095. DOI:10.1109/36.312897 |
| [8] | COZMAN F G, COHEN I.Unlabeled data can degrade classification performance of generative classifiers[C]//Proceedings of 15th International Florida Artificial Intelligence Society Conference.Reston: AIAA, 2002: 327-331. |
| [9] | PASOLLI E, MELGANI F, TUIA D, et al. SVM active learning approach for image classification using spatial information[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52 (4): 2217–2233. DOI:10.1109/TGRS.2013.2258676 |
| [10] | BLUM A, CHAWLA S.Learning from labeled and unlabeled data using graph mincuts[C]//Proceedings of 8th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc., 2001: 19-26. |
| [11] | ROSENBERG C, HEBERT M, SCHNEIDERMAN H.Semi-supervised self-training of object detection models[C]//Proceedings of the 7th IEEE Workshops on Application of Computer Vision.Piscataway, NJ: IEEE Press, 2005: 29-36. |
| [12] | BLUM A.Combining labeled and unlabeled data with co-training[C]//Proceedings of the 7th Annual Conference on Computational Learning Theory.Piscataway, NJ: IEEE Press, 2000: 92-100. |
| [13] | DÓPIDO I, LI J, MARPU P R. Semisupervised self-learning for hyperspectral image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 51 (7): 4032–4044. DOI:10.1109/TGRS.2012.2228275 |
| [14] | JOACHIMS T.Transductive inference for text classification using support vector machines[C]//Proceedings of the 6th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc., 1999: 200-209. |
| [15] | PERSELLO C, BRUZZONE L. Active and semisupervised learning for the classification of remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52 (11): 6937–6956. DOI:10.1109/TGRS.2014.2305805 |
| [16] | ZHOU Z H, LI M. Tri-training:Exploiting unlabeled data using three classifiers[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17 (11): 1529–1541. DOI:10.1109/TKDE.2005.186 |
| [17] | TRIGUERO I, GARCIA S, HERRERA F. SEG-SSC:A framework based on synthetic examples generation for self-labeled semi-supervised classification[J]. IEEE Transactions on Cybernetics, 2015, 45 (4): 622–634. DOI:10.1109/TCYB.2014.2332003 |
| [18] | NIGAM K, MCCALLUM A K, THRUN S, et al. Text classification from labeled and unlabeled documents using EM[J]. Machine Learning, 2000, 39 (2-3): 103–134. |
| [19] | CHAWLA N, KARAKOULAS G. Learning from labeled and unlabeled data:An empirical study across techniques and domains[J]. Journal of Artificial Intelligence Research, 2005, 23 (1): 331–366. |
| [20] | LE T B, KIM S W.A hybrid selection method of helpful unlabeled data applicable for semi-supervised learning algorithms[C]//Proceedings of the 18th IEEE International Symposium on Consumer Electronics.Piscataway, NJ: IEEE Press, 2014: 1-2. |
| [21] | LI Y F, ZHOU Z H. Towards making unlabeled data never hurt[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37 (1): 175–188. DOI:10.1109/TPAMI.2014.2299812 |
| [22] | LIU X, SONG M L, TAO D C, et al. Random forest construction with robust semisupervised node splitting[J]. IEEE Transactions on Image Processing, 2015, 24 (1): 471–483. DOI:10.1109/TIP.2014.2378017 |
| [23] | CHAPELLEO, ZIEN A.Semi-supervised classification by low density separation[C]//Proceedings of the 10th International Workshop on Artificial Intelligence & Statistics, 2005: 1-8. |
| [24] | LI Y F, KWOK J T, ZHOU Z H.Semi-supervised learning using label mean[C]//Proceedings of the 16th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc., 2009: 633-640. |
| [25] | ANDREW A M. An introduction to support vector machines and other kernel-based learning methods[J]. Kybernetes, 2001, 32 (1): 1–28. |
| [26] | MOSKOWITZ L. The LDA-An integrated diagnostics tool[J]. IEEE Aerospace & Electronic Systems Magazine, 1986, 1 (7): 22–26. |
| [27] | KOCSOR A, TOTH L. Kernel-based feature extraction with a speech technology application[J]. IEEE Transactions on Signal Processing, 2004, 52 (8): 2250–2263. DOI:10.1109/TSP.2004.830995 |
| [28] | ZHU X, GHAHRAMANI Z.Learning from labeled and unlabeled data with label propagation[C]//International Joint Conference on Neural Networks, 2003: 2803-2808. |
| [29] | WAGSTAFF K, CARDIE C, ROGERS S, et al.Constrained K-means clustering with background knowledge[C]//Proceedings of the 8th International Conference on Machine Learning.San Francisco: Morgan Kaufmann Publishers Inc., 2001: 577-584. |
| [30] | CAI D, HE X, HAN J.Semi-supervised discriminant analysis[C]//Proceedings of the IEEE 11th International Conference on Computer Vision.Piscataway, NJ: IEEE Press, 2007: 9848913. |