



2. 北京航天飞行控制中心, 北京 100094;
3. 武汉工程大学 智能机器人湖北省重点实验室, 武汉 430205;
4. 中国载人航天办公室, 北京 100720;
5. 东北师范大学 计算机科学与信息技术学院, 长春 130017
2. Beijing Aerospace Control Center, Beijing 100094, China;
3. Hubei Provincial Key Laboratory of Intelligent Robot, Wuhan Institute of Technology, Wuhan 430205, China;
4. China Manned Space Engineering Office, Beijing 100720, China;
5. School of Computer Science and Information Technology, Northeast Normal University, Changchun 130017, China
嫦娥三号任务主要实现中国探月计划第二阶段“落”月的目标。中国首次成功在月球上实施巡视器软着陆[1]。“玉兔号”巡视器配备全景相机、红外成像光谱仪、测月雷达、粒子激发X射线谱仪等科学载荷[2],在脱离着陆器后沿月面路线前进实施科学探测任务。每项探测任务均在地面远程遥操作的控制方式下完成[3]。“玉兔号”的控制任务与以往的轨道航天器控制任务[4-5]主要存在3点不同,对地面控制系统的设计提出了挑战:①“玉兔号”的工作计划具有动态性。其着陆位置、工作环境等都无法事先得知,月面工作计划因而不能采用提前手工生成的方法,而必须在月面巡视器到达月面后根据环境和探测目标实时、不间断地制定任务。②“玉兔号”的任务规划具有不确定性。月面环境是一个未知的复杂非结构环境,而月面环境感知主要是通过安装在车体不同位置的立体相机对,利用双目视觉测量原理恢复月面三维信息来实现[6],而科学探测目标或探测任务的选择又是建立在月面环境信息的基础上。因此,月面巡视器的移动速度、机械臂移动速度等信息将具有不确定性,使得控制任务含有不确定性。③任务规划的短时效性。为了最大程度完成科学探测目标,地面控制系统将不断更新月面环境信息。由于月面环境的不确定性,正在执行的任务规划可能在较短一段时间内失去可行性,需要进行重规划。重规划的结果需要验证和复核,耗费时间,进而影响在一定时间内能完成的科学探测任务数量。因此,具有较高自动化程度的任务规划方法的研究对月面巡视勘察任务效益的提高具有重要意义。
针对“玉兔号”控制任务的特点,笔者提出了结合自动规划(automated planning)技术[7]的自动化任务规划方法,并提出了具有动态行为持续时间和动态行为效果的时态规划模型(Temporal Planning with Dynamic Duration and Dynamic Effect, TPDD&DE)。为描述TPDD&DE类型的规划任务,设计了规划领域定义语言(Planning Domain Definition Language, PDDL)[8]的新型扩展PDDLDD&DE。为有效求解TPDD&DE问题,设计了能结合外部计算过程、基于启发式搜索技术的规划算法,运用Landmark知识分析技术设计了能对搜索节点进行更加合理评估的启发函数[9-10]。实现了求解TPDD&DE问题的规划系统,该系统在实际应用中取得了预期成功。
本文方法相比美国国家航空航天局(NASA)和欧洲空间局(ESA)采用的方法,具有明显的区别和特色:①本文方法采用以动作(action)为核心概念的任务建模方法(简称动作模型法)[8],美国和欧洲的相关项目主要采用了以时间轴(timeline)为核心概念的建模方法(简称时间轴模型法)[11-12]。时间轴模型法虽然在建模事件的持续时间方面具有较大的灵活性,但是其模型内部的约束往往涉及多个时间轴,导致这些时间轴在逻辑关系上紧密耦合,大幅增加人类专家建立模型和理解模型的难度[13]。相对而言,动作模型法具有易于人类专家理解的优势,为人类专家评估并认可规划结果提供了一种方便的途径。②在动作模型法的自动规划研究领域,本文结合外部计算过程的规划模型TPDD&DE,通过外部计算过程来分析动作在行为持续时间和行为效果上的动态性。相对于已有研究提出的建模外部环境的定时触发(命题)文字技术[14],本文的工作进一步考虑了数值型变量受外部环境的影响,将可建模的问题扩展到更广的范围。③针对TPDD&DE问题的描述需求,扩展了PDDL语言,设计了PDDLDD&DE。在规划求解方法上,运用了提出的结合Landmark问题结构知识分析技术的启发函数[12-13],实现了有效求解。
1 巡视器动态行为的规划建模“玉兔号”巡视器的行为规划问题由于行为持续时间的动态性、行为效果的动态性,因而不能采用目前已有的自动规划模型进行建模。本文通过扩展时态规划模型[8],增加对行为动态性的建模元素,提出了自动规划模型TPDD&DE。
TPDD&DE问题定义为一个七元组:∏=(V, A, I, G, TL, EP, δ)。
1) V由2个不相交的有限变量集组成:VL∪VM,变量的取值可随时间而变化。VL为(逻辑)命题变量集,f∈VL的值域为Dom(f)={T, F},T为逻辑“真”,F为逻辑“假”;VM为数值变量集,x∈VM有值域Dom(x)⊆R。
2) A为动作集, 动作a∈A具有形式〈dura, Ca, Ea〉。dura为动作的持续时间;Ca为a的执行条件集合(简称条件集),描述在开始执行时刻必须成立的条件、结束时刻成立的条件和执行过程中保持的条件;Ea为a的执行效果集合(简称效果集),包含动作a在开始执行时刻产生的效果和结束时刻产生的效果。对于条件c∈Ca,如果其约束逻辑变量,则具有形式:〈(stc, etc)v=d〉,d∈Dom(v);如果其约束数值变量,则有形式:〈(stc, etc)v op exp〉,op∈{>, ≥, <, ≤, ==},exp为由数值变量和常量组成的表达式。对于效果ef∈Ea,如果其影响逻辑变量,则具有形式:〈[t]v←d〉;如果其影响数值变量,则有形式:〈[t]v eop exp〉,eop∈{=,+=,-=,*=,/=}。
3) I为规划任务的初始状态,为f∈V赋予“T”或“F”,为x∈VM赋予d∈Dom(x)。
4) G为目标集,每个目标命题具有形式〈f=d〉,这些目标在规划方案执行后必须成立。
5) TL为定时触发文字的有限集,每个(命题)文字的形式为〈[t]f=d〉,表示变量f在时刻t的取值更新为d。
6) EP为从变量到其外部计算过程的映射EP:VM∪X→Procs,X={dura|a∈A},Procs为外部计算过程集。对于v∈VM∪X,变量v的值由过程EP(v)∈Procs计算。过程EP(v)通常带有多个参数,其中主要的参数为当前时刻t,为此用EP(v)(t)表示变量v在时刻t上的取值。
7) δ:A→R为动作的代价函数,表示执行a需要付出代价,δ(a)<0表示执行a获得收益。
对动作的时间语义进一步说明如下:将动作a的开始执行时刻和结束时刻分别记为sta和eta。对于动作执行条件c∈Ca,如果stc=etc=sta,则要求条件c在a的开始时刻成立,称此类条件为开始条件;如果stc=etc=eta,则要求c在a的结束时刻成立,称此类条件为结束条件;如果stc=sta, etc=eta,则要求c在开区间(stc, etc)上成立,称此类条件为持续条件。对于动作a的效果〈[t]v←d〉,如果t=sta,则该效果在动作的开始时刻发生,称此类效果为开始效果;如果t=eta,则该效果在动作的结束时刻发生,称此类效果为结束效果。
TPDD&DE模型从2个方面反映了规划系统所处的外部环境的信息。其中,定时触发文字集TL反映了逻辑命题变量随时间变化的信息;EP反映了数值型变量和动作持续时间受外部环境的影响,即数值型变量的取值和动作持续时间均可通过外部过程计算。因此,TPDD&DE模型是传统时态规划模型的推广形式。
给定一个具体的TPDD&DE问题,它的一个状态s由若干变量赋值组成。用s(v)表示s对变量v的赋值,则s(v)∈Dom(v)。状态不一定对全部变量都给出赋值,仅对一部分变量赋值的状态称为部分状态,对所有变量均赋值的状态称为完全状态。在状态s上,如果动作a的开始条件在时刻sta成立,结束条件在时刻eta成立,持续条件在开区间(sta, eta)上成立,则称a在s上可执行。a在s上执行后的状态记为apply(s, a),计算方法为:在sta时刻,按照a的开始效果更新s得到新状态s′,在eta时刻,按照a的结束效果更新s′得到s″。使用π=(〈t(a1), a1〉, 〈t(a2), a2〉, …, 〈t(am), am〉)表示动作序列,其中动作变量ai表示在第i步执行的动作,t(ai)表示它的执行时刻。对于状态s,如果π中的动作可依次执行,则称π为s上的有效动作序列。如果π为初始状态I上的有效动作序列,并且执行am后的状态满足目标集G的全部目标,则称π为TPDD&DE问题∏=(V, A, I, G, TL, EP, δ)的规划方案(或称规划解,也称规划)。π的时间跨度ms(π)为t(am)+duram。
π的代价δ(π)定义为所有动作代价的代数和∑δ(ai)。π对资源变量x的消耗量为在时刻ms(π)上x的取值与在初始状态I中x取值的差。根据时间跨度、动作代价、资源消耗等指标[15-16]可比较3个规划解π和π′的规划质量(plan quality)优劣。
面向一个具体的规划指标,可要求规划算法计算出最优的规划解,或者要求计算出一个令人满意的规划解。前一类计算问题称为最优规划(optimal planning)问题,后一类问题称为满意规划(satisficing planning)问题[15-16]。根据工程需要,将月面巡视器任务规划问题建模为满意规划问题。一般情况下,满意规划问题相对容易求解,耗时较短。
下面给出月面巡视器行为规划问题的一个简化实例,之后将介绍如何采用TPDD&DE模型来建模此实例。假定月面上有2个停泊点K和B,巡视器当前位于K,其任务目标是在B处完成探测工作。巡视器当前能量为80,在相对时刻30开始处于太阳光照区域。任务约束为:在探测之前巡视器的能量应大于50,在探测动作的执行过程中应一直处于太阳光照区域。从K到B的移动动作的持续时间和能量消耗分别由外部过程proc1和proc2计算。在B处进行探测动作的持续时间和能量消耗分别由外部过程proc3和proc4计算。设外部过程在部分时刻的输出值如下:proc1(0)=10,proc2(0)=20,proc3(30)=15,proc4(30)=50。即在时刻0执行移动动作的持续时间是10、能量消耗是20,在时刻30执行探测动作的持续时间是15、能量消耗是50。这个规划实例在时间跨度指标上的最优解是:在时刻0执行从K到B的移动动作,在时刻30执行探测动作。
运用本文提出的TPDD&DE模型,对上述实例进行建模,具体建模过程如下:设逻辑变量集VL={at_K, at_B, reachable_K_B, in_sun, work_done}。各逻辑变量的含义如下:at_K=T表示巡视器在停泊点K,at_B=F表示巡视器不在停泊点B,reachable_K_B=T表示停泊点K和B在空间上可达,in_sun=T表示巡视器处于光照范围内,work_done=F表示探测工作未完成。设数值变量集VM={energy, eng_consume1, eng_consume2},energy变量建模巡视器的电量值,其余2个变量表示电量消耗。初始状态I={at_K=T, at_B=F, reachable_K_B=T, in_sun=F, work_done=F}。目标集G={work_done=T}表示任务目标为要完成探测工作。
巡视器的行为建模如下:K、B 2点间的移动动作moveKB=〈durm, Cm, Em〉,它的条件集Cm={〈(stm, stm)at_K=T}〉, 〈(stm, stm)reachable_K_B=T〉, 〈(stm, stm)energy≥80〉},它的效果集Em={〈(etm, etm)at_B=T〉, 〈(etm, etm)at_K=F〉, 〈(etm, etm)energy-=eng_consume1〉}。在B点工作的动作workB=〈durw, Cw, Ew〉,它的条件集Cw={〈(stw, stw)at_B=T〉, 〈(stw, stw)energy≥30〉, 〈(stw, stw)work_done=F〉},它的效果集Ew={〈(etw, etw)energy-=eng_consume2〉, 〈(etw, etw)work_done=T〉}。定时触发文字集TL={〈[30]in_sun=T〉}表示巡视器在时刻30处位于光照范围。变量与外部计算过程的对应关系为:EP(durm)=proc1,EP(eng_consume1)=proc2,EP(durw)=proc3,EP(eng_consume2)=proc4,表示变量durm、eng_consume1、durw和eng_consume2的取值分别由外部过程proc1、proc2、proc3和proc4计算。
2 巡视器控制任务的规划描述语言规划问题的数学模型较抽象,不易于人类的理解和计算机处理。PDDL语言提供了较为直观的语义,成为自动规划研究中规划问题描述语言的实际规范[15-16]。为了描述月面巡视器控制任务中的动态行为以及动态性的外部计算过程,设计了PDDL语言的扩展PDDLDD&DE,用于对规划任务中动态行为的描述。
本文讨论的规划问题的动态性表现在2个方面:一方面在于动作持续时间的动态性;另一方面在于资源变量的动态性。为此,应通过扩展语言结构来支持这2个动态性的描述。动态性的确定化依赖于外部计算过程,因此,应支持外部计算过程的描述,并能描述动态性与外部计算过程的关联。在PDDL语言的基础上,在规划域描述结构中增加对外部过程的说明,用元标记“:processes”标识外部计算过程的说明部分。在该部分,定义名如proc1和proc2的外部计算过程。在之后的动作定义部分,将运用这些外部过程来建模动作的动态性。
为了建立动作的持续时间与外部计算过程的对应关系,在动作持续时间声明部分允许出现外部过程名。为建立资源变量的变化与外部过程的关系,在动作效果部分,允许外部过程名出现在效果表达式中。如第1节中的操作move的结构知识采用PDDLDD&DE建模,形成如图 1所示的操作模型(说明:操作move的参数分别绑定为地点K和B后,可得到动作moveKB)。在图 1中,使用(=?duration proc1)描述操作的持续时间由外部过程proc1计算;用(decrease energy proc2)描述资源变量energy的降低数量由proc2计算。当然,采用这2种结构也能够描述其他资源变量与外部计算过程的映射关系。

|
| 图 1 动作持续时间和资源变量与外部计算过程的映射 Fig. 1 Description of mappings from action durations and resource variables to external computation procedures |
运用在建模语言PDDL基础上设计的扩展语言PDDLDD&DE,能够对“玉兔号”巡视器的行为模型和“玉兔号”面对的某一具体任务进行建模。行为模型与对象类型定义、函数定义、外部计算过程定义等一起形成规划领域模型文件Domain.pddl,具体任务所涉及的对象实例、初始状态与目标等描述一起形成规划任务文件Problem.pddl。规划系统以这2个文件为输入,开始进行规划解的计算。
3 巡视器动态行为的规划方法针对本文提出的规划问题TPDD&DE,设计了基于贪婪最好优先搜索(greedy best-first search)[17]框架的规划算法。本文算法的主要不同在于:在搜索的过程中与外部计算过程交互,并在设计的启发函数的引导下对有希望的节点进行优先探索。规划算法采用一个Open表记录待扩展的节点,使用一个Closed表记录已经扩展的节点。运用Closed表可防止算法因搜索空间存在环而陷入无限循环,从而避免算法在有限图上产生不完备。
由于本文考虑的规划问题涉及时间和定时触发文字,搜索空间的节点不仅应记录当前的状态,而且应记录当前时间等信息。节点的数据结构与文献[18]相同,具体如下:节点n为六元组(t, P, M, H, E, pl),t为节点n对应的时刻(时间戳),P记录各命题变量取“真”的最近时间,表示为集合{〈pi, ti〉|ti<t},M记录数值型变量在当前时刻t的取值,H记录已经执行的动作的持续条件,E记录将来发生的事件集,pl记录从初始节点到节点n所经历的动作序列。与文献[18-19]等类似,设定离散时间点之间存在一个微小的间隔λ。本文的规划算法采用上述节点结构,首先根据规划问题的初始状态构造初始节点,然后通过迭代不断扩展搜索空间。算法的主体流程如图 2所示。图中使用n.pl来表示节点n的pl元素,其他元素的表示法相同。

|
| 图 2 TPDD&DE规划算法主体流程 Fig. 2 Main procedure of TPDD&DE planning algorithm |
外部计算过程在算法中的作用是用来生成节点n上的可用动作集App(n)。算法将考察动作集A中的每个动作a,判断它可否在节点n所代表的状态上应用(执行),此判断过程将依据a的持续时间、前提和预期执行效果。设a的持续时间是动态的,由外部过程proc计算,则算法根据节点n的时间戳n.t,调用proc(n.t)可获得a的持续时间。以相同的方式,可获取给定数值变量v在n.t时刻的取值。在去除动作a的动态性之后,可根据时态规划模型的语义[18]完成此动作的应用结果计算,从而得到节点n的子节点n′。
图 2的算法是正确的,且对于有限空间是完备的。算法的正确性通过2个方面保证:①在节点扩展过程中遵照时态规划动作的语义[18];②当扩展的节点中存在变量取值冲突时,该节点将不予考虑。算法的完备性主要通过Open表和Closed表机制保证,Open表存储了所有已扩展节点的子节点,而不是仅仅存储最优节点的子节点,使得算法在贪心前进无法继续时能考察其余节点。Closed表记录所有已扩展的节点,避免某节点被多次重复扩展,从而防止算法陷入搜索空间中的环状通路。
本文规划算法的主要特色在于启发函数h的设计,该函数评估每个节点与目标的标量距离,即

|
(1) |
式中:S为全体状态构成的集合。
对于搜索空间中的节点n,定义了n对应的状态sn为
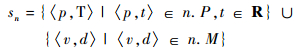
|
(2) |
即sn包含了节点n上所有命题变量和所有数值变量的取值。
为了合理估计状态s的目标距离,使用了文献[10]中定义的启发函数htpcc。总体上看,状态s的目标距离定义为s与目标集G中每个目标g的距离的代数和,如下:
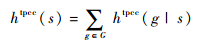
|
(3) |
状态s与单个目标g的距离分3种情况定义。
1) 若g∈s,则

|
(4) |
2) 若g不是比较型逻辑变量且g∉s,则
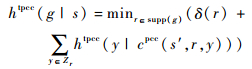
|
(5) |
3) 若g为比较型逻辑变量且g∉s,则
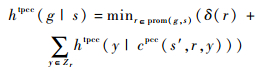
|
(6) |
式中:规则r由动作映射得到[10];Zr为r的前提集合;supp(g)为能添加命题g的规则集;cpcc(s′, r, y)为在状态s′上应用规则r来实现命题y后所导致的状态s的更新;prom(g, s)为在状态s上有希望(promising)实现目标g的规则。
函数cpcc的计算主要依赖对Landmark的分析技术[20],最终产生了更加合理的目标距离估计,用下面的实例说明启发函数的合理性。
月面上有2个停泊点l0和l1,巡视器当前位于l1,目标是在l1处执行探测动作WA。WA有2个前提:p1: 〈电能高于20〉,p2:〈位于l1〉,其执行代价为30。巡视器当前电能为10,因光照原因不能在l1充电只能在l0充电。此外,从l0移动到l1的代价为10,反方向移动代价也为10;充电的代价为50。
如果不采用Landmark分析技术,简单地假设p1和p2是无关的,则从当前状态实现p1的代价为10+50(从l1移动到l0产生代价10,充电产生代价50),实现另一个前提p2的代价为0(因为根据假设,函数cpcc的值与当期状态相同,包含了p2),因此得出,完成目标的总代价为:60+0+30=90,其中满足WA执行前提p1的代价是60,满足WA的另一个执行前提p2的代价是0,WA的执行代价是30。
当采用Landmark分析技术后,得出命题p1和p2相关,在成立顺序上,p1应该在p2之前成立,而且p2的实现代价计算应该以p1的实现代价计算结果为出发点。因此,在得出p1的实现代价60之后,函数cpcc能考虑到巡视器为实现p1而将位置改变到了l0,从而在计算p2的实现代价过程中,发现从l0移动到l1会导致代价10。最终,得出当前状态的目标距离为:(60+10)+30=100。这个距离估计值实际上优于之前的估值90。
4 应用与分析在“玉兔号”月面巡视器行为规划任务中,巡视器在月面上的停泊位置称为停泊点。巡视器的行进路径由停泊点序列组成,在停泊点上可执行的运行模式有4种:移动模式、工作模式、地基运算模式和充电模式。任务设计专家可指定巡视器在某停泊点上执行上述4种模式的任意模式序列。例如,在停泊点K上,指定巡视器顺次执行工作模式、地基运算模式、充电模式、移动模式。巡视器各运行模式对应的行为模型均采用本文设计的PDDLDD&DE语言进行描述。
巡视器的任务规划指在较长一段时间内(以天数为单位),给定巡视器的初始位置及时间、目标位置、月面DEM图和探测需求,在满足巡视器的机动性能约束、通信约束、能源约束、工作模式约束、航向前提下,规划各停泊点序列和停泊点上的工作模式序列。主要约束的具体内容包括:①测控约束,是巡视器与地面遥操作系统的基本约束。该约束主要是指满足通信可见性条件,即可用测控站对巡视器的高度角满足阈值要求,连续测控弧段跟踪时满足测站切换规则要求等。②能源约束,即功率平衡,主要包含3个因素:巡视器通过太阳翼获取能量、巡视器工作时能量消耗、蓄电池充电损耗及存储能量。通过太阳翼获取的能量数与巡视器姿态、太阳高度角、太阳翼角度、太阳翼遮挡情况等相关。巡视器耗能取决于巡视器的工作模式和移动模式等。蓄电池充电量取决于电池性能及充电控制方式等。③温控约束,是指巡视器在一定太阳高度角、巡视器姿态、太阳翼角度和工作模式下,确保车体尤其是太阳翼温度在工作温度范围内,避免月昼时出现温度过高或者月夜时温度过低。④工作模式约束,是指巡视器进行月面巡视探测时必须处于确定的工作模式,包含感知模式、移动模式、科学探测模式、充电模式、月夜模式等,每种模式的执行需具备一定约束条件,各模式之间的转换也需满足特定约束。⑤工作能力约束,是指巡视器由于其自身能力限制造成的约束条件。主要指运动约束,例如巡视器移动过程中无法跨过超过一定高度的障碍,无法翻越超过一定坡度的斜坡等。
限于篇幅,不再详细介绍运用智能规划技术对巡视器行为建模的技术和结果,只概要介绍其中的建模方法,包括:①使用动作前提和动作效果来建模动作之间的逻辑关系和各项约束关系;②使用定时触发文字概念建模不受巡视器控制的外部环境的变化,如通信可用性的多个弧段;③使用外部计算过程概念建模行为与其他分析系统中计算过程的关系。
为实现巡视器任务的自动化求解,使用编程语言C++实现了本文的规划方法,形成了月面巡视器自动任务规划系统。该系统以巡视器操作模型描述文件Domain.pddl和当前任务的描述文件Problem.pddl为输入信息,计算输出形式如表 1所示的规划解。表 1中的每行描述了规划解中的1个动作,由4部分组成:动作序号、开始时刻、动作名称和持续时长。如规划解的第1个动作为EnterTrackAction xsq,其中,xsq为巡视器的拼音缩写,EnterTrackAction为进入跟踪弧段做准备的动作。按照规划的指示,巡视器应在相对时间第26 539 s执行,执行的持续时长为1 320 s。
| 序号 | 开始时刻 | 动作名称 | 持续时长/s |
| 001 | 26 539 | 〈EnterTrackAction xsq〉 | 1 320 |
| 002 | 27 859 | 〈WorkAction xsq spot0 init M0_MS_GZ〉 | 10 290 |
| 003 | 38 149 | 〈MoveAction xsq spot0 M0_MS_GZ M1_MS_YDMZ〉 | 270 |
| 004 | 38 419 | 〈MoveEffect xsq spot0 spot1〉 | 0 |
| 005 | 38 419 | 〈WorkAction xsq spot1 M1_MS_YDMZ M2_MS_GZ〉 | 10 290 |
| 006 | 48 709 | 〈MoveAction xsq spot1 M2_MS_GZ M3_MS_YDMZ〉 | 270 |
| 007 | 48 979 | 〈MoveEffect xsq spot1 spot2〉 | 0 |
| 008 | 48 979 | 〈WorkAction xsq spot2 M3_MS_YDMZ M4_MS_GZ〉 | 10 290 |
| 009 | 59 269 | 〈MoveAction xsq spot2 M4_MS_GZ M5_MS_YDMZ〉 | 270 |
| 010 | 59 539 | 〈MoveEffect xsq spot2 spot3〉 | 0 |
| 011 | 671 460 | 〈WorkAction xsq spot3 M5_MS_YDMZ M6_MS_GZ〉 | 10 290 |
| | | | |
| 027 | 776 383 | 〈MoveAction xsq spot7 M14_MS_GZ M15_MS_YDMZ〉 | 270 |
在“玉兔号”的控制过程中,自动任务规划系统形成了整个控制流程的协调中枢。在自底向上的方向,以遥操作控制中心的各分系统的预报数据为基础,通过信息融合和信息抽象,形成了具体的规划任务。在规划系统成功求解该任务后,对应的规划解以自顶向下的方式向各分系统传递。根据该规划解,分系统设定自身的(低层)控制目标,并计算相应的(低层)控制规划,随后执行各自的控制规划。因而,各分系统的协调工作主要依赖于自动任务规划系统。相对于传统的手工编制计划和协调工作的方式,巡视器控制的这种工作流程在自动化程度上达到了明显的提高。
5 结 论嫦娥三号“玉兔号”巡视器是中国首次在月面环境下开展移动探测任务。在巡视器移动探测任务中,自动地进行行为序列规划,应对月面非结构化环境和任务动态性,是对月球较大范围实施环境探知的重要技术。
1) 分析了动作持续时间动态性和动作效果动态性等特点。
2) 采用以动作为核心概念的规划思想,针对性地提出了扩展型时态规划问题模型,设计了PDDL语言的扩展PDDLDD&DE。
3) 以启发式状态空间搜索为技术框架,设计了结合外部计算过程的规划算法;在启发函数设计上,结合了规划问题的Landmark结构知识,对状态的目标距离实现了相对合理的估计,为规划算法的效率提供了积极保证。
本文设计实现的规划系统在巡视器控制流程中起到了中枢的作用,为各分系统的协调和自动化提供了新方法。“玉兔号”巡视器的自动任务规划技术有力支撑了中国首次地外天体探测与勘察的成功,为中国后续的深空着陆探测任务提供了积极的技术先导。随着航天事业的飞速发展,地球卫星、载人航天、月球探测和深空探测等航天任务均凸显出功能多样、配置灵活、组合复杂的特点,特别是针对未来多任务并行、多目标管理的飞行控制特点,需要任务规划和验证评估等方面的新型自动化技术,以达到加快任务响应速度、提高任务决策效率、优化操作控制流程、合理调配地面资源和降低人为失误危险的目的,“玉兔号”巡视器任务规划的方法和技术可在这些领域得到不断完善和发展,形成更加广泛的应用。
| [1] | IP W H, YAN J, LI C L, et al. Preface:The Chang'e-3 lander and rover mission to the Moon[J]. Research in Astronomy & Astrophysics, 2014, 14 (12): 1511–1513. |
| [2] | 吴伟仁, 周建亮, 王保丰, 等. 嫦娥三号"玉兔号"巡视器遥操作中的关键技术[J]. 中国科学:信息科学, 2014, 44 (4): 425–440. WU W R, ZHOU J L, WANG B F, et al. Key technologies in the teleoperation of Chang'E-3"Jade Rabbit" rover[J]. Science China:Information Sciences, 2014, 44 (4): 425–440. (in Chinese) |
| [3] | 贾阳, 张建利, 李群智, 等. 嫦娥三号巡视器遥操作系统设计与实现[J]. 中国科学:技术科学, 2014, 44 (5): 470–482. JIA Y, ZHANG J L, LI Q Z, et al. Design and realization for teleoperation system of the Chang'e-3 rover[J]. Science in China Series E:Technological Sciences, 2014, 44 (5): 470–482. (in Chinese) |
| [4] | 欧阳琦, 姚雯, 陈小前. 地球同步轨道卫星群在轨加注任务规划[J]. 宇航学报, 2010, 31 (12): 2629–2634. OUYANG Q, YAO W, CHEN X Q. Mission programming of on-orbit refueling for geosynchronous satellites[J]. Journal of Astronautics, 2010, 31 (12): 2629–2634. (in Chinese) |
| [5] | 李革非, 陈莉丹, 唐歌实, 等. 多约束交会对接发射窗口的分析和规划[J]. 宇航学报, 2011, 32 (11): 2463–2470. LI G F, CHEN L D, TANG G S, et al. Analysis and programming of rendezvous launch window with multi-constraints[J]. Journal of Astronautics, 2011, 32 (11): 2463–2470. (in Chinese) |
| [6] | 周建亮, 谢圆, 张强, 等. 月面巡视器遥操作中的任务规划技术研究[J]. 中国科学:信息科学, 2014, 44 (4): 441–451. ZHOU J L, XIE Y, ZHANG Q, et al. Research on mission planning in teleoperation of lunar rovers[J]. Science China:Information Sciences, 2014, 44 (4): 441–451. (in Chinese) |
| [7] | HOFFMANN J.Everything you always wanted to know about planning[C]//KI 2011:Advances in Artificial Intelligence.Berlin:Springer-Verlag,2011:1-13. |
| [8] | FOX M, LONG D. PDDL2.1:An extension to PDDL for expressing temporal planning domains[J]. Journal of Artificial Intelligence Research, 2003, 20 : 61–124. |
| [9] | CAI D B,HOFFMANN J,HELMERT M.Enhancing the context-enhanced additive heuristic with precedence constraints[C]//Proceedings of the 19th International Conference on Automated Planning and Scheduling (ICAPS).Menlo Park,California:AAAI Press,2009:50-57. |
| [10] | HU Y M,YIN M H,CAI D B.On the discovery and utility of precedence constraints in temporal planning[C]//Proceedings of the 25 th AAAI Conference on Artificial Intelligence (AAAI).Menlo Park,California:AAAI Press,2011:1788-1789. |
| [11] | RABIDEAU G,KNIGHT R,CHIEN S,et al.Iterative repair planning for spacecraft operations in the ASPEN system[C]//Proceedings of the 5th International Symposium on Artificial Intelligence,Robotics and Automation in Space.Noordwijk:ESA Publications Division,1999,440:99-106. |
| [12] | BARREIRO J,BOYCE M,FRANK J,et al.EUROPA:A platform for timeline-based AI planning,scheduling,constraint programming,and optimization[C]//Proceedings of ICAPS 2012 Workshop on Planning and Scheduling with Timelines.Atibaia:ICAPS,2012:6-7. |
| [13] | SMITH D E,FRANK J,CURSHING W.The anml language[C/OL]//Proceedings of the ICAPS 2008 Workshop on Knowledge Engineering for Planning and Scheduling (KEPS).Sydney:ICAPS,2008[2016-08-13].http://ktiml.mff.cuni.cz/~bartak/KEPS2008/download/paper07.pdf. |
| [14] | GEREVINI A, SAETTI A, SERINA I. An approach to temporal planning and scheduling in domains with predictable exogenous events[J]. Journal of Artificial Intelligence Research, 2006, 25 : 187–231. |
| [15] | EDELKAMP S,HOFFMANN J.PDDL2.2:The language for the classical part of the 4th international planning competition[R].Freiburg:Albert-Ludwigs-Universität Freiburg,2004:1-21. |
| [16] | GEREVINI A,LONG D.Plan constraints and preferences in PDDL3[R].Brescia:University of Brescia,2005:1-12. |
| [17] | HELMERT M. The fast downward planning system[J]. Journal of Artificial Intelligence Research, 2006, 26 : 191–246. DOI:10.1007/s10462-007-9049-y |
| [18] | DO M B, KAMBHAMPATI S. Sapa:A multi-objective metric temporal planner[J]. Journal of Artificial Intelligence Research, 2003, 20 : 155–194. |
| [19] | EYERICH P, MATTMVLLER R, RÖGER G. Using the context-enhanced additive heuristic for temporal and numeric planning[M]. Heidelberg: Springer, 2012: 49-64. |
| [20] | HOFFMANN J, PORTEOUS J, SEBASTIA L. Ordered landmarks in planning[J]. Journal of Artificial Intelligence Research, 2004, 22 : 215–278. |