



汉字识别技术的研究是社会科技发展的关键因素.在高度信息化的时代,如何让计算机高效地识别出如此之多的汉字,特别是印刷体汉字信息,是汉字识别领域的重要问题.印刷体汉字识别有着很高的实用价值,在中文信息处理、文本行识别和自动化办公等领域都有重大的理论意义和应用价值.印刷体汉字识别最早可追溯到20世纪60年代,IBM公司的Casey和Nagy利用简单模板匹配法识别出1000个印刷体汉字[1].20世纪70年代初,日本研究员也开始研究汉字识别技术并成功研制出能识别2000~4000个印刷体汉字和特定手写体汉字的设备.中国的光学字符识别(OCR,Optical Character Recognition)研究起源于20世纪70年代末,主要针对数字、字母和符号的识别.20世纪80年代末,中国已在文字识别领域上取得了丰硕的成果,在汉字建模和识别方法上都有所创新,OCR产品开始走向市场[2].如今人工智能技术飞速发展,机器学习与模式识别等领域出现了很多新的成就和突破,如神经网络、自然语言处理等.如何吸取这些先进的技术,把他们更好地运用到文字识别中,是一个需要长期研究和努力的方向[3].
特征提取和选择是汉字识别的关键.随着汉字分类技术研究的深入,文字的特征表达和描述已经取得了长足的发展.总体上汉字特征分为统计特征和结构特征.统计特征建立在二值或灰度点阵图像之上,它将点阵图像从整体上进行处理,在较高的层次上进行统计,如全局变换特征和笔画穿透数特征.这类特征易于提取且往往具有良好的鲁棒性和较好的抗噪声能力,但对局部信息的敏感度不够,区分相似字的能力较差.结构特征则是字符的本质特征.它描述了字符的拓扑结构,对字体变形影响较小,对相似字的区分效果好,如汉字特征点特征,但这类特征易受噪声等干扰.为更好地结合各自的优点,本文采用一种适用于汉字分类的特征描述子,通过多尺度滑动窗的方式提取文字的全局特征和局部特征.滑动窗的思想由法国研究员Dalal和Triggs在静态图像和视频行人检测问题上提出,利用滑动窗口技术计算图像局部区域的梯度方向直方图来构成特征,对图像几何和光学的变形都能保持很好的不变性[4].
神经网络(ANN)是人类在对其大脑神经网络认识理解的基础上构造的能够实现自动信息处理的机器系统[5].由于其具有有效的学习、模仿人脑智能等方面的能力而广泛地被应用于模式识别、图像处理等领域.文字识别是一个模拟人类认知过程的问题,因此,将神经网络应用于文字识别一直是体现神经网络性能的一个重要应用领域[6, 7, 8].本文使用一个5层的深度神经网络模型对提取好的特征进行分类识别,同时使用Dropout技术防止训练过拟合,提高神经网络的泛化能力.
1 文字特征提取特征提取是印刷体汉字识别系统最为关键的环节之一.为了在得到文字的拓扑结构信息的同时又具有较好的抗噪性,本节介绍一种基于多尺度滑动窗的方式提取文字的梯度方向信息,使用尺度可伸缩的滑动窗对图像进行分割,在每个滑动窗内采用梯度直方图的方式进行表达,最后把所有滑动窗内的特征描述子按一定的权重大小联合起来形成最后的特征矢量的方法.这种特征提取方法不仅计算代价低,而且引入了空间位置信息,可以有效获取汉字的全局特征和局部分块特征.
1.1 梯度信息为了获取文字的梯度方向直方图,首先需要计算图像每个像素的梯度大小和方向,捕捉文字的大致轮廓.本文利用5×5的高斯梯度算子计算原图像梯度,并统计12个不同方向的梯度大小.图 1表示“阿”字的梯度幅值信息,通过梯度的幅值可以捕捉文字的轮廓和纹理.图 2显示了“阿”字的梯度方向分布信息,不同的颜色代表不同的梯度方向.因此,文字的梯度为汉字分类提供了一个非常有效的鉴别信息.
1.2 多尺度梯度直方图为了尽可能多地获取文字整体的轮廓纹理信息,同时提取局部的分块特征,提高对相似字的区分效果,采用多尺度滑动窗的方式提取文字梯度信息.多尺度滑动窗示意图如图 3所示,从中可见,有3种尺度大小分别为16×16,32×32,48×48的红色矩形窗,利用滑动窗提取图像不同区域的梯度信息,然后统计不同区域的梯度方向,形成梯度方向直方图,最后把不同尺度的直方图按照一定的权重比例级联起来,形成特征矢量.
 |
| 图 1 梯度幅值可视化Fig. 1 Visualization of gradient magnitudes |
 |
| 图 2 梯度方向可视化Fig. 2 Visualization of gradient directions |
 |
| 图 3 多尺度滑动窗示意图Fig. 3 Multi-scale sliding windows |
由于滑动窗在滑动的过程中以一定的步长进行移动,因此,窗与窗之间存在交叠(overlap).滑动窗之间的交叠示意图如图 4所示,从中可见,红色虚线区域部分就是由于选取的步长小于滑动窗的宽度而产生的.交叠区域的特征将会以不同结果多次出现在最后的特征向量中.这种重叠机制往往可以改善特征的性能,但同时也会增加特征的维度.
 |
| 图 4 滑动窗之间的交叠示意图Fig. 4 Overlap of the sliding windows |
神经网络是一种模拟人脑神经元细胞的网络结构,它是由大量简单的神经元相互连接成的自适应非线性动态系统.相比于传统的多层感知器,本文采用整流线性单元(Rectified Linear Units)作为网络的激活函数,用Soft-max函数作为网络的输出,并以交叉熵(Cross-entropy)衡量训练的损失.使用经典的随机梯度下降(SGD)法求解目标函数的最优解,用反向传播BP算法不断调整网络的权值.为了防止训练过拟合,使用Dropout技术,提高网络的泛化能力.
2.1 传递函数传统的人工神经网络使用Sigmoid和tanh等非线性函数作为激活函数,把神经元的输出映射在[0, 1]或[-1, 1]之间,但这些激活函数在训练时比较慢,在传递的过程中信息丢失较多,识别效果往往不太理想.本文使用一种在受限玻尔兹曼机(RBMs)模型里广泛使用的整流线性单元函数[9]:f(z)=max(z,0)作为网络的传递函数.这种激活函数能使相关的特征信息在多层网络传递过程中得到更大的保留,与传统的Sigmoid和tanh传递函数相比,计算更简单,训练更快.Sigmoid和ReLU函数如图 5所示.
 |
| 图 5 Sigmoid和ReLU函数Fig. 5 Sigmoid and ReLU functions |
相对于Logistic[10]回归,Soft-max[11]回归是解决多类分类问题的一个有效方法.对于有k类,每类有m个样本的数据集合:

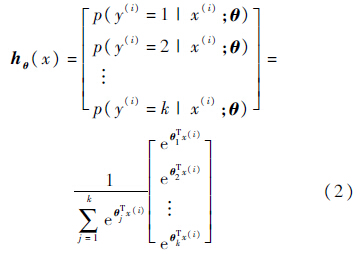
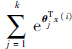 是归一化因子,使得所有概率为1.神经网络模型采用交叉熵作为目标代价函数,其形式如下:
是归一化因子,使得所有概率为1.神经网络模型采用交叉熵作为目标代价函数,其形式如下:
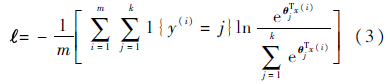
根据反向传播BP算法,将训练样本的误差从输出层反向传播到输入层,用随机梯度下降法求解目标函数的最优解,并在传播的过程中不断调整网络的权值,实现训练.
2.3 Dropout技术Dropout是Hinton教授在深度学习领域里提出来的一个重要技巧,其思想主要是在模型训练时随机让网络某些隐含层节点输出值为零,这种如同在图像中加入噪声的方式能防止模型在训练过程中出现过拟合,提高神经网络的泛化能力[12, 13, 14].对于每次输进来的样本,由于其Dropout的随机性,每个样本对应的网络结构都不相同,这些不同的网络结构同时又共享隐含节点的权值,使得不同的样本对应不同的模型.本文对输入层和所有的隐藏层都采用了Dropout.Dropout如图 6所示,从中可见,深色的神经元表示被随机选为Dropout的节点单位.
 |
| 图 6 Dropout示意图Fig. 6 Illustration of Dropout |
实验使用了一个5层的深度神经网络作为模型分类器.由于数据规模大,网络参数众多,训练过程比较缓慢,对此借用CUDAMat[15]矩阵库,使用GPU进行加速,对国标一级3755个印刷体共375500个汉字进行测试.
3.1 数 据 库
实验数据共有100套字,包含宋体、楷体、黑体、钢笔体和圆体等各种字体.每套字有3755个样本.随机选70套作为训练,10套做校正,20套做测试.“阿”字的100套不同风格的字体如图 7所示.
 |
| 图 7 “阿”字的100套字Fig. 7 One hundred fonts of “阿” |
为比较本文多尺度滑动窗梯度特征跟其他特征之间的性能差异,选用另外6种常用的特征如局部二值模式(LBP,Local Binary Pattern)[16, 17]、GIST[18]、梯度方向直方图(HOG,Histogram of Oriented Gradient)、灰度特征、梯度特征和卷积神经网络(CNN,Convolutional Neural Netuorks)自学习出来的特征进行对比评估.LBP特征不具有旋转和尺度不变性,但对于局部亮度的变化比较敏感,是一种直方图类型的纹理特征.GIST是利用不同方向和空间分辨率的Gabor滤波器对图像采样滤波的特征.HOG是一种全局特征,通过统计像素梯度方向直方图获得矢量描述.灰度特征则直接把图像的像素灰度值作为特征矢量进行输入.八方向梯度特征更多应用在文字上,把汉字点阵图像按8个方向进行分解.卷积神经网络是一种常用的特征学习方法,能从大量的底层数据中获得有效的特征表示.实验采用包含2层卷积层,2层聚合层和1层全连接层的网络结构进行特征自学习.特征对比实验数据如表 1所示.
| 特征 | 识别率/% | 时间/min |
| 灰度 | 86.266 | 47.30 |
| LBP | 87.513 | 46.64 |
| GIST | 92.754 | 57.67 |
| CNN自学习特征 | 93.368 | 462.857 |
| HOG | 94.501 | 46.19 |
| 梯度 | 95.157 | 45.35 |
| 本文梯度特征 | 98.361 | 47.04 |
由表 1看出,本文的多尺度滑动窗梯度特征效果更好.相比于一般的梯度特征,虽然也有较高的识别率95.157%,但基于多尺度的特征融合了文字更多的梯度信息,因此,其识别率更高,更有利于文字的识别分类.由于手动提取的特征其参数已经预先固定,训练过程只需微调连接层的权重,故其运行时间较快,复杂度较低.而卷积神经网络由于卷积层和聚合层的存在,在训练过程中需要不断对卷积和聚合模板的参数和权重进行调节,因此,其复杂度更高,运行时间更长.
3.3 Dropout实验下面采用本文提出的多尺度梯度特征在5层深度神经网络结构下对不同的Dropout率进行测试.为公平对比,统一对所有的输入层和隐藏层进行Dropout.实验结果如表 2所示.
| Dropout率 | 训练集识别率/% | 测试集识别率/% |
| 0 | 99.998 | 96.810 |
| 0.05 | 99.960 | 97.373 |
| 0.10 | 99.847 | 97.668 |
| 0.15 | 99.657 | 97.929 |
| 0.20 | 99.341 | 98.012 |
| 0.25 | 98.871 | 98.229 |
| 0.30 | 98.121 | 98.292 |
| 0.40 | 95.241 | 98.361 |
由表 2可知,当Dropout率为0时,训练集识别率接近100%,但测试集的识别率只有96.810%,说明此时网络在训练过程中已出现过拟合.随着Dropout率的不断增加,训练识别率逐渐降低,但测试识别率却不断上升,因此,网络的推广能力越来越强.当Dropout率为0.40时,虽然训练集的识别率只有95.241%,但此时的测试集的识别率达到最高,为98.361%.实验表明,Dropout技术在一定程度上可以防止网络出现过拟合,提高神经网络的泛化能力.
同时本文还将探究在不同的网络层上进行Dropout的效果.以下实验使用0.40作为Dropout率,数据如表 3所示.
| Dropout层 | 训练识别率/% | 测试错误率/% |
| — | 99.998 | 3.19 |
| 输入层 | 99.643 | 2.32 |
| 隐藏层 | 98.695 | 2.03 |
| 输入层+隐藏层 | 95.241 | 1.64 |
当同时对输入层和所有的隐藏层进行Dropout时,效果比仅仅在输入层或仅仅在隐藏层Dropout时要好,相比于没有Dropout的情况,系统的错误率更是下降了48.589%.为了最大限度地优化网络的泛化性能,本文将对输入层和所有的隐藏层采用Dropout.
最后为验证系统的鲁棒性,本文共做了7组试验.每组都选用不同的70套训练样本、10套校验样本和20套测试样本.
多组实验结果如表 4所示,从中可见,多组实验后系统平均识别率为98.292%,标准差几乎接近零,可见本文的印刷体识别系统有很高的准确率的同时具备很强的鲁棒性.
| 组数 | 识别率/% |
| 第1组 | 98.361 |
| 第2组 | 98.294 |
| 第3组 | 98.177 |
| 第4组 | 98.208 |
| 第5组 | 98.360 |
| 第6组 | 98.336 |
| 第7组 | 98.310 |
| 均值 | 98.292 |
| 标准差 | 0.06753 |
采用了一种基于多尺度滑动窗的方法提取文字的梯度信息,并结合深度神经网络对印刷体汉字进行分类识别.实验结果表明:
1) 本文介绍的多尺度滑动窗梯度直方图特征相比于其他特征,有更好的分类效果.
2) 同时在神经网络的输入层和隐藏层使用Dropout技术,防止了网络训练出现过拟合,增强深度神经网络的泛化性能.
3) 通过选用不同的训练集和测试集进行试验,证明本系统具有较强的鲁棒性.
今后的研究工作将从以下几个方面进行改进和提高:
1) 在特征提取上,尝试选择不同的特征参数,探究不同参数对汉字识别效果的影响,同时实现多种有效特征的融合,以提高汉字识别准确率.
2) 探究适合文字识别的深度神经网络结构,尝试利用深度学习如深度置信网络或自动编码机等方法去学习更有效的特征.
| [1] | Mori K, Masuda I.Advances in recognition of Chinese characters[C]//Proceedings of the Fifth International Conference on Pattern Recognition.Miami:IEEE Computer Society Press,1980:692-702. |
| [2] | 丁晓青. 汉字识别研究的回顾[J].电子学报,2002,30(9):1364-1368. Ding X Q.Chinese character recognition:a review[J].Journal of Acta Electronica Sinica,2002,30(9):1364-1368(in Chinese). |
| Cited By in Cnki (169) | |
| [3] | 荆涛,王仲. 光学字符识别技术与展望[J].计算机工程,2003,29(2):1-2. Jing T,Wang Z.A survey of optical character recognition[J].Computer Engineering,2003,29(2):1-2(in Chinese). |
| Cited By in Cnki (116) | Click to display the text | |
| [4] | Dalal N, Triggs B.Histograms of oriented gradients for humandetection[C]//IEEE Conference on Computer Vision and Pattern Recognition.San Diego,CA:IEEE Computer Society Press,2005:886-893. |
| Click to display the text | |
| [5] | Islam A, Hasan M R,Rahaman R,et al.Designing ANN using sensitivity & hypothesis correlation testing[C]//Computer and Information Technology.Dhaka:IEEE Computer Society Press,2007:1-6. |
| Click to display the text | |
| [6] | Soulie F F, Viennet E,Lamy B.Multi-modular neural network architectures:applications in optical character and human face recognition[J].International Journal of Pattern Recognition and Artificial Intelligence,1993,7(4):721-755. |
| Click to display the text | |
| [7] | Guyon I. Applications of neural networks to character recognition[J].International Journal of Pattern Recognition and Artificial Intelligence,1991,5(1-2):353-382. |
| Click to display the text | |
| [8] | Chang H D, Wang J F,Kuo S C.A Bayesian neural network for separating similar complex handwritten Chinese characters[J].Pattern Recognition Letters,1994,15(4):403-408. |
| Click to display the text | |
| [9] | Nair V, Hinton G E.Rectified linear units improve restricted boltzmann machines[C]//Proceedings of the 27th International Conference on Machine Learning.Haifa:International Machine Learning Society,2010:807-814. |
| Click to display the text | |
| [10] | Hosmer Jr D W, Lemeshow S.Applied logistic regression[M].Hoboken:John Wiley & Sons,2004:31-43. |
| [11] | Duan K, Keerthi S S,Chu W,et al.Multi-category classification by soft-max combination of binary classifiers[M].Berlin:Springer-Verlag Berlin Heidelberg,2003:125-134. |
| [12] | Hinton G E, Srivastava N,Krizhevsky A,et al.Improving neural networks by preventing co-adaptation of feature detectors[EB/OL].[2014-04-14].http://arxiv.org/abs/1207.0580. |
| Click to display the text | |
| [13] | Krizhevsky A, Sutskever I,Hinton G E.Image net classification with deep convolutional neural networks[J].Neural Information Processing Systems,2012,25(2):1097-1105. |
| Click to display the text | |
| [14] | Dahl G E, Sainath T N,Hinton G E.Improving deep neural networks for LVCSR using rectified linear units and dropout[C]//IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Vancouver,BC:IEEE Computer Society Press,2013:8609-8613. |
| Click to display the text | |
| [15] | Volodymyr M. Cudamat:a CUDA-based matrix class for python.Rep.UTML-TR-2009-004[R].Toronto:University of Toronto,2009. |
| Click to display the text | |
| [16] | Ojala T, Pietikäinen M,Harwood D.Performance evaluation of texturemeasures with classification based on Kullback discrimination of distributions[C]//International Conference on Pattern Recognition.Jerusalem,Israel:IEEE Computer Society Press,1994:582-585. |
| Click to display the text | |
| [17] | Ojala T, Pietikäinen M,Harwood D.A comparative study of texture measures with classification based on featured distributions[J].Pattern Recognition,1996,29(1):51-59. |
| Click to display the text | |
| [18] | Siagian C, Itti L.Gist:a mobile robotics application of context-based vision in outdoor environment[C]//Computer Vision and Pattern Recognition-Workshops.San Diego,CA:IEEE Computer Society Press,2005:88. |
| Click to display the text |